JavaIO流设计模型
Java 把所有设备里的有序数据抽象成流模型,简化了输入/输出处理。
1. 流的概念
Java 把不同的输入/输出源(键盘、文件、网络连接等)抽象表述为流(stream) ,通过流的方式允许 Java 程序使用相同的方式来访问不同的输入/输出源。流即是从起源(source)到接收(sink)的有序数据。
流的基本概念模型把设备抽象成一个“水管”:
输入流:输入流使用隐式的记录指针来表示当前正准备从哪个“水滴”开始读取,每当程序从输入流中取出一个或多个“水滴”后,记录指针自动向后移动。
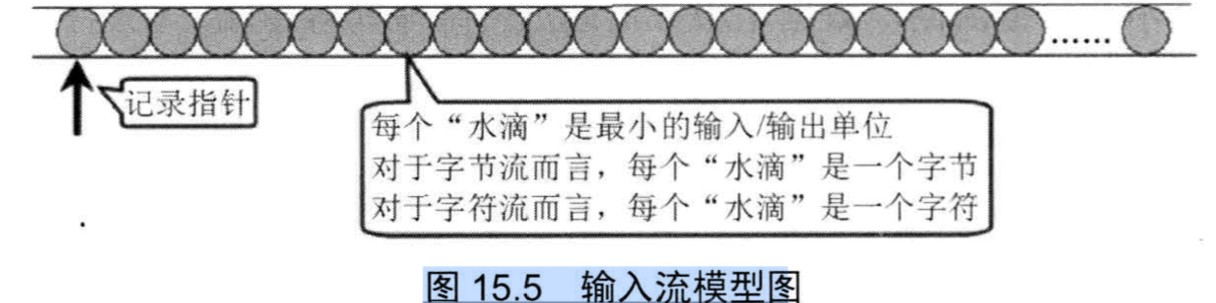
输出流:输出流同样采样隐式的记录指针来标识当前水滴即将放入的位置,每当程序向输出流里输出一个或多个水滴后,记录指针自动向后移动。

2. Java IO 流模型
2.1 IO 流的分类
Java 的 IO 通过 java.io 包下的类和接口来支持(有大概80个类)。IO 流可以按照多种分类方式进行划分:
- 按照流向划分:
- 输入流:只能从中读取数据,不能向其写入数据。包含
InputStream和Reader体系。 - 输出流:只能向其写入数据,不能从中读取数据。包含
OutputStream和Writer体系。
- 输入流:只能从中读取数据,不能向其写入数据。包含
- 按照操作的数据单元划分:
- 字节流:以字节(8 bit)为单位。包含
InputStream和OutputStream体系。 - 字符流:以字符(16 bit)为单位。包含
Reader和Writer体系。
- 字节流:以字节(8 bit)为单位。包含
- 按照作用层级划分(使用了装饰器设计模式):
- (底层)节点流:用于和底层的物理存储节点直接关联。可以从/向一个特定的 IO 设备读/写数据的流,程序直接连接到实际的数据源。也被称作低级流。
- (上层)处理流:对一个已存在的流进行连接或封装,通过封装后的流来实现数据读/写功能。也被称作高级流/包装流。
Java7 在 java.nio 及其子包下提供了一系列全新的API,这些API是对原有新IO的升级,因此也被称为 NIO2,通过 NIO2 程序可以更高效地进行输入、输出操作。
2.2 IO 操作的分类
对于 IO 操作,可分成两步:
- 程序发出 IO 请求。由此可将 IO 操作划分为阻塞IO/非阻塞IO:
- 阻塞IO:发出IO请求会阻塞线程。
- 非阻塞IO:发出IO请求不会阻塞线程。
- 完成实际的 IO 操作。由此可将IO操作划分为同步IO/异步IO:
- 同步IO:指实际的 IO 需要程序本身去执行,意味着会阻塞线程,故而是同步IO;
- 异步IO:指实际的 IO 操作由操作系统完成,再将结果返回给应用程序,故而是异步IO。
2.3 处理流模型
Java 的处理流模型则体现了 Java 输入/输出流设计的灵活性,处理流的功能主要体现在:
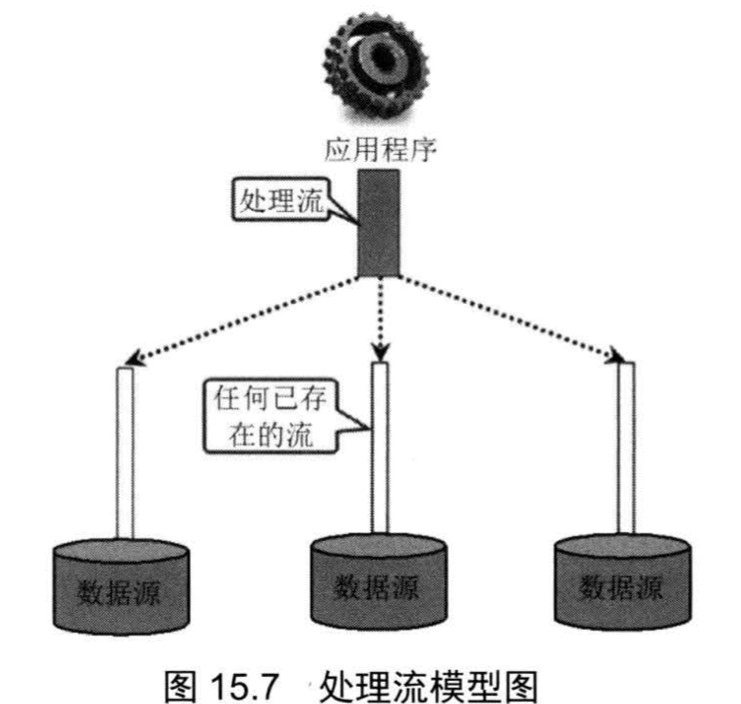
- 性能的提高:主要以增加缓冲的方式来提高输入/输出的效率;
- 操作的便捷:处理流可能提供了一系列便捷的方法来一次输入/输出大批量的内容,而不是输入/输出一个或多个“水滴”。
