前后端交互
1. 跨域问题
在 Web 浏览器中,源(origin)是指 源 = 协议+域名+端口,可通过 js 的 window.origin 来获取,例如,在我的笔记静态网站中通过浏览器控制台执行该命令得到的结果是:
> window.origin
'http://localhost:7777'如果两个 url 的 协议名、域名、端口号完全一致,则称他们同源。
同源策略是指在 Web 浏览器规定,如果 js 运行在源 A 中,那么就只能获得源 A 中的数据,不能获得源 B 中的数据,即不允许跨域。同源策略可防止某个网页上的恶意脚本通过该页面的文档对象模型访问另一网页上的敏感数据。
下表列出一些与 URL http://www.example.com/dir/page.html 是否属于同源的 URL 例子:
| URL | 是否同源 | 原因 |
|---|---|---|
| http://www.example.com/dir/page2.html | 是 | 只有路径不同 |
| http://www.example.com/dir2/other.html | 是 | 只有路径不同 |
| http://username:password@www.example.com/dir2/other.html | 是 | 只有路径不同 |
| http://www.example.com:81/dir/other.html | 否 | 不同端口(若未标明,http:// 默认端口号为 80) |
| https://www.example.com/dir/other.html | 否 | 不同协议(https 和 http) |
| http://en.example.com/dir/other.html | 否 | 不同域名 |
| http://example.com/dir/other.html | 否 | 不同域名(需要完全匹配) |
| http://v2.www.example.com/dir/other.html | 否 | 不同域名(需要完全匹配) |
同源策略对 Web 应用程序具有特殊意义,因为 Web 应用程序广泛依赖于 HTTP cookie 来维持用户会话,所以必须将不相关网站严格分隔,以防止数据泄露。
值得注意的是,同源策略仅针对脚本,这意味着某网站可以通过相应的 HTML 标签访问不同来源网站上的图像、CSS 和动态加载脚本等资源。而跨站请求伪造就是利用同源策略不适用于 HTML 标签的缺陷。
跨域的解决方案(分为前端和后端):
- 跨源资源共享(cross-origin resource sharing,CORS)定义了一种方式,为的是浏览器和服务器之间能互相确认是否足够安全以至于能使用跨源请求。相比纯粹的同源请求,CORS 更为自由和功能强大,同时比纯粹的跨域请求更为安全。跨域资源共享是一份浏览器技术的规范,提供了 Web 服务从不同网域传来沙盒脚本的方法,以避开浏览器的同源策略。
- ......
2. HTTP 反向代理
参考 肖国栋的 i 自留地。
要理解什么是 反向代理(reverse proxy) ,自然你得先知道什么是 正向代理(forward proxy) 。
另外需要说的是, 一般提到反向代理, 通常是指 HTTP 反向代理, 但反向代理的范围可以更大, 比如 tcp 反向代理,本文不讨论 HTTP 反向代理之外的东西。
所谓正向代理
正向代理通常直接称为代理(proxy) ,无需强调它是正向的,在 HTTP 协议中,代理即指正向代理。
而要谈论什么是正向代理,则需要先讨论"直接访问"的形式,即没有任何代理的模式。事实上, 直接访问对于很多的小网站来说是最常见的方式,直接访问类似于"厂家直销"—— 你直接向生产厂家下单, 没有经过任何的中间商。从系统的角度看, "直接访问"就是浏览器的请求直接到了最终生成网页的服务器, 中间没有经过任何的 HTTP 代理服务器。
对于浏览器的请求处理来说,一个(正向)代理,更确切的说一台代理服务器,其并没有直接响应请求的能力,它不过是把请求转发到最终的网页服务器上,再把后者的响应再转发回请求者,也就是浏览器。 如下图所示:
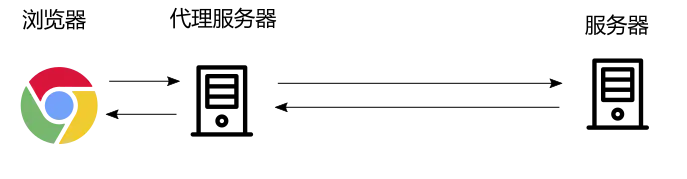
但这里还有个问题——浏览器怎么知道代理服务器在哪?最终的服务器浏览器是知道的,比如对于域名 "baidu.com",通过 DNS 浏览器能查到对应的 ip 地址,但浏览器怎么知道哪里有代理服务器,以及请求是否要经过代理服务器呢?
