shell脚本
1. shell 基操
1.1 认识 shell 脚本
shell 终端解释器作为用户与 Linux 系统内部的通信媒介,除了支持各种变量与参数外,还提供了诸如循环、分支等高级编程语言才有的控制结构特性。
shell 脚本文件的名称可以任意,但为了避免被误以为是普通文件,最好将 .sh 后缀加上,以表示是一个脚本文件。以下为一个简单的脚本编写内容,其中第一行的脚本声明(#!)用来告诉系统使用哪种 shell 解释器来执行该脚本,第二行的注释信息(#)是对脚本功能和某些命令的介绍信息,第三、四行的可执行语句也就是我们平时执行的 Linux 命令了。
| 脚本内容 | 执行脚本 |
|---|---|
 |  |
1.2 执行脚本
执行脚本可用bash <example.sh>或输入完整路径./example.sh,不过后一种默认会因权限不足而提示错误,此时只要为脚本文件增加执行权限即可,如下:
$ chmod u+x test1
$ ./test1
Mon Feb 21 15:38:19 EST 2014
Christine tty2 2014-02-21 15:26
Samantha tty3 2014-02-21 15:26
Timothy tty1 2014-02-21 15:26
user tty7 2014-02-19 14:03 (:0)
user pts/0 2014-02-21 15:21 (:0.0)
$1.3 使用变量
在脚本中,你可以在环境变量名称之前加上美元符($)来使用这些环境变量。
除了环境变量,shell脚本还允许在脚本中定义和使用自己的变量。定义变量允许临时存储数据并在整个脚本中使用,从而使shell脚本看起来更像一个真正的计算机程序。
自定义变量可以是任何由字母、数字或下划线组成的文本字符串,长度不超过20个。使用等号将值赋给用户变量,shell脚本会自动决定变量值的数据类型,在变量、等号和值之间不能出现空格:
var1=10
var2=-57
var3=testing
var4="still more testing"引用一个变量值时需要使用美元符$,而引用变量来对其进行赋值时则不要使用美元符:
$ cat test4
#!/bin/bash
# assigning a variable value to another variable
value1=10
value2=$value1
echo The resulting value is $value2
$1.4 退出状态码
shell 中运行的每个命令都使用退出状态码(exit status)告诉shell它已经运行完毕,退出状态码是一个0~255的整数值,在命令结束运行时由命令传给 shell。
Linux提供了一个专门的变量$?来保存上个已执行命令的退出状态码。对于需要进行检查的命令,在其运行完毕后立刻查看或使用$?变量,它的值就会变成刚刚那条命令的退出状态码。如:
$ date
Sat Jan 15 10:01:30 EDT 2014
$ echo $?
0
$按照惯例,一个成功结束的命令的退出状态码是0,如果一个命令结束时有错误,退出状态码就是一个正数值:
$ asdfg
-bash: asdfg: command not found
$ echo $?
127
$无效命令会返回一个退出状态码127。Linux错误退出状态码没有什么标准可循,但有一些可用的参考,如下表:
| 状 态 码 | 描述 |
|---|---|
| 0 | 命令成功结束 |
| 1 | 一般性未知错误 |
| 2 | 不适合的shell命令 |
| 126 | 命令不可执行 |
| 127 | 没找到命令 |
| 128 | 无效的退出参数 |
| 128+x | 与Linux信号x相关的严重错误 |
| 130 | 通过Ctrl+C终止的命令 |
| 255 | 正常范围之外的退出状态码 |
2. shell 字符串
字符串可以用单引号和双引号,也可以不用引号。
单引号:
str='this is a string',单引号里的任何字符都会原样输出,也就是说单引号字符串中的变量是无效的;双引号:
$ your_name='runoob' $ str="Hello, I know you are \"$your_name\"! \n" $ echo -e $str Hello, I know you are "runoob"!- 双引号里可以有变量
- 双引号里可以出现转义字符
不被引号包围的字符串:
- 不被引号包围的字符串中出现变量时也会被解析,这一点和双引号
" "包围的字符串一样; - 字符串中不能出现空格,否则空格后边的内容会被解析为其他变量或命令。
- 不被引号包围的字符串中出现变量时也会被解析,这一点和双引号
多个字符串直接放在一起时表示字符串拼接(类似 python 的语法):
your_name="runoob"
# 使用双引号拼接
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
# 使用单引号拼接
greeting_2='hello, '$your_name' !'
greeting_3='hello, ${your_name} !'
echo $greeting_2 $greeting_3hello, runoob ! hello, runoob !
hello, runoob ! hello, ${your_name} !获取字符串长度:
string="abcd"
echo ${#string} # 输出 43. 流程控制
3.1 if-then
基本使用
基本的单分支结构示意如下:
if command
then
commands
fi另一种常见的书写形式为:
if command; then commands fi
直观看来,这种形式的 if 语句可能有点奇怪,其并非一个条件判断语句,而是一个普通的命令,if 语句在判断逻辑时实际上是根据该“条件命令”的退出状态码是否为0来作决定的,如果是0,则执行then 后面的命令,fi 语句则用来表示if-then语句到此结束。
一个简单的脚本示例如下:
脚本内容:
$ cat test1.sh #!/bin/bash # testing the if statement if pwd then echo "It worked" fi $执行结果:
$ ./test1.sh /home/Christine It worked $
这里再展示一个脚本执行时出错的示例:
脚本内容:
$ cat test2.sh #!/bin/bash # testing a bad command if IamNotaCommand then echo "It worked" fi echo "We are outside the if statement" $执行结果:
$ ./test2.sh ./test2.sh: line 3: IamNotaCommand: command not found We are outside the if statement $
双分支:
if command
then
commands
else
commands
fi多分支:
if command1
then
command set 1
elif command2
then
command set 2
elif command3
then
command set 3
elif command4
then
command set 4
fi条件测试:test 命令
test命令可对特定条件进行测试,并根据返回值来判断该条件语句是否成立。使用test测试命令时,包括以下两种形式:
test 条件表达式;[ 条件表达式 ](注意条件表达式与方括号之间的空格)。
按照测试对象来划分,条件测试语句可分为文件测试、整数值比较、逻辑测试、字符串比较语句:
文件测试:可用参数为:
运算符 作用 -d测试文件是否为目录类型 -e测试文件是否存在 -f判断是否为一般文件 -r测试当前用户是否有权限读取 -w测试当前用户是否有权限写入 -x测试当前用户是否有权限执行 整数值比较:
整数比较 符号 等于 -eq不等于 -ne大于 -gt大于 -lt等于或小于 -le大于或等于 -ge字符串比较:
字符串比较 符号 比较字符串内容是否相同 =比较字符串内容是否不同 !=判断字符串内容是否为空 -z逻辑测试:
逻辑操作 符号 与 && 或 || 非 !
