中文编码问题
2021/6/30大约 3 分钟约 898 字
1. 何谓编码?
需要编码的原因可以总结为以下几条:
- 在计算机中存储信息的最小单元是 1 个字节,即 8 个 bit,所以能表示的字符范围是 0~255 个;
- 人类要表示的符号太多,无法用 1 个字节来完全表示。
要解决这个矛盾必须要有一个新的数据结构 char,而从 char 到 byte 必须编码。
主要的几种编码格式:
- ASCII 码
- ISO-8859-1
- GB2312:《信息技术-中文编码字符集》,双字节编码
- GBK:《汉字内码扩展规范》,扩展了 GB2312
- GB18030:《信息技术-中文编码字符集》,兼容 GB2312,应用不广泛
- UTF-16/UTF-8:说到 UTF 必须提到 Unicode(Universal Code)。
- UTF-16 用两个字节来表示 Unicode 的转化格式,它采用定长的表示方式;
- UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度,不同类型的字符可以由 1~6 个字节组成。UTF-8 有以下编码规则:
- 如果是 1 个字节,最高位(第 8 位)为 0,则表示这是 1 个 ASCII 字符(00~7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果是 1 个字节,以 11 开头,则连接的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果是 1 个字节,以 10 开头,表示它不是首字节,则需要向前查找才能得到当前字符的首字节。
对几种编码格式的比较:
- 将 GB2312 与 GBK 进行比较,应该选择 GBK;
- UTF-16 的编码效率较高,从字符到字节的相互转换更简单,进行字符串操作也更好,其适合在本地磁盘和内存之间使用,可以进行字符和字节之间的快速切换,如 Java 的内存编码就采用 UTF-16 编码;
- 但 UTF-16 不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,所以 UTF-8 更适合网络传输;
- UTF-8 对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面的其他字符,在编码效率上介于 GBK 和 UTF-16,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
2. Java 编码
强烈建议不使用操作系统的默认编码,因为这样会使你的应用程序的编码格式和运行环境绑定,在跨环境时很可能出现乱码问题。
用户从浏览器发起一个 HTTP 请求,需要编码的地方是 URL、Cookie、Parameter。服务器端接收到 HTTP 请求后要解析 HTTP,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据——本地或网络中其他地方的文本文件,这些数据都可能存在编码问题。当 Servlet 处理完所有请求的数据后,需要将这些数据再编码,通过 Socket 发送到用户请求的浏览器时,再经过浏览器解码成为文本。
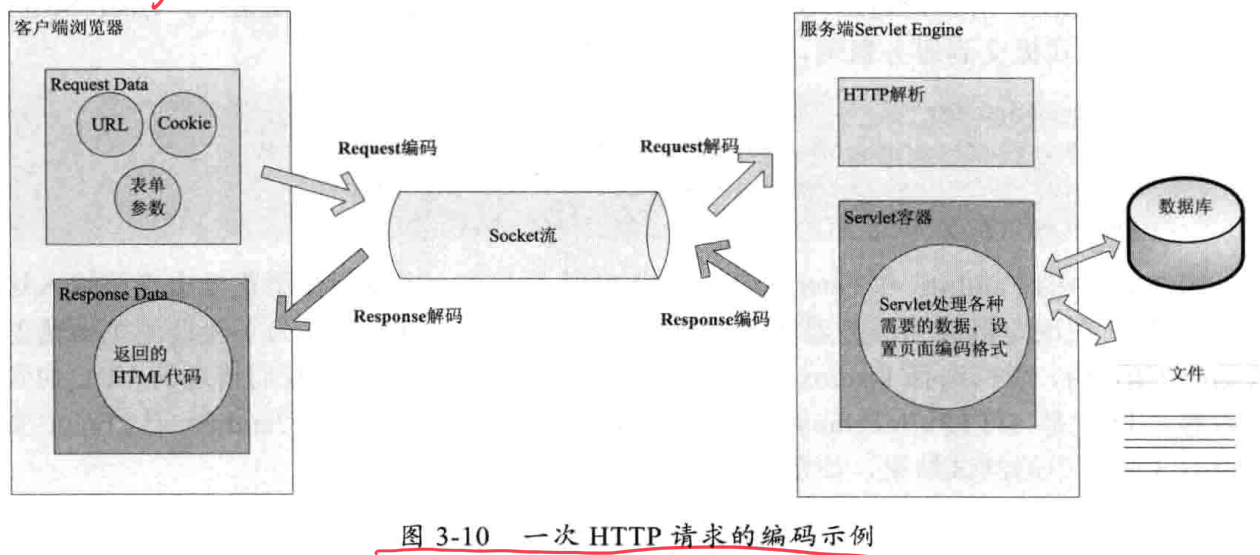
浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字,然后将每个 16 进制表示的字节前加上百分号 %。
更新日志
2024/5/3 10:30
查看所有更新日志
16366-于899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0385f-于0e6a3-于2979f-于