torch.nn
有这样一个意识:pytorch 中很多类都定义了
__call__()方法,使得你得到一个类的实例item之后,仍然可以在其后加一个括号进行调用,即item(),这实际是调用了item.__call__()方法,在很多情况下 pytorch 将__call__()方法定义为其接纳网络输入的函数,故表面上仍可将item理解为仍然是一个可以初始化的类,括号里面的参数为初始化参量。如下面的图片代码片段有多处这样的应用
net = Net() out = net(input)
小批量处理
torch.nn 只支持小批量处理(mini-batches),整个 torch.nn 包只支持小批量样本的输入,不支持单个样本。
即,如当使用 nn.Conv2d 时,其输入 input 应该是一个 4 维张量,即(注意各个位置的参数代表的含义)。
为啥反向传播之前要清零梯度???
nn包结构
torch.nn 包依赖于 autograd 包来定义模型并对它们求导同,nn 包内定义了一系列模块,它们大致等同于神经网络的各层。torch.nn 包的内容大致如下:
| 内容类型 | 具体实现 |
|---|---|
| Parameters | … |
| Containers | Module Sequential ModuleList ModuleDict ParamaterList ParameterDict |
| Convolution layers | Conv1d Conv2d Conv3d … |
| Pooling layers | … |
| Padding layers | … |
| Non-linear activations | … |
| Normalization layers | … |
| Recurrent layers | … |
| Transformer layers | … |
| Linear layers | … |
| Dropout layers | … |
| Sparse layers | … |
| Distance functions | … |
| Loss functions | … |
| Vision layers | … |
| DataParallel layers (multi-GPU, distributed) | … |
| Utilities | … |
nn.Module
简介
torch.nn 中最为基础的是 nn.Module 类,它是所有神经网络模型的基础类,每个你自己设计的模型都应该继承 nn.Module。
nn.Module 是一个容器类(?)。
你的模型在继承 nn.Module 时必须自定义的内容有:
__init__()函数中定义的各个层(layer)——这里定义的每个 layer 都对应神经网络模型中的一个 layer一个
forward(input)方法—— 其返回你的模型的 output注意:虽然这个函数定义了所有前向计算的步骤,但是你依然应该通过调用
model_instance(input)来间接实现前向计算,因为这样才会考虑到registered hooks,而直接调用forward()方法会忽略它们。
注意,像 nn.Conv1d, nn.ConvTranspose1d, nn.Linear, … 这些类,尽管也继承自 nn.Module 基类,但它们属于 pytorch 自定义的“非容器型基础类”,因而额外地含有 self.weight(->Tensor), self.bias(->Tensor) 两个属性,分别表示该层的权重和偏置,但你自定义的复杂网络就不含这两个属性了,因为你的网络是一个包含很多 layer 的容器,只有每个 layer 才有权重和偏置。
- 值得注意的是,对于循环神经网络层如 RNN, LSTM…,它固然也有权重和偏置这两个属性,不过由于自身性质,它的权重和偏置分别分为了两块(详见文档):
.weight -> Tensor.weight_ih_l[k]:the learnable input-hidden weights of the k-th layer, of shape….weight_hh_l[k]:the learnable hidden-hidden weights of the k-th layer, of shape…
.bias -> Tensor.bias_ih_l[k]:the learnable input-hidden bias of the k-th layer, of shape(hidden_size).bias_hh_l[k]:the learnable hidden-hidden bias of the k-th layer, of shape(hidden_size)
- 当然,像
Pooling layers, Padding layers, Normalization layers…这些,它们虽然可能有某种可学习的参数,但必然没有什么weight, bias属性(只是 pytorch 把它定义为一种 layer,在实际的网络中这当然不能算作 layer)。
Module 类在内部重载了__call__方法,所以它们的实例可以像函数那样调用,这么做会自动调用它的forward函数方法,相当于向模块传入了一个张量,然后它返回一个输入张量。
方法:属性系列
