MySQL 调优
1. 并发控制
无论何时,只要有多个查询需要同时修改数据,就会产生并发控制问题。
处理并发读/写访问的系统通常实现一个由两种锁类型组成的锁系统:
- 共享锁(shared lock) ,也叫读锁(read lock) :资源上的读锁是共享的,或者说是相互不阻塞的,多个客户端可以同时读取同一个资源而互不干扰。
- 排他锁(exclusive lock) ,也叫写锁(write lock) :写锁是排他的,一个写锁既会阻塞读锁也会阻塞其他的写锁,只有这样才能保证在特定的时间点只有一个客户端能执行写入,并防止其他客户端读取正在写入的资源。
锁的粒度:
- 表锁(table lock) :锁定整张表,是 MySQL 中最基本也是开销最小的锁策略。
- 当客户端想对表进行写操作(插入、删除、更新)时,需要先获取一个写锁,这会阻塞其他客户端对该表的所有读写操作。
- 读锁之间不会相互阻塞。
- 行级锁(row lock) :锁定某一行,可以最大程度地支持并发处理,但也带来了最大的锁开销。
- 行级锁是在存储引擎而不是服务器中实现的。
如果遇到 InnoDB 并发问题,并且运行的 MySQL 版本低于 5.7,解决方案通常是升级服务器。
2. 查询性能优化
查询优化、索引优化、库表结构优化需要齐头并进,一个不落。
2.1 综述
通常来说,查询的生命周期大致可以按照如下顺序来看:
- 从客户端到服务器
- 在服务器上进行语法解析
- 生成执行计划
- 执行,并给客户端返回结果
对于 MySQL,最简单的衡量查询开销的三个指标如下:
- 响应时间:响应时间是两部分之和(然而遗憾的是,我们无法把响应时间真正细分到所谓的这些部分):
- 服务时间:指数据库处理这个查询真正花了多长时间。
- 排除时间:指服务器因为等待某些资源而没有真正执行查询的时间。比如等待 I/O 操作完成,等待行锁......
- 扫描的行数:扫描的行数与访问类型有关,如下访问类型扫描的行数从多到少,速度从慢到快
- 全表扫描
- 索引扫描
- 范围扫描
- 唯一索引扫描
- 常数引用
- 返回的行数:理想情况下扫描的行数和返回的行数应该保持相等。
一般地,MySQL 能够使用如下三种方式应用 WHERE 条件,从好到坏依次为:
- 在索引中使用
WHERE条件来过滤不匹配的记录,这是在在存储引擎层完成的。 - 使用索引覆盖扫描(在
Extra列中出现Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在 MySQL 服务器层完成的,但无须再回表查询记录。 - 从数据表中返回数据,然后过滤不满足条件的记录(在
Extra列中出现Using where)。这在 MySQL 服务器层完成,MySQL 需要先从数据表中读出记录然后过滤。
2.2 重构查询的方式
可以从下述方面来考虑重构查询的方式
一个复杂查询还是多个简单查询:要视情况而定
分而治之:有时候对于一个大查询,我们需要分而治之,进行切分查询。
比如,定期清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
将一个大的
DELETE语句切分成多个较小的查询可以尽可能小地影响 MySQL 的性能,同时还可以降低 MySQL 复制的延迟。一次性查询语句:
DELETE FROM messages WHERE created < DATE_SUB(NOW,INTERVAL 3 MONTH);可化解为下述语句:
rows_affected = 0 do { rows_affected = do_query( "DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH) LIMIT 10000" ) } while rows_affected > 0
分解联接查询
对于如下一个联接查询:
SELECT * FROM tag JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'可以分解成下面这些查询来代替:
SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);用分解联接查询的方式重构查询有如下优势:
让缓存的效率更高:许多应用程序可以方便地缓存单表查询对应的结果对象,于是......
