自动补全
2022/1/1大约 2 分钟约 596 字
所谓自动补全,即当用户在搜索框输入字符时,提示出与该字符有关的搜索项。如:
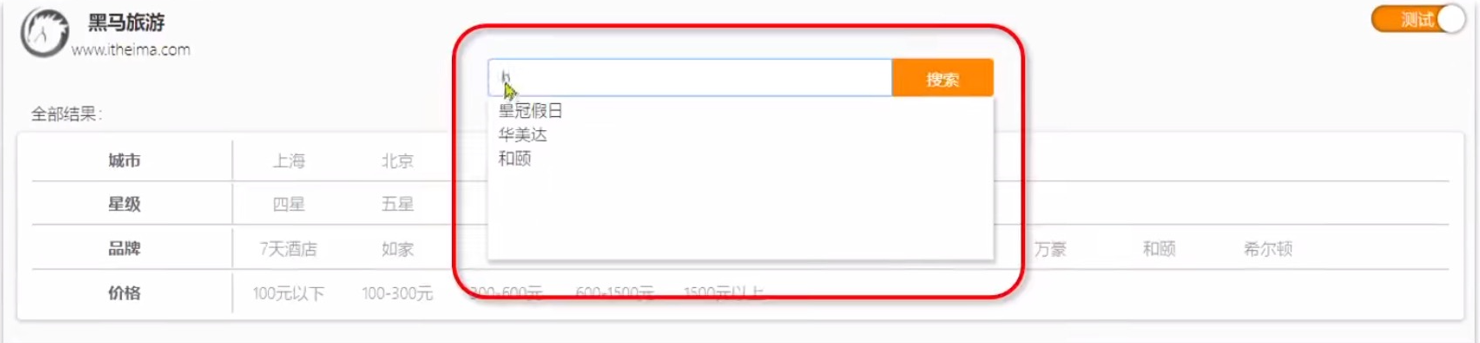
1. 拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在 Github 上有 ES 的 拼音分词插件。
2. 自定义分词器
ES 中分词器的组成包含三部分:

- character filters:在 tokenizer 之前对文本进行处理。例如删除字符、替换字符。
- tokenizer:将文本按照一定的规则切割成词条(term)。例如 keyword 就是不分词,还有 ik_smart
- tokenizer filter:将 tokenizer 输出的词条做进一步处理。例如大小写转换、同义词转换、拼音处理等。
在创建索引库时,通过 settings 来配置自定义的 analyzer(分词器):

拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用——避免搜索到同音字:
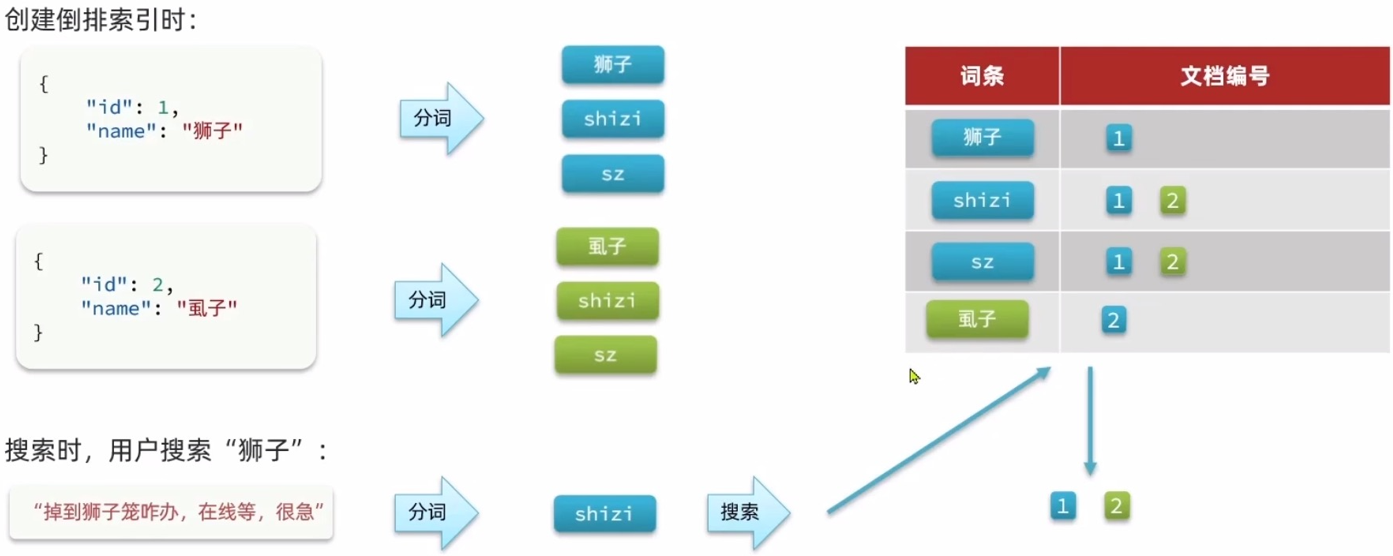
因此字段在创建倒排索引时应该用 my_analyzer 分词器,在搜索时应该使用 ik_smart 分词器:

3. 自动补全查询
ES 提供了 Completion Suggester 查询来实现自动补全功能,这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是 completion 类型
- 字段的内容一般是用来补全的多个词条形成的数组

查询语法如下:
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前 10 条结果
}
}
}
}4. RestAPI 实现自动补全
请求参数构造的 API:
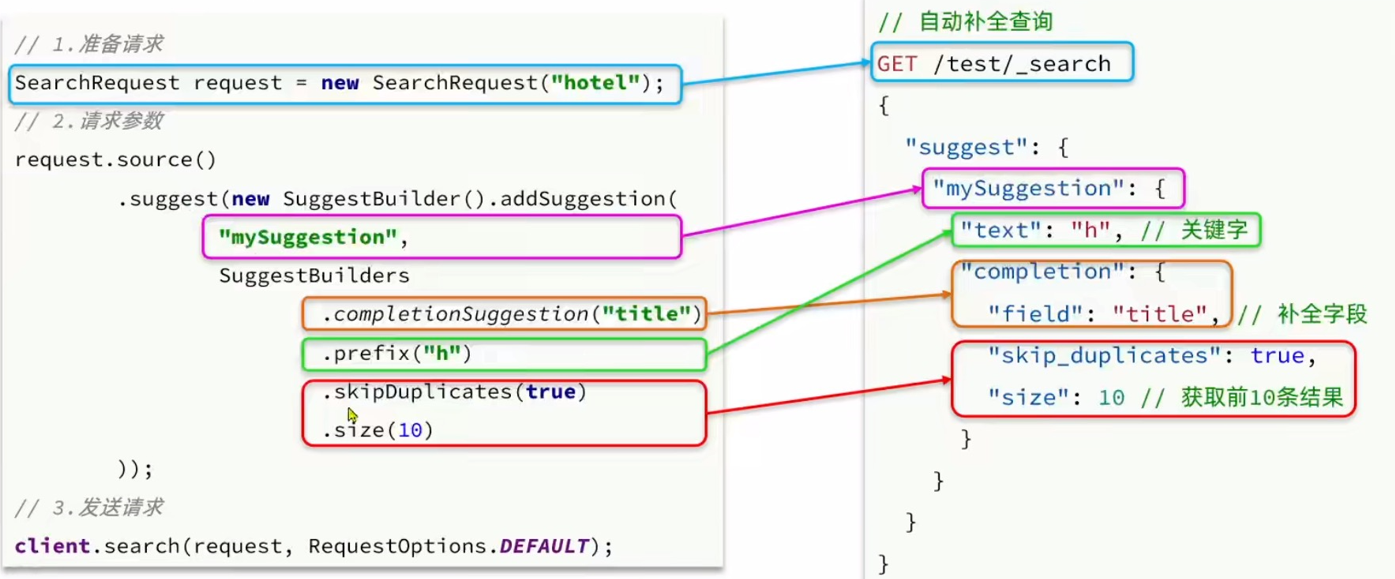
结果解析的 API:

更新日志
2024/5/5 13:38
查看所有更新日志
8d749-于899db-于eedbf-于c9215-于75141-于730b3-于0e6a3-于16585-于3f9a4-于3bce6-于dda97-于