.state_dict(destination=None, prefix='', keep_vars=False):返回一个包含了模块所有状态的字典,所有的模型参数和持久缓冲区都囊括其中。字典的键值就是相应的参数和缓冲区的名字。>>> module.state_dict().keys() ['bias', 'weight'].modules():返回一个当前模块内所有模块(含自身)的迭代器。注意:重复的模块只会被返回一次。
>>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) >>> for idx, m in enumerate(net.modules()): print(idx, '->', m) 0 -> Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) ) 1 -> Linear(in_features=2, out_features=2, bias=True).named_modules(memo=None, prefix=''):返回一个当前模块内所有模块(包括自身)的迭代器,每次返回的元素是由模块的名字和模块自身组成的元组。注意:重复的模块只会被返回一次
>>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) >>> for idx, m in enumerate(net.named_modules()): print(idx, '->', m) 0 -> ('', Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) )) 1 -> ('0', Linear(in_features=2, out_features=2, bias=True)).parameters(recurse=True):返回一个遍历模块所有参数的迭代器。此函数一个典型应用就是将其返回值用作传入优化器的参数。>>> for param in model.parameters(): >>> print(type(param.data), param.size()) <class 'torch.FloatTensor'> (20L,) <class 'torch.FloatTensor'> (20L, 1L, 5L, 5L).named_parameters(prefix='', recurse=True):返回一个模块参数的迭代器,每次返回的元素为名字和参数组成的元组。>>> for name, param in self.named_parameters(): >>> if name in ['bias']: >>> print(param.size()).children():返回关于直连子模块(immediate children module)的迭代器.named_children():返回一个当前模型直连的子模块的迭代器,每次返回的元素是由子模块的名字和子模块自身组成的元组。.buffers(recurse=True):返回关于 module 缓冲区的迭代器 Yields: torch.Tensor -> module buffer.named_buffers(prefix='', recurse=True):返回一个模块缓冲区的迭代器,每次返回的元素是由缓冲区的名字和缓冲区自身组成的元组。prefix(str): 要添加在所有缓冲区名字之前的前缀recurse(bool): 若为True,迭代器不仅返回模块自身的缓冲区,还递归地返回其子模块的缓冲区;否则,只返回模块自身直连成员的缓冲区
>>> for name, buf in self.named_buffers(): >>> if name in ['running_var']: >>> print(buf.size())
方法:操作系列
.forward(*input):定义每次调用模块时所进行的计算过程,此函数应该被所有继承Module的类重写.zero_grad():将模型所有参数的梯度设置为 0.requires_grad_(requires_grad=True):原位修改模型参数的.requires_grad属性。此方法有助于冻结模块的一部分,以便单独微调或训练模型的一部分(如 GAN 的训练过程).eval():将模块转换为 evaluation 模式,此函数等价于self.train(False)。This has any effect only on certain modules. See documentations of particular modules for details of their behaviors in training/evaluation mode, if they are affected, e.g. Dropout, BatchNorm, etc.
.train(mode=True):将模型设置为训练(training)模式。This has any effect only on certain modules. See documentations of particular modules for details of their behaviors in training/evaluation mode, if they are affected, e.g. Dropout, BatchNorm, etc.