复合条件测试
复合逻辑:if-then语句允许你使用布尔逻辑来组合测试,有两种布尔运算符可用:
[ condition1 ] && [ condition2 ][ condition1 ] || [ condition2 ]
双圆括号
test命令只能在比较中使用简单的算术操作。双括号命令允许你在比较过程中使用高级数学表达式。双括号命令提供了更多的数学符号,这些符号对于用过其他编程语言的程序员而言并不陌生。双括号命令的格式如下:
(( expression ))其中expression可以是任意的数学赋值或比较表达式。除了test命令使用的标准数学运算符,还可包含如下运算符:
| 符号 | 描述 |
|---|---|
val++ | 后增 |
val-- | 后减 |
++val | 先增 |
--val | 先减 |
! | 逻辑求反 |
~ | 位求反 |
** | 幂运算 |
<< | 左位移 |
>> | 右位移 |
& | 位布尔和 |
| | 位布尔或 |
&& | 逻辑和 |
|| | 逻辑或 |
可以在if语句中用双括号命令,也可以在脚本中的普通命令里使用来赋值:
$ cat test23.sh
#!/bin/bash
# using double parenthesis
#
val1=10
#
if (( $val1 ** 2 > 90 ))
then
(( val2 = $val1 ** 2 ))
echo "The square of $val1 is $val2"
fi
$
$ ./test23.sh
The square of 10 is 100
$注意,不需要将双括号中表达式里的大于号
>转义。这是双括号命令提供的另一个高级特性。
双方括号
双方括号命令的格式如下:
[[ expression ]]双方括号里的expression使用了test命令中采用的标准字符串比较,但它提供了test命令未提供的另一个特性——模式匹配(pattern matching)。
双方括号在bash shell中工作良好。不过要小心,不是所有的shell都支持双方括号。
在模式匹配中,可以定义一个正则表达式来匹配字符串值:
$ cat test24.sh
#!/bin/bash
# using pattern matching
#
if [[ $USER == r* ]]
then
echo "Hello $USER"
else
echo "Sorry, I do not know you"
fi
$
$ ./test24.sh
Hello rich
$在上面的脚本中,我们使用了双等号==。双等号将右边的字符串(r*)视为一个模式,并应用模式匹配规则。
3.2 case
有了case命令,就不需要再写出烦琐的elif语句来不停地检查同一个变量的值了,case命令会采用列表格式来检查单个变量的多个值:
case variable in
pattern1 | pattern2) commands1;;
pattern3) commands2;;
*) default commands;;
esac例如,以下两者等效,显然case语句更简洁:
if-elif形式:$ cat test25.sh #!/bin/bash # looking for a possible value # if [ $USER = "rich" ] then echo "Welcome $USER" echo "Please enjoy your visit" elif [ $USER = "barbara" ] then echo "Welcome $USER" echo "Please enjoy your visit" elif [ $USER = "testing" ] then echo "Special testing account" elif [ $USER = "jessica" ] then echo "Do not forget to logout when you're done" else echo "Sorry, you are not allowed here" fi $ $ ./test25.sh Welcome rich Please enjoy your visit $case形式:$ cat test26.sh #!/bin/bash # using the case command # case $USER in rich | barbara) echo "Welcome, $USER" echo "Please enjoy your visit";; testing) echo "Special testing account";; jessica) echo "Do not forget to log off when you're done";; *) echo "Sorry, you are not allowed here";; esac $ $ ./test26.sh Welcome, rich Please enjoy your visit $
3.3 循环命令
for 循环
语法格式:
for var in list
do
commands
done只要你愿意,也可以将do语句和for语句放在同一行,但必须用分号将其同列表中的值分开:
for var in list; do commands done
for循环假定每个值都是用空格分割的,使用示例:
读取列表中的值:
$ cat test1b #!/bin/bash # testing the for variable after the looping for test in Alabama Alaska Arizona Arkansas California Colorado do echo "The next state is $test" done echo "The last state we visited was $test" test=Connecticut echo "Wait, now we're visiting $test" $ ./test1b The next state is Alabama The next state is Alaska The next state is Arizona The next state is Arkansas The next state is California The next state is Colorado The last state we visited was Colorado Wait, now we're visiting Connecticut $从变量读取列表:
$ cat test4 #!/bin/bash # using a variable to hold the list list="Alabama Alaska Arizona Arkansas Colorado" list=$list" Connecticut" for state in $list do echo "Have you ever visited $state?" done $ ./test4 Have you ever visited Alabama? Have you ever visited Alaska? Have you ever visited Arizona? Have you ever visited Arkansas? Have you ever visited Colorado? Have you ever visited Connecticut? $从命令读取值:
$ cat test5 #!/bin/bash # reading values from a file file="states" for state in $(cat $file) do echo "Visit beautiful $state" done $ cat states Alabama Alaska Arizona Arkansas Colorado Connecticut Delaware Florida Georgia $ ./test5 Visit beautiful Alabama Visit beautiful Alaska Visit beautiful Arizona Visit beautiful Arkansas Visit beautiful Colorado Visit beautiful Connecticut Visit beautiful Delaware Visit beautiful Florida Visit beautiful Georgia $用通配符读取目录:
$ cat test6 #!/bin/bash # iterate through all the files in a directory for file in /home/rich/test/* do if [ -d "$file" ] then echo "$file is a directory" elif [ -f "$file" ] then echo "$file is a file" fi done $ ./test6 /home/rich/test/dir1 is a directory /home/rich/test/myprog.c is a file /home/rich/test/myprog is a file /home/rich/test/myscript is a file /home/rich/test/newdir is a directory /home/rich/test/newfile is a file /home/rich/test/newfile2 is a file /home/rich/test/testdir is a directory /home/rich/test/testing is a file /home/rich/test/testprog is a file /home/rich/test/testprog.c is a file $在Linux中,目录名和文件名中包含空格当然是合法的。要适应这种情况,应该将
$file变量用双引号圈起来。如果不这么做,遇到含有空格的目录名或文件名时就会有错误产生:./test6: line 6: [: too many arguments ./test6: line 9: [: too many arguments在
test命令中,bash shell会将额外的单词当作参数,进而造成错误。
C 语言风格的 for 命令,暂略......