将查询分解后,执行单个查询可以减少锁的竞争。
在应用层做,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
查询本身的效率也可能会有所提升。在这个例子中,使用
IN()代替联接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的联接要更高效。可以减少对冗余记录的访问。在应用层做联接查询,意味着对于某条记录应用只需要查询一次,而在数据库中做联接查询,则可能需要重复地访问一部分数据,会导致网络和内存的消耗。
2.3 查询执行的基础
我们再回顾一下,当向 MySQL 发送一个请求的时候,MySQL 到底做了些什么:
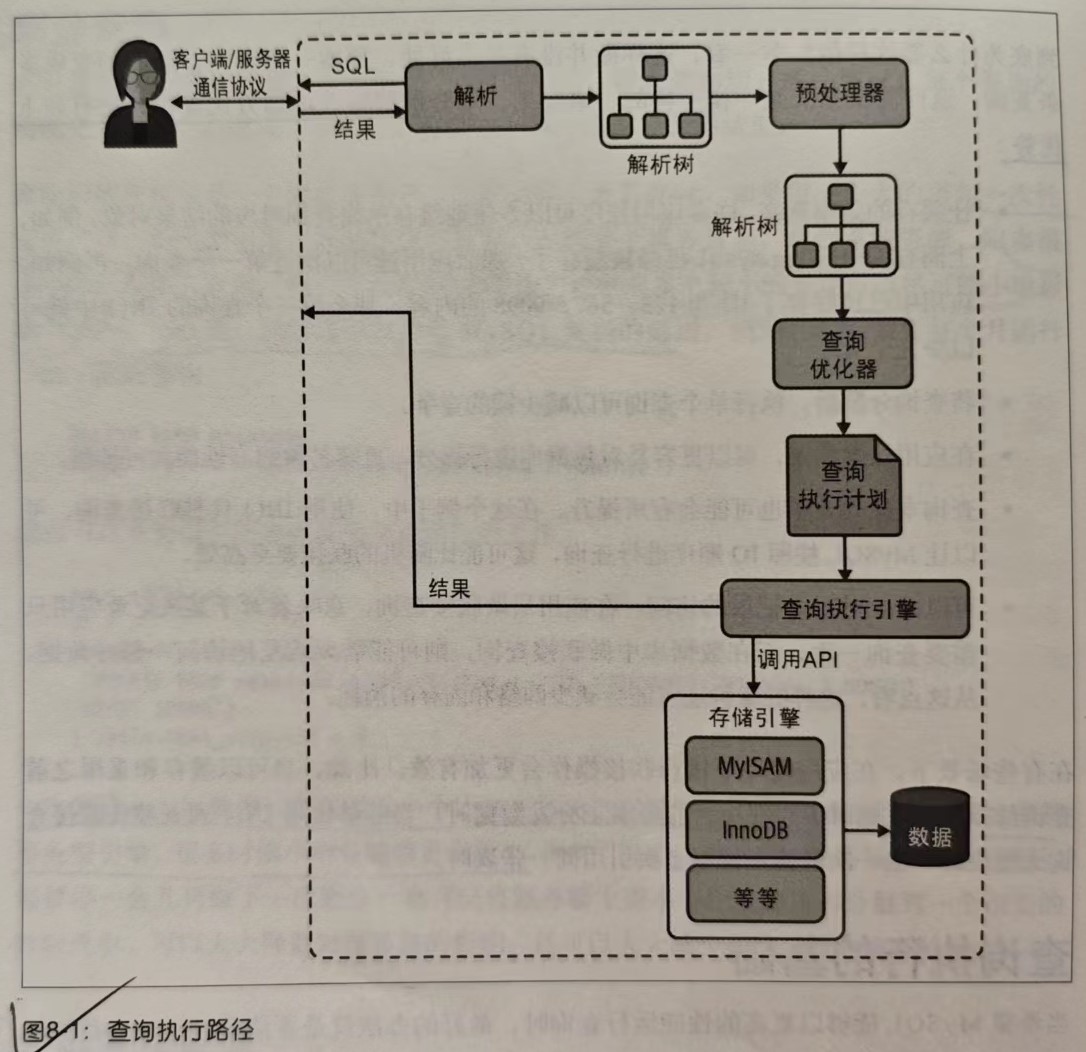
2.3.1 MySQL 的客户端/服务器信息协议
一般来说,不需要去理解 MySQL 通信协议的内部实现细节,只需要大致理解通信协议是如何工作的。
MySQL 的客户端和服务器之间的通信协议是“半双工”的,这意味着,在任何时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务器发送数据,这两个动作不能同时发生。这就像来回抛球的游戏,在任何时刻,只有一个人能控制球,而且只有控制球的人才能将球抛回去(发送消息)。
也因此,当客户端从服务器取数据时,看起来是一个拉数据的过程,但实际上是 MySQL 在向客户端推送数据的过程。
2.3.2 查询状态
对于一个 MySQL 连接,或者一个线程,任何时刻都有一个状态,该状态表示了 MySQL 当前正在做什么。
有很多种方式能查看当前的状态,最简单的是使用 SHOW FULL PROCESSLIST 命令,该命令返回结果中的 Command 列,就表示当前的状态。
| 查询状态 | 说明 |
|---|---|
Sleep | 线程正在等待客户端发送新的请求 |
Query | 线程正在执行查询或者正在将结果发送给客户端 |
Locked | 在 MySQL 服务器层,该线程正在等待表锁。在存储引擎级别实现的锁,例如 InnoDB 的行锁,并不会体现在线程状态中。 |
Analyzing and statistics | 线程正在检查存储引擎的统计信息,并优化查询 |
Copying to tmp table [on disk] | 线程正在执行查询,并且将其结果集复制到一个临时表中,这种状态一般要么是在做 GROUP BY 操作,要么是在进行文件排序操作,或者是在进行 UNION 操作 |
Sorting result | 线程正在对结果集进行排序 |
2.3.3 查询优化器