.apply(fn):递归地对自身和每个子 module(.children()的返回值)执行函数 fn(Module -> None),常用来给一个 model 执行参数初始化(see alsotorch.nn.init)>>> def init_weights(m): >>> print(m) >>> if type(m) == nn.Linear: >>> m.weight.data.fill_(1.0) >>> print(m.weight) >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) >>> net.apply(init_weights) Linear(in_features=2, out_features=2, bias=True) Parameter containing: tensor([[ 1., 1.], [ 1., 1.]]) Linear(in_features=2, out_features=2, bias=True) Parameter containing: tensor([[ 1., 1.], [ 1., 1.]]) Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) ) Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) ).add_module(name, module):给当前 module 添加一个子 module,子 module 可通过 name 当作属性来调用.load_state_dict(state_dict, strict=True):将state_dict中的所有参数和缓冲区拷贝进此模块及其子模块,strict=True意味着state_dict中的键值与模型的state_dict()函数所返回的键值完全一致。此函数还返回
missing_keys和unexpected_keys
方法:移动/类型转换系列
.cpu():将所有模型参数和缓冲区移动到 CPU.cuda(device=None):Moves all model parameters and buffers to the GPU..double():将所有浮点型参数和缓冲区转换为 double 数据类型.float():将所有浮点型参数和缓冲区转换为 float 数据类型.half():将所有浮点型参数和缓冲区转换为 half 数据类型.type(dst_type):将所有参数和缓冲区转化为 dst_type 的数据类型.to(*args, **kwargs):Moves and/or casts the parameters and buffers.- 此函数的函数签名跟torch.Tensor.to()函数的函数签名很相似,只不过这个函数 dtype 参数只接受浮点数类型,如 float, double, half(floating point desired dtype s)。
- 同时,这个方法只会将浮点数类型的参数和缓冲区(the floating point parameters and buffers)转化为 dtype(如果输入参数中给定的话)的数据类型。而对于整数类型的参数和缓冲区(the integral parameters and buffers),即便输入参数中给定了 dtype,也不会进行转换操作
- 注:此方法对模块的修改都是 in-place 操作
>>> linear = nn.Linear(2, 2) >>> linear.weight Parameter containing: tensor([[ 0.1913, -0.3420], [-0.5113, -0.2325]]) >>> linear.to(torch.double) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1913, -0.3420], [-0.5113, -0.2325]], dtype=torch.float64) >>> gpu1 = torch.device("cuda:1") >>> linear.to(gpu1, dtype=torch.half, non_blocking=True) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1914, -0.3420], [-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1') >>> cpu = torch.device("cpu") >>> linear.to(cpu) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1914, -0.3420], [-0.5112, -0.2324]], dtype=torch.float16) # 1) 而如果给定了 device参数,移动操作正常进行。 # 2) 若non_blocking参数被设置为True,此函数会尽可能地相对于 host进行异步的 转换/移动 操作,比如,将存储在固定内存(pinned memory)上的CPU Tensors移动到CUDA设备上这一过程既是如此。
方法:不明觉厉系列