while 循环
while命令的格式是:
while test command
do
other commands
done基本使用示例:
$ cat test10 #!/bin/bash # while command test var1=10 while [ $var1 -gt 0 ] do echo $var1 var1=$[ $var1 - 1 ] done $ ./test10 10 9 8 7 6 5 4 3 2 1 $使用多个测试命令:
while命令允许你在while语句行定义多个测试命令,只有最后一个测试命令的退出状态码,会被用来决定什么时候结束循环。$ cat test11 #!/bin/bash # testing a multicommand while loop var1=10 while echo $var1 [ $var1 -ge 0 ] do echo "This is inside the loop" var1=$[ $var1 - 1 ] done $ ./test11 10 This is inside the loop 9 This is inside the loop 8 This is inside the loop 7 This is inside the loop 6 This is inside the loop 5 This is inside the loop 4 This is inside the loop 3 This is inside the loop 2 This is inside the loop 1 This is inside the loop 0 This is inside the loop -1 $在上述示例中,第一个测试命令简单地显示了
var1变量的当前值,第二个测试命令用方括号来判断var1变量的值。上例的最终结果说明,在含有多个命令的while语句中,在每次迭代中所有的测试命令都会被执行。
until 循环
until命令和while命令工作的方式完全相反,你明白的,其语法格式如下:
until test commands
do
other commands
done当然,和while命令类似,你可以在until命令语句中放入多个测试命令,此时只有最后一个命令的退出状态码决定了shell是否执行已定义的other commands。
until的基本使用示例:
$ cat test12
#!/bin/bash
# using the until command
var1=100
until [ $var1 -eq 0 ]
do
echo $var1
var1=$[ $var1 - 25 ]
done
$ ./test12
100
75
50
25
$break/continue
Linux shell 中的break、continue用来控制循环,其用法与通常的编程语言一模一样,无须多言。
唯一需强调的是,break、continue不仅能控制当前层级的循环,还可通常break n、continue n来控制外层循环,其中n为1即为不带参数时的默认情况,表明作用的是当前循环。
以下给予几个示例:
基本示例——
break跳出当前循环:$ cat test17 #!/bin/bash # breaking out of a for loop for var1 in 1 2 3 4 5 6 7 8 9 10 do if [ $var1 -eq 5 ] then break fi echo "Iteration number: $var1" done echo "The for loop is completed" $ ./test17 Iteration number: 1 Iteration number: 2 Iteration number: 3 Iteration number: 4 The for loop is completed $break跳出外部循环:$ cat test20 #!/bin/bash # breaking out of an outer loop for (( a = 1; a < 4; a++ )) do echo "Outer loop: $a" for (( b = 1; b < 100; b++ )) do if [ $b -gt 4 ] then break 2 fi echo " Inner loop: $b" done done $ ./test20 Outer loop: 1 Inner loop: 1 Inner loop: 2 Inner loop: 3 Inner loop: 4 $
处理循环输出——重定向/管道
在shell脚本中,你可以对循环的输出使用管道或进行重定向,这可以通过在done命令之后添加一个处理命令来实现。
重定向:以下示例shell会将
for命令的结果重定向到文件output.txt中,而不是显示在屏幕上。for file in /home/rich/* do if [ -d "$file" ] then echo "$file is a directory" elif echo "$file is a file" fi done > output.txt管道:将循环的结果管接给另一个命令
$ cat test24 #!/bin/bash # piping a loop to another command for state in "North Dakota" Connecticut Illinois Alabama Tennessee do echo "$state is the next place to go" done | sort echo "This completes our travels" $ ./test24 Alabama is the next place to go Connecticut is the next place to go Illinois is the next place to go North Dakota is the next place to go Tennessee is the next place to go This completes our travels $
4. 处理用户输入
4.1 位置参数
bash shell会将一些称为位置参数(positional parameter)的特殊变量分配给输入到命令行中的所有参数,其中也包括shell所执行的脚本名称。位置参数变量是标准的数字:$0是程序名,$1是第一个参数,$2是第二个参数,依次类推,当数量超过要排列到9之后时,需要在变量周围加上花括号,比如${10}。以下为一个示例:
$ cat test4.sh
#!/bin/bash
# handling lots of parameters
#
total=$[ ${10} * ${11} ]
echo The tenth parameter is ${10}
echo The eleventh parameter is ${11}
echo The total is $total
$
$ ./test4.sh 1 2 3 4 5 6 7 8 9 10 11 12
The tenth parameter is 10
The eleventh parameter is 11
The total is 110
$用$0参数读取脚本名时,针对不同的脚本启动方式,以及传入的路径,获取到的脚本名称稍有差别。例如,对于下述脚本:
$ cat test5.sh
#!/bin/bash
# Testing the $0 parameter
#
echo The zero parameter is set to: $0
#
$bash启动:
$ bash test5.sh The zero parameter is set to: test5.sh $ $ bash /home/Christine/test5.sh The zero parameter is set to: /home/Christine/test5.sh $./xxx.sh启动:$ ./test5.sh The zero parameter is set to: ./test5.sh $ $ /home/Christine/test5.sh The zero parameter is set to: /home/Christine/test5.sh
此时,如果只想要不含路径的 shell 文件名,可以在脚本中使用 basename 命令,如:
$ basename /home/Christine/test5.sh
test5.sh4.2 特殊变量
变量 $#
特殊变量$#含有脚本运行时携带的命令行参数的个数。可以在脚本中任何地方使用这个特殊变量,就跟普通变量一样。
在使用$#时稍微有点特殊的是,尽管$#变量含有参数的总数,但是不能使用${$#}来取最后一个命令行参数变量,因为花括号内不能使用$,此时需要将里面的$改为!:
$ cat test10.sh
#!/bin/bash
# Grabbing the last parameter
#
params=$#
echo
echo The last parameter is $params