使用处理流时,先用处理流来包装节点流,然后程序通过处理流来执行输入/输出功能,让节点流与底层的I/O设备、文件交互。
class PrintStreamTest {
public static void main(String[] args) {
try (
FileOutputStream fos = new FileOutputStream("test.txt");
PrintStream ps = new PrintStream(fos);
) {
ps.println("hello, world");
ps.println(new PrintStreamTest());
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}3. Java IO 流的类体系
Java 的 IO 流共涉及40多个类,它们都是从4个抽象基类派生的:
| 抽象基类 | 说明 |
|---|---|
InputStream/Reader | 所有输入流的基类,前者是字节输入流,后者是字符输入流 |
OutputStream/Writer | 所有输出流的基类,前者是字节输出流,后者是字符输出流 |
3.1 输入流的方法
InputStream独有方法:方法 说明 int read()从输入流中读取单个字节,返回所读取的字节数据 int read(byte[] b)从输入流中最多读取 b.length个字节,并将其存储在字节数组b中,返回实际读取的字节数int read(byte[] b, int off, int len)从输入流中最多读取 len个字节,并将其存储在字节数组b中,放入数组b中时,从off位置开始,返回实际读取的字节数Reader独有方法:方法 说明 int read()从输入流中读取单个字符,返回所读取的字符数据 int read(char[] cbuf)… int read(char[] cbuf, int off, int len)… InputStream/Reader公共方法:方法 说明 void mark(int readAheadLimit)在记录指针当前位置记录一个标记 boolean markSupported()判断此输入流是否支持 mark()操作void reset()将此流的记录指针重新定位到上一次记录标记(mark)的位置 long skip(long n)记录指针向前移动 n个字节/字符
3.2 输出流的方法
OutputStream/Writer的相似方法:方法 说明 void write(int c)将指定的字节/字符输出到输出流中 void write(byte[]/char[] buf)将字节数组/字符数组中的数据输出到指定输出流中 void write(byte[]/char[] buf, int off, int len)将字节数组/字符数组中从 off位置开始,长度为len的字节/字符输出到输出流中Writer的特殊方法:因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组。方法 说明 void write(String str)将 str字符串里包含的字符输出到指定输出流中void write(String str, int off, int len)将 str字符串里从off位置开始,长度为len的字符输出到指定输出流中