注解:所谓钩子函数,感觉就是一种和某个操作绑定的、不需要显示调用即可(随着该操作的执行而)被自动触发执行的函数。
dump_patches = FALSE:不明觉厉…….register_buffer(name, tensor):往模块上添加一个持久缓冲区。此函数的典型应用是“向模块添加非模型参数的缓冲区”。如 BatchNorm 的 running_mean 就不是一个模型参数,但却属于持久状态。.register_parameter(name, param):向模块添加一个参数。所添加的参数可以通过给定的名字(name 参数)以访问模块属性的方式进行访问。.register_backward_hook(hook):在模块上注册一个挂载在反向传播操作之后的钩子函数。Returns ------- a handle that can be used to remove the added hook by calling handle.remove() Return type ----------- torch.utils.hooks.RemovableHandle Warrning --------此功能的当前实现版本对于一些执行很多操作的复杂 Module,还达不到完全理想的效果。在有些错误的情况下,输入参数
grad_input和grad_output可能只是真正的输入和输出变量的一个子集。对于此类的 Module,你应该使用torch.Tensor.register_hook()直接将钩子挂载到某个特定的输入输出的变量上,而不是当前的模块。- 对于每次输入,当模块关于此次输入的反向梯度的计算过程完成,该钩子函数都会被调用一次
- 此钩子函数需要遵从以下函数签名:
hook(module, grad_input, grad_output) -> Tensor or None - 如果模块的输入或输出是 multiple 的(?),
grad_input和grad_output可以是元组; - 钩子函数不应该对输入的参数
grad_input和grad_output进行任何更改,但是可以选择性地根据输入的参数返回一个新的梯度,这个新的梯度将在后续的计算中替换掉grad_input
.register_forward_hook(hook):在模块上注册一个挂载在前向传播操作之后的钩子函数Returns ------- a handle that can be used to remove the added hook by calling handle.remove() Return type ----------- torch.utils.hooks.RemovableHandle- 此钩子函数在每次模块的
forward()函数运行结束产生输出之后就会被触发。 - 此钩子函数需要遵从以下函数签名
hook(module, input, output) -> None - 此钩子函数可以修改输入的 output;
- 它也能原位修改 input,不过这对
forward()函数没有影响,因为 hook 是在前身传播计算完成之后被调用的
- 此钩子函数在每次模块的
.register_forward_pre_hook(hook):在模块上注册一个挂载在前向传播操作之前的钩子函数Returns ------- a handle that can be used to remove the added hook by calling handle.remove() Return type ----------- torch.utils.hooks.RemovableHandle- 此钩子函数在每次模块的
forward()函数运行开始之前会被触发 - 此钩子函数需要遵从以下函数签名
hook(module, input) -> None - 此钩子函数可以修改输入的 input;
- 这个钩子函数可以返回一个元组,或一个单独的修改后的值。实际上,对于后者,其将被自动封装成一个元组
- 此钩子函数在每次模块的
nn.Sequential
nn.Sequential是一个容器型的类,它用来包含其他的 Modules 并按顺序执行这些模块来产生其输出:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))利用 nn.Sequential 类可先定义一个自己的 Module 然后将其纳入 nn.Sequential 中来顺序化执行:
class Lambda(nn.Module):
def __init__(self, func):
super().__init__()
self.func = func
def forward(self, x):
return self.func(x)
def preprocess(x):
return x.view(-1, 1, 28, 28)
model = nn.Sequential(
Lambda(preprocess),
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.AvgPool2d(4),
Lambda(lambda x: x.view(x.size(0), -1)),
)
opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)损失函数