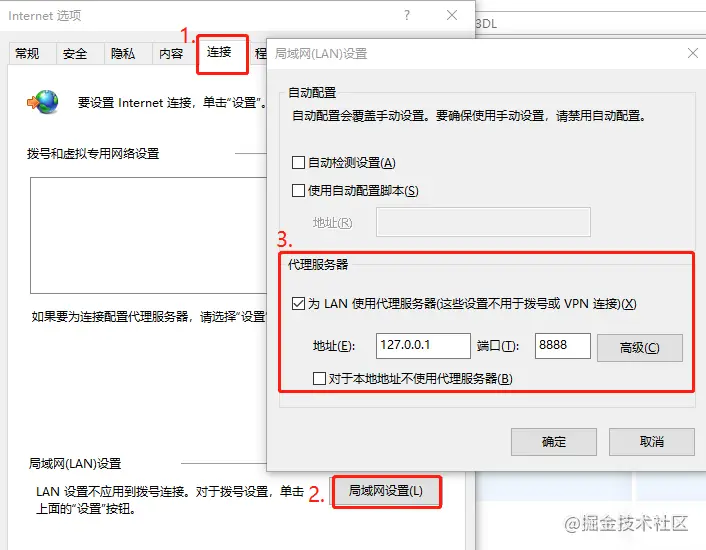
答案是必须主动告诉浏览器,这个过程通常称为“配置代理服务器”,如在 IE 浏览器上配置代理服务器的操作如下:
为什么有代理存在?
一是出于安全审计及控制方面的一些考虑。在一些组织内,web 相关的端口如 80 及 443 是被封禁的,在组织内上不了网,如果这时有上网的需求,就只能使用组织指定的内网的代理服务器了。
当然了,代理服务器本身则没有被限制,它是可以访问外部的网络的。
如此一来, 你的所有上网请求都要经过代理服务器, 而这个代理是由组织控制的, 就可以对请求进行审计了:
- 比如发现你往外面的一个网站上传组织内部的保密资料, 就出手阻止你;
- 又或发现你访问了一个不安全的网站, 可能会导致你的电脑中毒, 于是出手拦截了;
- 又或者是发现你在访问与工作无关的娱乐网站, 于是就给你阻断了。
二是有时出于加速或节省带宽等的考虑,因为有的代理服务器它不仅能转发,还能对网页以及其它一些资源进行缓存。举个例子,假如现在很多同学都要去上 qq.com 的主页,那么第一个同学请求时,代理服务器就可以把主页缓存起来一段时间,碰到后面还要同学想访问这个主页,就无需再去请求了,代理服务器直接返回缓存的请求。
自然,缓存也会有一个失效期,不会一直缓存下去,否则内容就得不到更新了。至于多长时间更新缓存,怎么更新等这些就属于具体的缓存策略问题了。
值得一提的是,现在很多网页主页都有个性化推荐,又或者直接就是要登录的,那通常就无法缓存了,所以现在配置代理服务器的行为现在也不那么时兴了,当然一个原因也可能是现在带宽也提高了。不过另一方面,很多静态资源还是可以缓存的,比如图片、js、css 之类的文件,所以用好了代理服务器依然还是可以发挥作用的。
反向代理
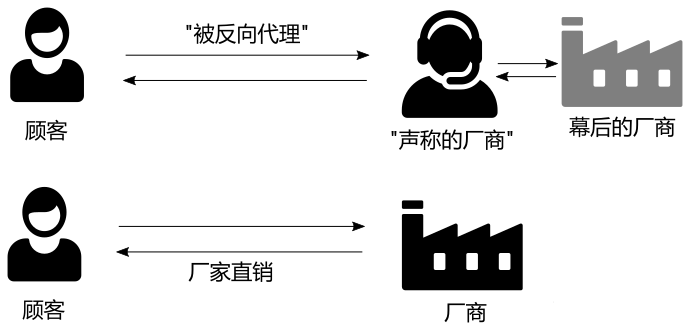