3.3 close()方法
InputStream和OutputStream都提供了close()方法关闭输出流,以便释放系统资源。但是要特别注意的是,OutputStream还提供了一个flush()方法,它的目的是将缓冲区的内容真正输出到目的地。
为什么要有flush()?因为向磁盘、网络写入数据的时候,出于效率的考虑,操作系统并不是输出一个字节就立刻写入到文件或者发送到网络,而是把输出的字节先放到内存的一个缓冲区里(本质上就是一个byte[]数组),等到缓冲区写满了,再一次性写入文件或者网络。对于很多IO设备来说,一次写一个字节和一次写1000个字节,花费的时间几乎是完全一样的,所以OutputStream有个flush()方法,能强制把缓冲区内容输出。
通常情况下,我们不需要调用这个flush()方法,因为缓冲区写满了OutputStream会自动调用它,并且,在调用close()方法关闭OutputStream之前,也会自动调用flush()方法。
因此,使用 Java 的 IO 流执行输出时,不要忘记执行close()方法关闭输出流,关闭输出流除可以保证流的物理资源被回收之外,可能还可以将输出流缓冲区中的数据 flush 到物理节点里。
不过,在某些情况下,我们仍然必须手动调用flush()方法。例如:
小明正在开发一款在线聊天软件,当用户输入一句话后,就通过
OutputStream的write()方法写入网络流。小明测试的时候发现,发送方输入后,接收方根本收不到任何信息,怎么肥四?原因就在于写入网络流是先写入内存缓冲区,等缓冲区满了才会一次性发送到网络。如果缓冲区大小是4K,则发送方要敲几千个字符后,操作系统才会把缓冲区的内容发送出去,这个时候,接收方会一次性收到大量消息。
解决办法就是每输入一句话后,立刻调用
flush(),不管当前缓冲区是否已满,强迫操作系统把缓冲区的内容立刻发送出去。
实际上,InputStream也有缓冲区。例如,从FileInputStream读取一个字节时,操作系统往往会一次性读取若干字节到缓冲区,并维护一个指针指向未读的缓冲区。然后,每次我们调用int read()读取下一个字节时,可以直接返回缓冲区的下一个字节,避免每次读一个字节都导致IO操作。当缓冲区全部读完后继续调用read(),则会触发操作系统的下一次读取并再次填满缓冲区。
在使用处理流包装了底层节点流之后,关闭输入/输出流资源时,只要关闭最上层的处理流即可,系统会自动关闭被该处理流包装的节点流。
4. 常用类详述
通常来讲,字节流的功能比字符流的功能强大,因为计算机里所有的数据都是二进制的,而字节流可以处理所有的二进制文件。但问题是,如果使用字节流来处理文本文件,则需要使用合适的方式把这些字节转换成字符,这就增加了编程的复杂度。
一般规则:如果进行输入/输出的内容是文本内容,应该考虑使用字符流;如果进行输入/输出的内容是二进制内容,应该考虑使用字节流。