nn 包中有很多不同的损失函数的类,如均方误差 nn.MSELoss 使用如下:
output = net(input)
target = torch.randn(10)
# 本例子中使用模拟数据
target = target.view(1, -1)
# 使目标值与数据值形状一致
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
# tensor(1.0263, grad_fn=<MseLossBackward>)一个完整的训练步骤的每次迭代会进行以下几个操作:
从全部数据中选择一小批数据;
使用模型进行预测;
计算当前预测的损失值;
使用
loss.backward()更新模型中的梯度;将梯度设置为 0,为下一次循环做准备。
如果不这样我们的梯度将会记录所有已执行过的运算,如
loss.backward()会把梯度变换值直接与变量已有值进行累加,而不是替换变量原有值。
torch.nn.functional
import torch.nn.functional as F
torch.nn.functional 模块包含了 torch.nn 库的所有函数(torch.nn 中的其他部分是各种类),这是一个神经网络的函数式接口(functional interface)模块,不过这些操作使用库中的其它部分会更好。
| 内容类型 | 具体实现 |
|---|---|
| Convolution functions | conv1d conv2d conv3d conv_transpose1d conv_transpose2d conv_transpose3d unfold fold |
| Pooling functions | avg_pool1d max_pool1d … avg_pool2d max_pool2d … avg_poo3d max_pool3d … |
| Non-linear activation functions | threshold relu … |
| Normalization functions | batch_norm instance_norm … |
| Linear functions | … |
| Dropout functions | … |
| Sparse functions | … |
| Distance functions | … |
| Loss functions | … |
| Vision functions | … |
| DataParallel functions (multi-GPU, distributed) | … |
自定义神经网络模型的过程
定义自己的神经网络模型的过程:
继承 nn.Module
定义好各层 layer
定义自己的 forward()函数
backward()函数会在使用autograd时自动定义;forward函数得到output,backward()函数用来计算梯度。
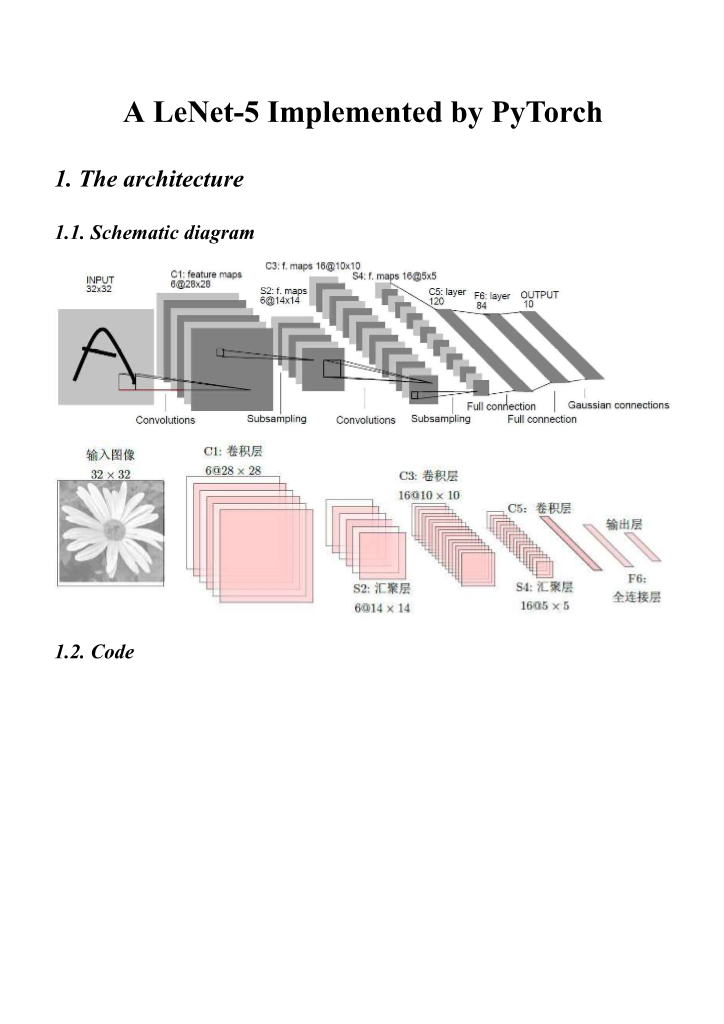 |  |  |  |
|---|
其他
强调一下 self.modules()和 self.children()的区别:
self.modules()采用深度优先遍历的方式,存储了网络(net)的所有模块,包括 net itself, net's children, children of net's children…self.children()只包括网络模块的第一代儿子模块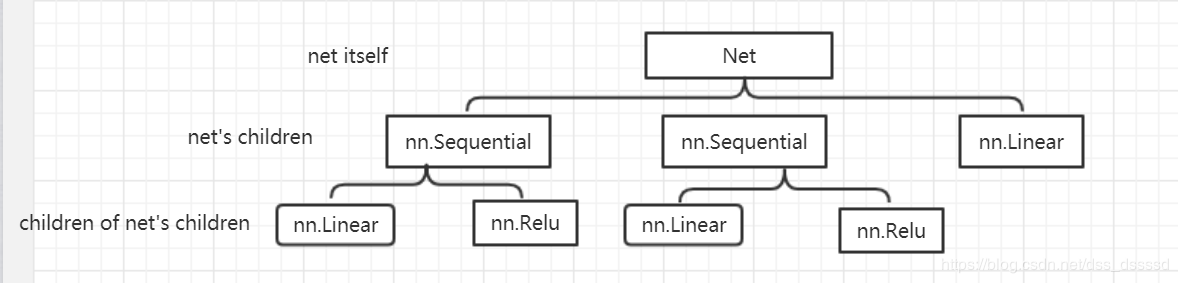
class Net(nn.Module): def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim): super().__init__() self.layer = nn.Sequential( nn.Linear(in_dim, n_hidden_1), nn.ReLU(True) ) self.layer2 = nn.Sequential( nn.Linear(n_hidden_1, n_hidden_2), nn.ReLU(True), ) self.layer3 = nn.Linear(n_hidden_2, out_dim) def forward(self, x): x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) return x
强调一下 self.eval()和 self.train() 的区别:
这两个模式与是否跟踪梯度无关,如 PyTorch 文档所说,其区别仅在于某些特殊的层在训练和评价模式中发挥的作用是不同的,具体的不同在于其在两个模式下使用了不同的参数;
比如,PyTorch 在训练时是一个批量一个批量的输入,当使用了 BN 层时,其需要由这个批量计算输入的均值和方差,故无法在训练时处理 batch_size=1 的输入,而当设置为
eval()模式时,BN 层的均值、方差等参数已固定,故可以处理 batch_size=1 的输入;
当模型中不含 BN, DropOut 等这些特殊层时,
train()和eval()模式其实没有区别。
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于ac5e8-于069cd-于