echo The last parameter is ${!#}
echo
#
$
$ bash test10.sh 1 2 3 4 5
The last parameter is 5
The last parameter is 5
$
$ bash test10.sh
The last parameter is 0
The last parameter is test10.sh
$变量 $* 与 $@
有时候需要抓取命令行上提供的所有参数。这时候不需要先用$#变量来判断命令行上有多少参数,然后再进行遍历,你可以使用$*和$@变量来轻松访问所有的参数,这两个变量都能够在单个变量中存储所有的命令行参数。
$*变量会将命令行上提供的所有参数当作一个单词保存,这个单词包含了命令行中出现的每一个参数值。基本上$*变量会将这些参数视为一个整体,而不是多个个体。$@变量会将命令行上提供的所有参数当作同一字符串中的多个独立的单词,这样你也能够遍历所有的参数值,得到每个参数,这通常通过for命令完成。
$ cat test12.sh
#!/bin/bash
# testing $* and $@
#
echo
count=1
#
for param in "$*"
do
echo "\$* Parameter #$count = $param"
count=$[ $count + 1 ]
done
#
echo
count=1
#
for param in "$@"
do
echo "\$@ Parameter #$count = $param"
count=$[ $count + 1 ]
done
$
$ ./test12.sh rich barbara katie jessica
$* Parameter #1 = rich barbara katie jessica
$@ Parameter #1 = rich
$@ Parameter #2 = barbara
$@ Parameter #3 = katie
$@ Parameter #4 = jessica
$4.3 shift 命令
bash shell的shift命令能够用来操作命令行参数,跟字面上的意思一样,shift命令会根据它们的相对位置来移动命令行参数。
在使用shift命令时,默认情况下它会将每个参数变量向左移动一个位置。所以,变量$3的值会移到$2中,变量$2的值会移到$1中,而变量$1的值则会被删除。注意,变量$0的值,也就是程序名,不会改变。
shift命令是遍历命令行参数的另一个好方法,尤其是在你不知道到底有多少参数时。你可以只操作第一个参数,然后shift,之后继续操作第一个参数:
$ cat test13.sh
#!/bin/bash
# demonstrating the shift command
echo
count=1
while [ -n "$1" ]
do
echo "Parameter #$count = $1"
count=$[ $count + 1 ]
shift
done
$
$ ./test13.sh rich barbara katie jessica
Parameter #1 = rich
Parameter #2 = barbara
Parameter #3 = katie
Parameter #4 = jessica
$另外,你也可以一次性移动多个位置,只需要给shift命令提供一个参数,指明要移动的位置数就行了,即shift n:
$ cat test14.sh
#!/bin/bash
# demonstrating a multi-position shift
#
echo
echo "The original parameters: $*"
shift 2
echo "Here's the new first parameter: $1"
$
$ ./test14.sh 1 2 3 4 5
The original parameters: 1 2 3 4 5
Here's the new first parameter: 3
$4.4 处理选项
直接处理
直观来看,命令行选项也没什么特殊的,它们紧跟在脚本名之后,就跟命令行参数一样。实际上,如果愿意,你可以像处理命令行参数一样处理命令行选项。
如下是一个处理$ ./testing.sh -a test1 -b -c -d test2命令的的脚本示意:
$ cat test17.sh
#!/bin/bash
# extracting command line options and values
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option";;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
-c) echo "Found the -c option";;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
#
count=1
for param in "$@"
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
$
$ ./test17.sh -a -b test1 -d
Found the -a option
Found the -b option, with parameter value test1
-d is not an option
$然而上述的缺点是,对于 Linux 中常用的选项合并不友好。例如当-a -b合并为-ab时就难以处理了。
getopt 命令
getopt命令可以接受一系列任意形式的命令行选项和参数,并自动将它们转换成适当的格式。它的命令格式如下:
getopt optstring parametersoptstring是这个过程的关键所在,它定义了命令行有效的选项字母,还定义了哪些选项字母需要参数值。首先,在optstring中列出你要在脚本中用到的每个命令行选项字母。然后,在每个需要参数值的选项字母后加一个冒号,getopt命令会基于你定义的optstring解析提供的参数。
下面是个getopt如何工作的简单例子:
$ getopt ab:cd -a -b test1 -cd test2 test3
-a -b test1 -c -d -- test2 test3
$
optstring定义了四个有效选项字母:a、b、c和d。冒号(:)被放在了字母b后面,因为b选项需要一个参数值。当getopt命令运行时,它会检查提供的参数列表(-a -b test1 -cd test2 test3),并基于提供的optstring进行解析。注意,它会自动将-cd选项分成两个单独的选项,并插入双破折线--来分隔行中的额外参数。
如果指定了一个不在optstring中的选项,默认情况下,getopt命令会产生一条错误消息:
$ getopt ab:cd -a -b test1 -cde test2 test3
getopt: invalid option -- e
-a -b test1 -c -d -- test2 test3
$可以在脚本中使用getopt来格式化脚本所携带的任何命令行选项或参数,方法是结合set命令,用getopt命令生成的格式化后的版本来替换已有的命令行选项和参数,即:
set命令的选项之一是双破折线(--),它会将命令行参数替换成set命令的命令行值。
set -- $(getopt -q ab:cd "$@")由上,现在就可以写出能帮我们处理命令行参数的脚本:
$ cat test18.sh
#!/bin/bash
# Extract command line options & values with getopt
#
set -- $(getopt -q ab:cd "$@")
#
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) param="$2"
echo "Found the -b option, with parameter value $param"
shift ;;
-c) echo "Found the -c option" ;;
--) shift
break ;;
*) echo "$1 is not an option";;
esac
shift
done
#
count=1
for param in "$@"
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
#
$ ./test18.sh -ac
Found the -a option
Found the -c option
$getopt命令的问题在于,其不擅长处理带空格和引号的参数值,它会将空格当作参数分隔符,而不是根据双引号将二者当作一个参数:
$ ./test18.sh -a -b test1 -cd "test2 test3" test4
Found the -a option
Found the -b option, with parameter value 'test1'
Found the -c option
Parameter #1: 'test2