一条查询可以有很多种执行方式,最后都返回相同的结果,优化器的作用就是找到这其中最好的执行计划。
MySQL 的查询优化器是一个非常复杂的软件,它使用了很多优化策略来生成一个最优的执行计划。优化策略可以简单地分为两种,一种是静态优化,一种是动态优化。静态优化可以直接对解析树进行分析,并完成优化,而动态优化则和查询的上下文有关。
下面是一些 MySQL 能够处理的优化类型:
- 重新定义联接表的顺序
- 将外联接转化成内联接
- 使用代数等价变换规则
- 优化
COUNT(), MIN(), MAX() - 预估并转化为常数表达式
- 覆盖索引扫描
- 子查询优化
- 提前终止查询
- 等值传播
- 列表
IN()的比较
2.3.4 优化特定类型的查询
优化
COUNT()查询:COUNT()是一个特殊的函数,有两种非常不同的作用:- 统计某列的值的数量:此时要求列值是非空的,即不统计
NULL。如果在函数括号中指定了列或者列的表达式,则对应的就是这种作用,比如,COUNT(col_name) - 统计行数:当 MySQL 确认括号内的表达值不可能为空时,实际上就是在统计行数。比如,
COUNT(*)并不会像我们第一反应所猜想的那样扩展成所有的列,而是会忽略所有的列而直接统计所有的行数。
- 统计某列的值的数量:此时要求列值是非空的,即不统计
优化
LIMIT与OFFSET子句:优化此类分页查询的一个最简单的办法就是尽可能地使用索引覆盖扫描,而不是查询所有的行,然后根据需要做一次联接操作再返回所需的列。对于下面的查询:
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;如果这个表非常大,那么其最好改写成下面的样子:
SELECT film.film_id, film.description FROM sakila.film INNER JOIN ( SELECT film_id FROM sakila.film ORDER BY title LIMIT 50, 5 ) AS lim USING(film_id);
优化
UNION查询:MySQL 总是通过创建并填充临时表的方式来执行UNION查询,因此很多优化策略在UNION查询中都没法很好地被使用。- 经常需要手工地将
WHERE, LIMIT, ORDER BY等子句“下推”到UNION的各个子查询中,以便优化器可以充分利用这些条件进行优化。 - 除非你确实需要服务器消除重复的行,否则一定要使用
UNION ALL,这一点很重要。
- 经常需要手工地将
更新日志
8d749-于899db-于eedbf-于c9215-于e931e-于0d967-于75141-于730b3-于eeecd-于