反向代理与正向代理的一个很大区别就是,它不需要客户端(浏览器)去做什么配置,并没有什么配置代理服务器的操作。 如果说正向代理是主动配置,主动走代理,那么反向代理则是被代理,从这点上看,反向代理有时又称为透明代理,也即是浏览器都不知道自己被代理了,浏览器以为发给它响应的就是最终的网页服务器,而其实不过是个代理。
类似于:
访问一些网站时,比如 chua-n.com,可以发现响应这个访问请求的是一台 Nginx server,如下图所示:
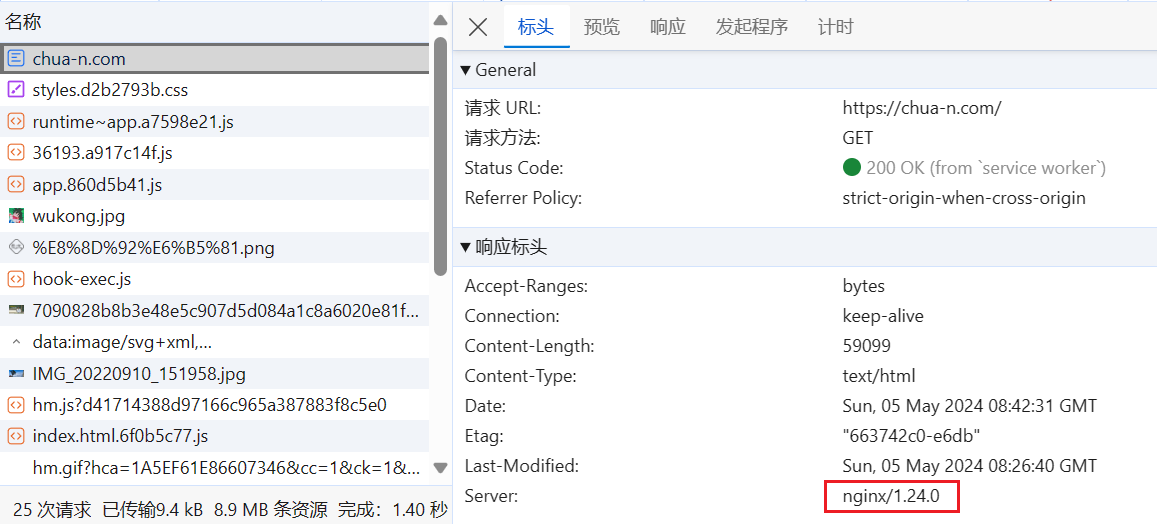
问题在于 Nginx 并非最终生成这个网页的 server ,如果你了解 Nginx,就会知道它通常只是一个静态资源服务器,而相应的网页是一个动态生成的内容,从 Nginx 那里取得最终响应的内容,并再次转发给浏览器,整个情形如下:
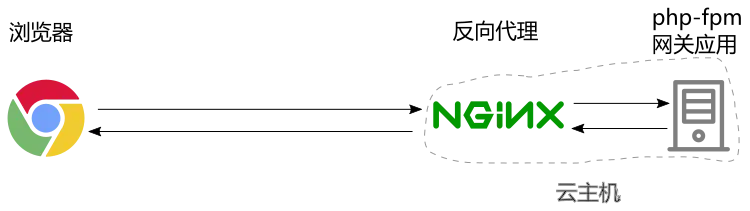
这是内部配置的一个情况:
location ~ \.php$ {
root /ftp/wwwroot;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name;
include fastcgi_params;
}请求被转发到内部一个在 9000 端口上监听的 php 应用服务器。从外部浏览器的角度看,请求直接发给了 Nginx server,响应也从 Nginx server 里回来了,中间没有任何的(正向)代理。至于说你内部请求又被怎么转发了,显然浏览器既无从知道也不需要知道。
在整个体系里面,Nginx 的角色就是一个反向代理服务器,浏览器被代理了,但它无从知道自己是否被代理了,这一切对它而言是透明的,反正它自己是没有主动走代理的。
值得额外一提的是,通过上述你已经知道了该网站内部的配置,此时如果直接访问 chua-n.com:9000,那便是真正的“直接访问”了,就绕过了 Nginx。不过嘛,通过而言直接访问是访问不通的,因为 9000 端口并没有对外放开,只是在内部可以访问。
为什么要使用反向代理?