Parameter #2: test3'
Parameter #3: 'test4'
$getopts 命令
getopts命令内建于bash shell,它跟近亲getopt看起来很像,但多了一些扩展功能。与getopt不同,前者将命令行上选项和参数处理后只生成一个输出,而getopts命令能够和已有的shell参数变量配合默契。每次调用getopts时,它一次只处理命令行上检测到的一个参数,处理完所有的参数后,它会退出并返回一个大于0的退出状态码,这让它非常适合用于解析命令行所有参数的循环中。
getopts命令的格式如下:
getopts optstring variableoptstring值同于getopt命令,getopts命令将当前参数保存在命令行中定义的variable中。getopts命令会用到两个环境变量:- 如果选项需要跟一个参数值,
OPTARG环境变量就会保存这个值 OPTIND环境变量保存了参数列表中getopts正在处理的参数位置
- 如果选项需要跟一个参数值,
以下为一个简单示例:
$ cat test19.sh
#!/bin/bash
# simple demonstration of the getopts command
#
echo
while getopts :ab:c opt
do
case "$opt" in
a) echo "Found the -a option" ;;
b) echo "Found the -b option, with value $OPTARG";;
c) echo "Found the -c option" ;;
*) echo "Unknown option: $opt";;
esac
done
$
$ ./test19.sh -ab test1 -c
Found the -a option
Found the -b option, with value test1
Found the -c option
$
getopts命令解析命令行选项时会移除开头的单破折线,所以在case定义中不用单破折线。
此外,getopts命令有几个好用的功能:
可以在参数值中包含空格
$ ./test19.sh -b "test1 test2" -a Found the -b option, with value test1 test2 Found the -a option $可将选项字母和参数值放在一起使用,而不用加空格
$ ./test19.sh -abtest1 Found the -a option Found the -b option, with value test1 $够将命令行上找到的所有未定义的选项统一输出成问号
$ ./test19.sh -d Unknown option: ? $ $ ./test19.sh -acde Found the -a option Found the -c option Unknown option: ? Unknown option: ? $在
getopts处理每个选项时,它会将OPTIND环境变量值增1$ cat test20.sh #!/bin/bash # Processing options & parameters with getopts # echo while getopts :ab:cd opt do case "$opt" in a) echo "Found the -a option" ;; b) echo "Found the -b option, with value $OPTARG" ;; c) echo "Found the -c option" ;; d) echo "Found the -d option" ;; *) echo "Unknown option: $opt" ;; esac done # shift $[ $OPTIND - 1 ] # echo count=1 for param in "$@" do echo "Parameter $count: $param" count=$[ $count + 1 ] done # $ $ ./test20.sh -a -b test1 -d test2 test3 test4 Found the -a option Found the -b option, with value test1 Found the -d option Parameter 1: test2 Parameter 2: test3 Parameter 3: test4 $
4.5 获得交互式用户输入
尽管命令行选项和参数是从脚本用户处获得输入的一种重要方式,但有时脚本的交互性还需要更强一些。
基本读取
read命令从标准输入(键盘)或另一个文件描述符中接受输入,在收到输入后,read命令会将数据放进一个变量:
$ cat test21.sh
#!/bin/bash
# testing the read command
#
echo -n "Enter your name: "
read name
echo "Hello $name, welcome to my program. "
#
$
$ ./test21.sh
Enter your name: Rich Blum
Hello Rich Blum, welcome to my program.
$注意,生成提示的
echo命令使用了-n选项。该选项不会在字符串末尾输出换行符,允许脚本用户紧跟其后输入数据,而不是下一行。这让脚本看起来更像表单。
read命令存储用户输入:
- 如果
read后没有放变量名:read会将收到的所有数据都放到环境变量REPLY中; - 如果
read后只有一个变量名:read会将收到的所有数据都放到该变量中; - 如果
read后有多个变量名:read会将收到的数据依次放入相应变量中,如果变量数据不够,剩下的数据就全部分给最后一个变量。
超时设置
使用read命令时,脚本很可能会一直苦等着脚本用户的输入。如果不管是否有数据输入,脚本都必须继续执行,你可以用-t选项来指定一个计时器。-t选项指定了read命令等待输入的秒数,当计时器过期后,read命令会返回一个非零退出状态码。
$ cat test25.sh
#!/bin/bash
# timing the data entry
#
if read -t 5 -p "Please enter your name: " name
then
echo "Hello $name, welcome to my script"
else
echo
echo "Sorry, too slow! "
fi
$
$ ./test25.sh
Please enter your name: Rich
Hello Rich, welcome to my script
$
$ ./test25.sh
Please enter your name:
Sorry, too slow!
$隐藏方式读取
有时你需要从脚本用户处得到输入,但又在屏幕上显示输入信息,其中典型的例子就是输入的密码。
-s选项可以避免在read命令中输入的数据出现在显示器上(实际上,数据会被显示,只是read命令会将文本颜色设成跟背景色一样)。示例如下:
$ cat test27.sh
#!/bin/bash
# hiding input data from the monitor
#
read -s -p "Enter your password: " pass
echo
echo "Is your password really $pass? "
$
$ ./test27.sh
Enter your password:
Is your password really T3st1ng?
$从文件读取
也可以用read命令来读取Linux系统上文件里保存的数据。每次调用read命令,它都会从文件中读取一行文本。当文件中再没有内容时,read命令会退出并返回非零退出状态码。
其实最难的部分是将文件中的数据传给read命令,最常见的方法是对文件使用cat命令,将结果通过管道直接传给含有read命令的while命令,如下:
$ cat test28.sh
#!/bin/bash
# reading data from a file
#
count=1
cat test | while read line
do
echo "Line $count: $line"
count=$[ $count + 1]
done
echo "Finished processing the file"
$
$ cat test
The quick brown dog jumps over the lazy fox.
This is a test, this is only a test.
O Romeo, Romeo! Wherefore art thou Romeo?
$
$ ./test28.sh
Line 1: The quick brown dog jumps over the lazy fox.
Line 2: This is a test, this is only a test.
Line 3: O Romeo, Romeo! Wherefore art thou Romeo?