4.1 标准输入/输出流
Java使用System.in和System.out来代表标准输入/输出,即键盘输入/显示器。
System.in:标准输入流,InputStream类型,这个流是已经打开了的,默认状态对应于键盘输入;System.out:标准输出流,PrintStream类型,默认状态对应于屏幕输出;System.err:标准错误信息输出流,PrintStream类型,默认状态对应于屏幕输出。
在System类里提供了如下三个重定向标准输入/输出的方法:
| 方法 | 作用 |
|---|---|
static void setIn(InputStream in) | 重定向标准输入流 |
static void setOut(PrintStream out) | 重定向标准输出流 |
static void setErr(PrintStream err) | 重定向标准错误输出流 |
示例——一个方便的 API 把文本转换成基本类型或者String:
Scanner scanner = new Scanner(System.in);
int num = scanner.nextInt();
// Scanner还有如下方法:
// nextByte()
// nextDouble()
// nextFloat()
// nextInt()
// nextInt()
// nextLong()
// nextShort()4.2 推回输入流:PushbackInputStream/PushbackReader
两个推回输入流提供了三个方法:
| 方法 | 作用 |
|---|---|
void unread(int b) | 将一个字节/字符推回到推回缓冲区里,从而允许重复读取刚刚读取的内容 |
void unread(byte[]/char[] buf) | 将一个字节/字符数组内容推回到推回缓冲区里,从而允许重复读取刚刚读取的内容 |
void unread(byte[]/char[] b, int off, int len) | 将一个字节/字符数组里从off开始,长度为len字节/字符的内容推回到推回缓冲区里,从而允许重复读取刚刚读取的内容 |
两个推回输入流都带有一个推回缓冲区,当程序调用它们的unread()方法时,系统将会把指定数组的内容推回到该缓冲区里,而推回输入流每次调用read()方法时总是先从推回缓冲区读取,只有完全读取了推回缓冲区的内容,且还没有装满read()所需的数组时才会从原输入流中读取。
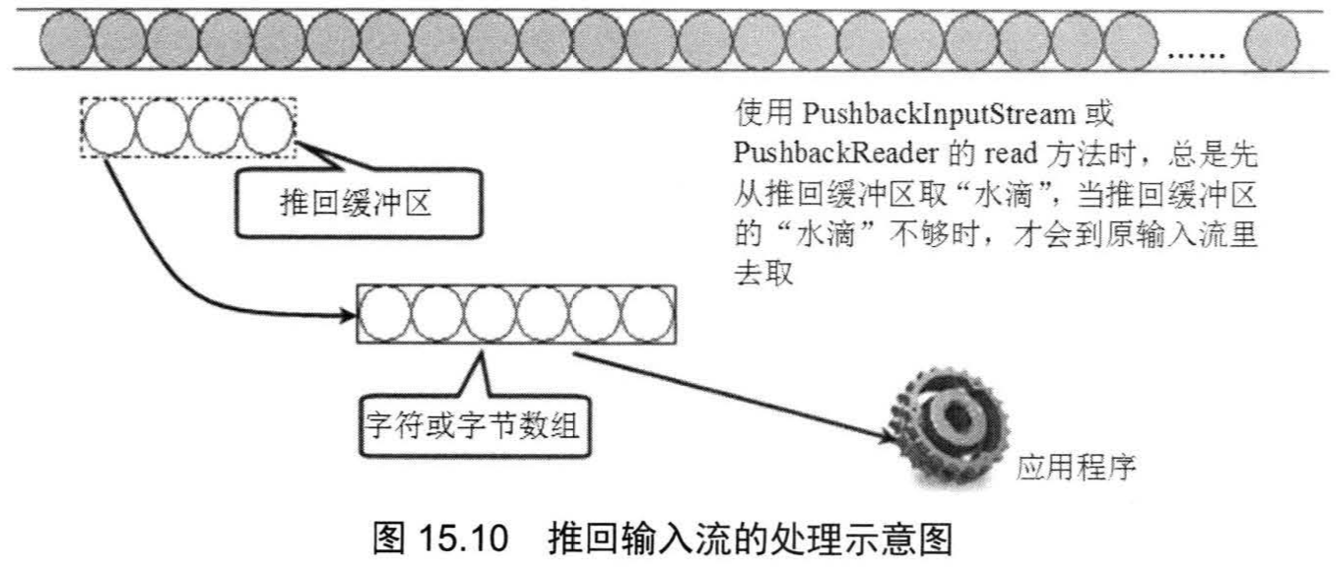
据上,当程序创建一个PushbackInputStream或PushbackReader时需要指定推回缓冲区的大小,默认的推回缓冲区的长度为1。如果程序中推回到推回缓冲区的内容超出了推回缓冲区的大小,将引发Pushback buffer overflow的IOException异常。
更新日志
9c3dd-于899db-于eedbf-于c9215-于75141-于730b3-于0e6a3-于90caa-于16be2-于83bde-于016df-于