数据类型
Redis 常用的五种数据类型:
- string:字符串
- list:列表
- hash:哈希(字典)
- set:集合
- zset:sorted set,有序集合
1. string
string 是 Redis 最基本的数据类型,一个字符串类型的值最多能够存储 512 MB 的内容。
字符串是一组字节,在 Redis 数据库中,字符串是二进制安全的,这意味着 redis 的 string 可以包含任何数据,比如 jpg 图片或者序列化的对象。
二进制安全:是一种主要用于字符串操作函数的计算机编程术语。只关心二进制化的字符串,不关心具体的字符串格式,严格的按照二进制的数据存取。这保证字符串不会因为某些操作而遭到损坏。
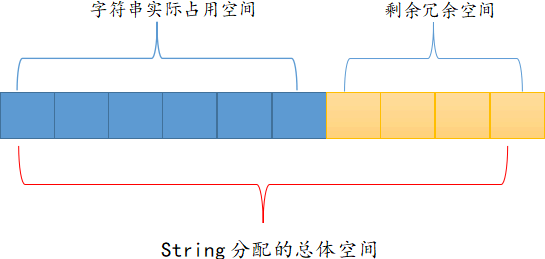
String 的数据结构为 SDS(Simple Dynamic String,简单动态字符串),是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如下图所示。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间,注意 Redis 字符串允许的最大值字节数是 512 MB。
2. list
Redis 的 list 中的元素是字符串类型,其中的元素按照插入顺序进行排列,允许重复插入,最多可插入的元素个数为 个(大约 40 亿个).
在向 list 中添加元素时,可以且仅可以添加到列表的头部或者尾部。
Redis 列表的底层存储结构,其实是一个被称为快速链表(quicklist)的结构。当列表中存储的元素较少时,Redis 会使用一块连续的内存来存储这些元素,这个连续的结构被称为 压缩列表(ziplist),它将所有的元素紧挨着一起存储。
压缩列表是 Redis 为节省内存而开发的,它是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表了可以包含任意多个节点,每个节点都可以保存一个字符数组或者整数值。而当数据量较大时,Redis 列表就会用快速链表存储元素。
Redis 之所以采用两种方法相结合的方式来存储元素。这是因为单独使用普通链表存储元素时,所需的空间较大,会造成存储空间的浪费。因此采用了链表和压缩列表相结合的方式,也就是 quicklist + ziplist,结构如下图:

由于底层是个双向链表,Redis 的 list 对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
3. hash
hash 散列是由字符串类型的 field 和 value 组成的映射表,可以把它理解成一个包含了多个键值对的集合,hash 类型一般被用来存储对象。
一个 hash 中最多包含 个键值对。
hash 类型底层存储结构对应两种实现方式:
第一种,当存储的数据量较少的时,hash 采用 ziplist 作为底层存储结构,此时要求符合以下两个条件:
- 哈希对象保存的所有键值对(键和值)的字符串长度总和小于 64 个字节
- 哈希对象保存的键值对数量要小于 512 个
第二种,当无法满足上述条件时,hash 采用 dict(字典结构)来存储数据,该结构类似于 Java 的 HashMap,是一个无序的字典,并采用了数组和链表相结合的方式存储数据。
在 Redis 中,dict 是基于哈希表算法实现的,因此其查找性能非常高效,其时间复杂度为 O(1)。
下面使用 HMSET 命令来存储一个包含了用户基本信息的对象,如下所示:
127.0.0.1:6379> HMSET userid:1 username xiaoming password 123456 website www.biancheng.net
OK
127.0.0.1:6379> HGETALL userid:1
1) "username"
2) "xiaoming"
3) "password"
4) "123456"
5) "website"
6) "www.biancheng.net"4. set
Redis 的 set 是一个字符串类型元素构成的无序集合。集合的同样可容纳 个元素。
Redis set 采用了两种方式相结合的底层存储结构,分别是 intset(整型数组)与 hash table(哈希表),当 set 存储的数据满足以下要求时,使用 intset 结构:
- 集合内保存的所有成员都是整数值;
- 集合内保存的成员数量不超过 512 个。
当不满足上述要求时,则使用 hash table 结构。
5. zset
Redis 的 zset 是一个字符串类型元素构成的有序集合,集合中的元素不仅具有唯一性,而且每个元素还会关联一个 double 类型的权重分数(该分数允许重复),Redis 通过这个分数来为集合中的成员排序。
zset 底层使用了两个数据结构
- hash:hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。
- 跳跃表:跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表。
6. bitmap
在平时开发过程中,经常会有一些 bool 类型数据需要存取。比如记录用户一年内签到的次数,签了是 1,没签是 0。如果使用 key-value 来存储,那么每个用户都要记录 365 次,当用户成百上亿时,需要的存储空间将非常巨大。为了解决这个问题,Redis 提供了位图(bitmap)结构。
位图同样属于 string 数据类型。Redis 中一个字符串类型的值最多能存储 512 MB 的内容,每个字符串由多个字节组成,每个字节又由 8 个 Bit 位组成。位图结构正是使用“位”来实现存储的,它通过将比特位设置为 0 或 1 来达到数据存取的目的,这大大增加了 value 存储数量,它存储上限为 。
Redis 的位数组是自动扩展的,如果设置了某个偏移位置超出了现有的内容范围,位数组就会自动扩充。
位图本质上就是一个普通的字节串,也就是 bytes 数组。Redis 使用getbit/setbit命令来处理这个位数组,位图的结构如下所示:

位图适用于一些特定的应用场景,比如用户签到次数、或者登录次数等。上图是表示一位用户 10 天内来网站的签到次数,1 代表签到,0 代表未签到,这样可以很轻松地统计出用户的活跃程度。相比于直接使用字符串而言,位图中的每一条记录仅占用一个 bit 位,从而大大降低了内存空间使用率。
Redis 官方也做了一个实验,他们模拟了一个拥有 1 亿 2 千 8 百万用户的系统,然后使用 Redis 的位图来统计“日均用户数量”,最终所用时间的约为 50ms,且仅仅占用 16 MB 内存。
7. HyperLogLog
HyperLogLog 使用起来较为方便,但是其内部原理较为复杂,建议先不深入研究,会用即可。
在 Redis 2.8.9 版本中新增了 HyperLogLog 类型,它非常适用于海量数据的计算、统计,其特点是占用空间小,计算速度快。
HyperLoglog 采用了一种基数估计算法,因此,最终得到的结果会存在一定范围的误差(标准误差为 0.81%)。每个 HyperLogLog key 只占用 12 KB 内存,所以理论上可以存储大约 个值,而 set(集合)则是元素越多占用的内存就越多,两者形成了鲜明的对比 。
7.1 基数定义
基数定义:一个集合中不重复的元素个数就表示该集合的基数,比如集合 {1,2,3,1,2} ,它的不重复元素集合为 {1,2,3} ,所以基数为 3。HyperLogLog 正是通过基数估计算法来统计输入元素的基数。
HyperLogLog 不会储存元素值本身,因此,它不能像 set 那样,可以返回具体的元素值。HyperLogLog 只记录元素的数量,并使用基数估计算法,快速地计算出集合的基数是多少。
7.2 场景应用
HyperLogLog 也有一些特定的使用场景,它最典型的应用场景就是统计网站用户月活量,或者网站页面的 UV(网站独立访客)数据等。
UV 与 PV(页面浏览量) 不同,UV 需要去重,同一个用户一天之内的多次访问只能计数一次。这就要求用户的每一次访问都要带上自身的用户 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
当一个网站拥有巨大的用户访问量时,我们可以使用 Redis 的 HyperLogLog 来统计网站的 UV (网站独立访客)数据,它提供的去重计数方案,虽说不精确,但 0.81% 的误差足以满足 UV 统计的需求。
8. geospatial
对地理位置的支持,没啥好说的,详看 redis 命令相关的描述吧。
更新日志
0b273-于8d749-于899db-于eedbf-于c9215-于75141-于730b3-于21f41-于3f7a3-于89299-于