Finished processing the file
$5. 脚本函数
函数是一个脚本代码块,你可以为其命名并在代码中任何位置重用。要在脚本中使用该代码块时,只要使用所起的函数名就行了,这个过程称为调用函数。
5.1 创建函数
有两种格式可以用来在bash shell脚本中创建函数:
采用关键字
function:function name { commands }圆括号方式:
name() { commands }
上述定义中:
name属性定义了赋予函数的唯一名称,脚本中定义的每个函数都必须有一个唯一的名称;如果你在后续行中重定义了该函数,新定义会覆盖原来函数的定义,这一切不会产生任何错误消息。commands是构成函数的一条或多条bash shell命令,在调用该函数时,bash shell会按命令在函数中出现的顺序依次执行,就像在普通脚本中一样。
5.2 使用函数
基本使用
要在脚本中使用函数,只需要像其他shell命令一样,在行中指定函数名就行了:
$ cat test1
#!/bin/bash
# using a function in a script
function func1 {
echo "This is an example of a function"
}
count=1
while [ $count -le 5 ]
do
func1
count=$[ $count + 1 ]
done
echo "This is the end of the loop"
func1
echo "Now this is the end of the script"
$
$ ./test1
This is an example of a function
This is an example of a function
This is an example of a function
This is an example of a function
This is an example of a function
This is the end of the loop
This is an example of a function
Now this is the end of the script
$处理变量
函数使用两种类型的变量:
全局变量:在shell脚本中任何地方都有效的变量。默认情况下,你在脚本中任何地方定义的变量都是全局变量,也就是说:在函数外定义的变量在函数内可以正常访问,在函数内定义的变量在函数外也可以正常访问。
$ cat test8.sh function fun1 { var2="I'm a global variable defined in function func1." var1="var1别逼逼,本函数要动你了" } var1="I'm a globale variable defined in script directly." echo "var1: $var1" fun1 echo "var2: $var2" echo "var1: $var1" $ $ ./test8.sh var1: I'm a globale variable defined in script directly. var2: I'm a global variable defined in function func1. var1: var1别逼逼,本函数要动你了局部变量:函数内部使用的任何变量可以被声明成局部变量,只要在变量声明的前面加上
local关键字就可以了。local关键字保证了变量只局限在该函数中,如果脚本中在该函数之外有同样名字的变量,那么shell将会保持这两个变量的值是分离的。$ cat test9 #!/bin/bash # demonstrating the local keyword function func1 { local temp=$[ $value + 5 ] result=$[ $temp * 2 ] } temp=4 value=6 func1 echo "The result is $result" if [ $temp -gt $value ] then echo "temp is larger" else echo "temp is smaller" fi $ $ ./test9 The result is 22 temp is smaller $
递归函数
shell 函数也支持递归。如下示意了一个阶乘函数用它自己来计算阶乘的值:
$ cat test13
#!/bin/bash
# using recursion
function factorial {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[ $1 - 1 ]
local result=$(factorial $temp)
echo $[ $result * $1 ]
fi
}
read -p "Enter value: " value
result=$(factorial $value)
echo "The factorial of $value is: $result"
$
$ ./test13
Enter value: 5
The factorial of 5 is: 120
$5.3 函数返回值
bash shell会把函数当作一个小型脚本,运行结束时会返回一个退出状态码,有3种不同的方法来为函数生成退出状态码。
默认退出状态码
默认情况下,函数的退出状态码是函数中最后一条命令返回的退出状态码。在函数执行结束后,可以用标准变量$?来确定函数的退出状态码。如下:
$ cat test4
#!/bin/bash
# testing the exit status of a function
func1() {
echo "trying to display a non-existent file"
ls -l badfile
}
echo "testing the function: "
func1
echo "The exit status is: $?"
$
$ ./test4
testing the function:
trying to display a non-existent file
ls: badfile: No such file or directory
The exit status is: 1
$函数的退出状态码是1,这是因为函数中的最后一条命令没有成功运行。
这种方式的缺点是,你无法知道函数中其他命令中是否成功运行。看下面的例子,由于函数最后一条语句echo运行成功,该函数的退出状态码就是0,但是其中有一条命令并没有正常运行:
cat test4b
#!/bin/bash
# testing the exit status of a function
func1() {
ls -l badfile
echo "This was a test of a bad command"
}
echo "testing the function:"
func1
echo "The exit status is: $?"
$
$ ./test4b
testing the function:
ls: badfile: No such file or directory
This was a test of a bad command
The exit status is: 0
$使用 return 命令
bash shell使用return命令来退出函数并返回特定的退出状态码,return命令允许指定一个整数值来定义函数的退出状态码,从而提供了一种简单的途径来编程设定函数退出状态码。
当用这种方法从函数中返回值时,需要记住下面两条技巧来避免问题:
- 一定要函数一结束就取返回值:如果在用
$?变量提取函数返回值之前执行了其他命令,函数的返回值就会丢失。 - 退出状态码必须是0~255:由于退出状态码必须小于256,函数的结果必须生成一个小于256的整数值,任何大于256的值都会产生一个错误值。
- 要返回较大的整数值或者字符串值的话,你就不能用这种
return返回值的方法了。
$ cat test5
#!/bin/bash
# using the return command in a function
function dbl {
read -p "Enter a value: " value
echo "doubling the value"
return $[ $value * 2 ]
}
dbl
echo "The new value is $?"