一个很直接的原因就是反向代理可以作为内部负载均衡(load balance)的手段:

如果你在云上有好几台主机,甚至还可以将其组成一个内网,然后将 tomcat 部署在不同的主机上。比如有三台主机的话,一台运行 Nginx 监听 80 端口,其余两台运行 tomcat,分别监听 8080 和 8081 端口,同时接受并处理 Nginx 反向代理过来的请求,如下图所示:

如果两台 tomcat 主机的配置不同,比如一台的性能更强劲些,还可以调整负载的比例(即权重,weight),让性能更强的一台承担更多的请求:
http {
upstream myapp1 {
server 192.168.0.20:8080 weight=3;
server 192.168.0.21:8080 weight=2;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}如上配置 3:2 的权重比,让其中一台承担 60% 的请求,而另一台性能较差的则承担 40%,也即每 5 个请求,3 个会被转到 ip 为 20 的主机上,2 个会转到 ip 为 21 的主机上。
自然,有人可能会有疑问,所有请求都还是要经过 Nginx,它能处理得过来吗?答案是可以的,因为它的功能仅仅是转发,这就有点像美团外卖,虽然它每天接受成千上万的人的点餐,但它自己不需要去买菜、洗菜、切菜、炒菜等,它仅仅需要把订单交给饭店餐馆,然后把它们做好的饭菜配送出去,也即那些耗时的做饭过程都交给了饭店餐馆处理。
在这种反向代理的模式中,同样的,生成网页这个重任交到了隐藏在背后的 tomcat,生成一个复杂的动态网页可能需要经过一些复杂的计算,要查询数据库,要拼凑各个页面组件,可能会比较耗时,但这些请求被两个 tomcat 应用并发地处理了,因此响应的速度还是得到了保证,而这些就是反向代理带来的好处。
3. 前端路由与后端路由
参考 前端南玖 - 博客园 。
从后端路由讲起
在 web 开发早期的「刀耕火种」年代里,一直是后端路由占据主导地位。不管是 php,还是 jsp、asp,用户能通过 URL 访问到的页面,大多是通过后端路由匹配之后再返回给浏览器的。经典面试题,「你从浏览器地址栏里输入www.baidu.com到你看到网页这个过程中经历了什么」其实讲的也是这个道理。

在 web 后端,不管是什么语言的后端框架,都会有一个专门开辟出来的路由模块或者路由区域,用来匹配用户给出的 URL 地址,以及一些表单提交、ajax 请求的地址。通常遇到无法匹配的路由,后端将会返回一个404状态码。
后端路由与服务端渲染
前面说了,「刀耕火种」的年代里,网页通常是通过后端路由直出给客户端浏览器的。也就是网页的 html 一般是在后端服务器里通过模板引擎渲染好再交给前端的。至于一些其他的效果,是通过预先写在页面里的 jQuery、Bootstrap 等常见的前端框架去负责的。
如果你说有些网站已经是通过 ajax 去实现的页面,比如 gmail,比如 qq 邮箱。那么你要注意到哪怕是这些页面,它们页面的「龙骨」也并非是全部通过 ajax 去实现的,依然还是后端直出——这也就是我们现在又老生常谈的服务端渲染。
服务端渲染的好处有很多,比如对于 SEO 友好,一些对安全性要求高的页面采用服务端渲染是更保险的。而在当时还没有 node.js 的年代,为了良好地构建前端页面,都是通过服务端语言对应的模板引擎来实现动态网页、页面结构的组织、组件的复用。比如 Laravel 的 blade,用在 Django 上的 jinja2,用在 Struts 的 jsp 等等。实际上到如今,一门后端语言想要能实现自己的 web 功能,都需要有自己对应的模板引擎。
node.js 诞生之后,前端拥有自己的后端渲染的模板引擎也成为了现实。常见的比如 pug、ejs、nunjucks 等。这些模板引擎搭配 Express、Koa 等后端框架也在一开始风靡一时。
不过在这个过程中,随着 web 应用的开发越来越复杂,单纯服务端渲染的问题开始慢慢的暴露出来了——耦合性太强了,jQuery 时代的页面不好维护,页面切换白屏严重等等。耦合性问题虽然能通过良好的代码结构、规范来解决,不过 jQuery 时代的页面不好维护这是有目共睹的,全局变量满天飞,代码入侵性太高。后续的维护通常是在给前面的代码打补丁。而页面切换的白屏问题虽然可以通过 ajax、或者 iframe 等来解决,但是在实现上就麻烦了——进一步增加了可维护的难度。
于是,我们开始进入了前端路由的时代。
过渡到前端路由
前端路由——顾名思义,页面跳转的 URL 规则匹配由前端来控制。而前端路由主要是有两种显示方式:
- 带有 hash 的前端路由,优点是兼容性高。缺点是 URL 带有
#号不好看 - 不带 hash 的前端路由,优点是 URL 不带
#号,好看。缺点是既需要浏览器支持也需要后端服务器支持
前端路由应用最广泛的例子就是当今的 SPA 的 web 项目。
不管是 Vue、React 还是 Angular 的页面工程,都离不开相应配套的 router 工具。前端路由带来的最明显的好处就是,地址栏 URL 的跳转不会白屏了——这也得益于前端渲染带来的好处。
前端路由与前端渲染
讲前端路由就不能不说前端渲染。以 Vue 项目为例,如果你是用官方的vue-cli搭配 webpack 模板构建的项目,你有没有想过你的浏览器拿到的 html 是什么样的?是你页面长的那样有button有form的样子么?我想不是的。在生产模式下,你看看构建出来的index.html长什么样:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Vue</title>
</head>
<body>
<div id="app"></div>
<script type="text/javascript" src="xxxx.xxx.js"></script>
<script type="text/javascript" src="yyyy.yyy.js"></script>
<script type="text/javascript" src="zzzz.zzz.js"></script>
</body>
</html>通常长上面这个样子。可以看到,这个其实就是你的浏览器从服务端拿到的 html。这里面空荡荡的只有一个<div id="app"></div>这个入口的 div 以及下面配套的一系列 js 文件。所以你看到的页面其实是通过那些 js 渲染出来的。这也是我们常说的前端渲染。

前端渲染把渲染的任务交给了浏览器,通过客户端的算力来解决页面的构建,这个很大程度上缓解了服务端的压力。而且配合前端路由,无缝的页面切换体验自然是对用户友好的。不过带来的坏处就是对 SEO 不友好,毕竟搜索引擎的爬虫只能爬到上面那样的 html,对浏览器的版本也会有相应的要求。
需要明确的是,只要在浏览器地址栏输入 URL 再回车,是一定会去后端服务器请求一次的。而如果是在页面里通过点击按钮等操作,利用 router 库的 api 来进行的 URL 更新是不会去后端服务器请求的。
Hash 模式
hash 模式利用的是浏览器不会对#号后面的路径对服务端发起路由请求。也即在浏览器里输入如下这两个地址:http://localhost/#/user/1和http://localhost/其实到服务端都是去请求http://localhost这个页面的内容。
而前端的 router 库通过捕捉#号后面的参数、地址,来告诉前端库(比如 Vue)渲染对应的页面。这样,不管是我们在浏览器的地址栏输入,或者是页面里通过 router 的 api 进行的跳转,都是一样的跳转逻辑。所以这个模式是不需要后端配置其他逻辑的,只要给前端返回http://localhost对应的 html,剩下具体是哪个页面,就由前端路由去判断便可。
History 模式
不带#号的路由,也就是我们通常能见到的 URL 形式。router 库要实现这个功能一般都是通过 HTML5 提供的 history 这个 api。比如history.pushState()可以向浏览器地址栏 push 一个 URL,而这个 URL 是不会向后端发起请求的!通过这个特性,便能很方便地实现漂亮的 URL。不过需要注意的是,这个 api 对于 IE9 及其以下版本浏览器是不支持的,IE10 开始支持,所以对于浏览器版本是有要求的。vue-router 会检测浏览器版本,当无法启用 history 模式的时候会自动降级为 hash 模式。
上面说了,你在页面里的跳转,通常是通过 router 的 api 去进行的跳转,router 的 api 调用的通常是history.pushState()这个 api,所以跟后端没什么关系。但是一旦你从浏览器地址栏里输入一个地址,比如http://localhost/user/1, 这个 URL 是会向后端发起一个 get 请求的。后端路由表里如果没有配置相应的路由,那么自然就会返回一个 404 了!这也就是很多朋友在生产模式遇到 404 页面的原因。
那么很多人会问了,那为什么我在开发模式下没问题呢?那是因为vue-cli在开发模式下帮你启动的那个express开发服务器帮你做了这方面的配置。理论上在开发模式下本来也是需要配置服务端的,只不过vue-cli都帮你配置好了,所以你就不用手动配置了。
那么该如何配置呢?其实在生产模式下配置也很简单,参考 vue-router 给出的 配置例子。一个原则就是,在所有后端路由规则的最后,配置一个规则,如果前面其他路由规则都不匹配的情况下,就执行这个规则——把构建好的那个index.html返回给前端。这样就解决了后端路由抛出的 404 的问题了,因为只要你输入了http://localhost/user/1这地址,那么由于后端其他路由都不匹配,那么就会返回给浏览器index.html。
浏览器拿到这个 html 之后,router 库就开始工作,开始获取地址栏的 URL 信息,然后再告诉前端库(比如 Vue)渲染对应的页面。到这一步就跟 hash 模式是类似的了。
当然,由于后端无法抛出 404 的页面错误,404 的 URL 规则自然是交给前端路由来决定了。你可以自己在前端路由里决定什么 URL 都不匹配的 404 页面应该显示什么。
前端路由与服务端渲染
虽然前端渲染有诸多好处,不过 SEO 的问题,还是比较突出的。所以 react、vue 等框架在后来也在服务端渲染上做着自己的努力。基于前端库的服务端渲染跟以前基于后端语言的服务端渲染又有所不同。前端框架的服务端渲染大多依然采用的是前端路由,并且由于引入了状态统一、vnode 等等概念,它们的服务端渲染对服务器的性能要求比 php 等语言基于的字符串填充的模板引擎渲染对于服务器的性能要求高得多。所以在这方面不仅是框架本身在不断改进算法、优化,服务端的性能也必须要有所提升。当初掘金换成 SSR 的时候也遇到了对应的性能问题,就是这个原因。
当然在二者之间,也出现了预渲染的概念。也即先在服务端构建出一部分静态的 html 文件,用于直出浏览器。然后剩下的页面再通过常用的前端渲染来实现。通常我们可以把首页采用预渲染的方式。这个的好处是明显的,兼顾了 SEO 和服务器的性能要求。不过它无法做到全站 SEO,生产构建阶段耗时也会有所提高,这也是遗憾所在。
关于预渲染,可以考虑使用 prerender-spa-plugin 这个 webapck 的插件,它的 3.x 版本开始使用 puppeteer 来构建 html 文件了。
前后端分离
得益于前端路由和现代前端框架的完整的前后端渲染能力,跟页面渲染、组织、组件相关的东西,后端终于可以不用再参与了。
前后端分离的开发模式也逐渐开始普及。前端开始更加注重页面开发的工程化、自动化,而后端则更专注于 api 的提供和数据库的保障。代码层面上耦合度也进一步降低,分工也更加明确。我们也摆脱了当初「刀耕火种」的 web 开发年代。撒花~
更新日志
c7dc5-于a357e-于899db-于eedbf-于73b75-于75141-于730b3-于0d4f1-于fbe72-于0e6a3-于5d8a3-于