$
$ ./test5
Enter a value: 200
doubling the value
The new value is 1
$使用函数输出
正如可以将命令的输出保存到shell变量中一样,你也可以对函数的输出采用同样的处理办法。可以用这种技术来获得任何类型的函数输出,并将其保存到变量中。
下面示例将dbl函数的输出赋给$result变量,在函数中会用echo语句来显示计算的结果,同时该脚本会获取dbl函数的输出,而不是查看退出状态码:
$ cat test5b
#!/bin/bash
# using the echo to return a value
function dbl {
read -p "Enter a value: " value
echo $[ $value * 2 ]
}
result=$(dbl)
echo "The new value is $result"
$
$ ./test5b
Enter a value: 200
The new value is 400
$
$ ./test5b
Enter a value: 1000
The new value is 2000
$5.4 向函数传参
函数可以使用标准的参数环境变量来表示命令行上传给函数的参数。例如,函数名会在$0变量中定义,函数命令行上的任何参数都会通过$1、$2等定义,当然也可以用特殊变量$#来判断传给函数的参数数目。
在脚本中指定函数时,必须将参数和函数放在同一行,像这样,然后函数才可以用参数环境变量来获得参数值:
func1 $value1 10下面是一个使用示例:
$ cat test6
#!/bin/bash
# passing parameters to a function
function addem {
if [ $# -eq 0 ] || [ $# -gt 2 ]
then
echo -1
elif [ $# -eq 1 ]
then
echo $[ $1 + $1 ]
else
echo $[ $1 + $2 ]
fi
}
echo -n "Adding 10 and 15: "
value=$(addem 10 15)
echo $value
echo -n "Let's try adding just one number: "
value=$(addem 10)
echo $value
echo -n "Now trying adding no numbers: "
value=$(addem)
echo $value
echo -n "Finally, try adding three numbers: "
value=$(addem 10 15 20)
echo $value
$
$ ./test6
Adding 10 and 15: 25
Let's try adding just one number: 20
Now trying adding no numbers: -1
Finally, try adding three numbers: -1
$需要额外提醒一下的是,由于函数使用特殊参数环境变量作为自己的参数值,显然它是无法直接获取脚本在命令行中的参数值的。
5.5 数组变量与函数
向函数传递数组
向脚本函数传递数组变量的方法会有点不好理解——将数组变量当作单个参数传递的话,它不会起作用。必须将该数组变量的值分解成单个的值,然后将这些值作为函数参数使用;在函数内部,可以将所有的参数重新组合成一个新的变量,然后才能正常使用,如下:
$ cat test10
#!/bin/bash
# array variable to function test
function testit {
local newarray
newarray=(;'echo "$@"')
echo "The new array value is: ${newarray[*]}"
}
myarray=(1 2 3 4 5)
echo "The original array is ${myarray[*]}"
testit ${myarray[*]}
$
$ ./test10
The original array is 1 2 3 4 5
The new array value is: 1 2 3 4 5
$从函数返回数组
从函数里向shell脚本传回数组变量也需要用类似的方法。函数用echo语句来按正确顺序输出单个数组值,然后脚本再将它们重新放进一个新的数组变量中,如下:
$ cat test12
#!/bin/bash
# returning an array value
function arraydblr {
local origarray
local newarray
local elements
local i
origarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $# - 1 ]
for (( i = 0; i <= $elements; i++ )) {
newarray[$i]=$[ ${origarray[$i]} * 2 ]
}
echo ${newarray[*]}
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=($(arraydblr $arg1))
echo "The new array is: ${result[*]}"
$
$ ./test12
The original array is: 1 2 3 4 5
The new array is: 2 4 6 8 105.6 source命令与函数库
和环境变量一样,shell函数仅在定义它的shell会话内有效。如果你在shell命令行界面的提示符下运行某个定义了若干函数的shell脚本,shell会创建一个新的shell并在其中运行这个脚本,它会为那个新shell定义那些函数,但当你运行另外一个要用到这些函数的脚本时,它们是无法使用的。
为了在多个shell会话中复用函数,bash shell 允许创建函数库文件,然后在多个脚本中引用该库文件,引用的关键是source命令,source命令会在当前shell上下文中执行命令,而不是创建一个新shell,故而可以用source命令来在shell脚本中运行库文件脚本,这样脚本就可以使用库中的函数了。source命令的语法是:
source filename [arguments]. filename [arguments](source命令的快捷别名,点操作符)
如下为一个使用示例:
创建一个包含脚本中所需函数的公用库文件:
$ cat myfuncs # my script functions function addem { echo $[ $1 + $2 ] } function multem { echo $[ $1 * $2 ] } function divem { if [ $2 -ne 0 ] then echo $[ $1 / $2 ] else echo -1 fi } $使用
source命令:$ cat test14 #!/bin/bash # using functions defined in a library file . ./myfuncs value1=10 value2=5 result1=$(addem $value1 $value2) result2=$(multem $value1 $value2) result3=$(divem $value1 $value2) echo "The result of adding them is: $result1" echo "The result of multiplying them is: $result2" echo "The result of dividing them is: $result3" $ $ ./test14 The result of adding them is: 15 The result of multiplying them is: 50 The result of dividing them is: 2 $
6. 处理信号
shell将shell中运行的每个进程称为作业,并为每个作业分配唯一的作业号。它会给第一个作业分配作业号1,第二个作业号2,以此类推。
Linux利用信号与运行在系统中的进程进行通信,Linux系统和应用程序可以生成超过30个信号。下表列出了最常见的Linux系统信号:
| 信号 | 值 | 描述 |
|---|---|---|
| 1 | SIGHUP | 挂起进程 |
| 2 | SIGINT | 终止进程 |
| 3 | SIGQUIT | 停止进程 |
| 9 | SIGKILL | 无条件终止进程 |
| 15 | SIGTERM | 尽可能终止进程 |
| 17 | SIGSTOP | 无条件停止进程,但不是终止进程 |
| 18 | SIGTSTP | 停止或暂停进程,但不终止进程 |
| 19 | SIGCONT | 继续运行停止的进程 |
默认情况下,bash shell会忽略收到的任何SIGQUIT (3)和SIGTERM (5)信号,正因为这样,交互式shell才不会被意外终止。但是bash shell会处理收到的SIGHUP (1)和SIGINT (2)信号:
- 如果bash shell收到了
SIGHUP信号,比如当你要离开一个交互式shell,它就会退出,但在退出之前,它会将SIGHUP信号传给所有由该shell所启动的进程(包括正在运行的shell脚本)。 - 通过
SIGINT信号,可以中断shell,Linux内核会停止为shell分配CPU处理时间。这种情况发生时,shell会将SIGINT信号传给所有由它所启动的进程,以此告知出现的状况。
6.1 生成信号
bash shell允许用键盘上的组合键生成两种基本的Linux信号,这个特性在需要停止或暂停失控程序时非常方便。
中断进程:组合键会生成
SIGINT信号,并将其发送给当前在shell中运行的所有进程。暂停进程:组合键会生成
SIGTSTP信号,停止shell中运行的任何进程。- 停止(stopping)进程跟终止(terminating)进程不同:停止进程会让程序继续保留在内存中,并能从上次停止的位置继续运行。
- 你可以在进程运行期间暂停进程,而无需终止它,尽管有时这可能会比较危险(比如,脚本打开了一个关键的系统文件的文件锁),但通常它可以在不终止进程的情况下使你能够深入脚本内部一窥究竟。
6.2 捕获信号
trap命令允许你来指定shell脚本要监看并从shell中拦截的Linux信号,如果脚本收到了trap命令中列出的信号,该信号不再由shell处理,而是交由本地处理。
trap命令的格式如下,在trap命令行上,你只要列出想要shell执行的命令,以及一组用空格分开的待捕获的信号(你可以用数值或Linux信号名来指定信号):
trap commands signals这里有个简单例子,展示了如何使用trap命令来忽略SIGINT信号,并控制脚本的行为:
$ cat test1.sh
#!/bin/bash
# Testing signal trapping
#
trap "echo ' Sorry! I have trapped Ctrl-C'" SIGINT
#
echo This is a test script
#
count=1
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
echo "This is the end of the test script"
#
$
$ ./test1.sh
This is a test script
Loop #1
Loop #2
Loop #3
Loop #4
Loop #5
^C Sorry! I have trapped Ctrl-C
Loop #6
Loop #7
Loop #8
^C Sorry! I have trapped Ctrl-C
Loop #9
Loop #10
This is the end of the test script
$如果想要捕获shell脚本退出时的信号,可以通过如下设置:
$ cat test2.sh
#!/bin/bash
# Trapping the script exit
#
trap "echo Goodbye..." EXIT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
$
$ ./test2.sh
Loop #1
Loop #2
Loop #3
Loop #4
Loop #5
Goodbye...
$
$ ./test2.sh
Loop #1
Loop #2
Loop #3
^CGoodbye...
$6.3 修改/移除信号捕获
要想在脚本中的不同位置进行不同的捕获处理,只需重新使用trap命令:
$ cat test3.sh
#!/bin/bash
# Modifying a set trap
#
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
trap "echo ' I modified the trap!'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
$修改了信号捕获之后,脚本处理信号的方式就会发生变化。但如果一个信号是在捕获被修改前接收到的,那么脚本仍然会根据最初的trap命令进行处理:
$ ./test3.sh
Loop #1
Loop #2
Loop #3
^C Sorry... Ctrl-C is trapped.
Loop #4
Loop #5
Second Loop #1
Second Loop #2
^C I modified the trap!
Second Loop #3
Second Loop #4
Second Loop #5
$也可以删除已设置好的捕获,只需要在trap命令与希望恢复默认行为的信号列表之间加上破折号--就行了:
$ cat test3b.sh
#!/bin/bash
# Removing a set trap
#
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
#
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
# Remove the trap
trap -- SIGINT
echo "I just removed the trap"
#
count=1
while [ $count -le 5 ]
do
echo "Second Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
#
$ ./test3b.sh
Loop #1
Loop #2
Loop #3
Loop #4
Loop #5
I just removed the trap
Second Loop #1
Second Loop #2
Second Loop #3
^C
$7. 调整优先级
在多任务操作系统中(Linux就是),内核负责将CPU时间分配给系统上运行的每个进程,调度优先级(scheduling priority)决定了内核分配给进程的CPU时间(相对于其他进程)。在Linux系统中,由shell启动的所有进程的调度优先级默认都是相同的。
调度优先级是个整数值,从-20(最高优先级)到+19(最低优先级)。默认情况下,bash shell以优先级0来启动所有进程。
7.1 nice 命令
nice命令允许你设置命令启动时的调度优先级,可以使用ps命令的NI列验证:
$ nice -n 10 ./test4.sh > test4.out &
[1] 4973
$
$ ps -p 4973 -o pid,ppid,ni,cmd
PID PPID NI CMD
4973 4721 10 /bin/bash ./test4.sh
$nice命令阻止普通系统用户来提高命令的优先级,如下,注意指定的作业的确运行了,但是试图使用nice命令提高其优先级的操作却失败了:
$ nice -n -10 ./test4.sh > test4.out &
[1] 4985
$ nice: cannot set niceness: Permission denied
[1]+ Done nice -n -10 ./test4.sh > test4.out
$7.2 renice 命令
renice 命令允许你改变系统上已运行命令的优先级:
$ ./test11.sh &
[1] 5055
$
$ ps -p 5055 -o pid,ppid,ni,cmd
PID PPID NI CMD
5055 4721 0 /bin/bash ./test11.sh
$
$ renice -n 10 -p 5055
5055: old priority 0, new priority 10
$
$ ps -p 5055 -o pid,ppid,ni,cmd
PID PPID NI CMD
5055 4721 10 /bin/bash ./test11.sh
$和nice命令一样,renice命令也有一些限制:
- 只能对属于你的进程执行
renice; - 只能通过
renice降低进程的优先级; root用户可以通过renice来任意调整进程的优先级。
如果想完全控制运行进程,必须以root账户身份登录或使用sudo命令。
8. 定时任务
8.1 at 命令:一次性执行
at命令允许指定Linux系统何时运行脚本,其会将作业提交到队列中,指定shell何时运行该作业。at的守护进程atd会以后台模式运行,检查作业队列来运行作业,大多数Linux发行版会在启动时运行此守护进程。
atd守护进程会检查系统上的一个特殊目录(通常位于/var/spool/at)来获取用at命令提交的作业。默认情况下,atd守护进程会每60秒检查一下这个目录,有作业时,atd守护进程会检查作业设置运行的时间,如果时间跟当前时间匹配,atd守护进程就会运行此作业。
基本使用
at命令的基本格式非常简单:
at [-f filename] time- 默认情况下,
at命令会将STDIN的输入放到队列中,你可以用-f参数来指定用于读取命令(脚本文件)的文件名。 time参数指定了Linux系统何时运行该作业。如果你指定的时间已经错过,at命令会在第二天的那个时间运行指定的作业。
如下为一个简单示例:
$ cat test13.sh
#!/bin/bash
# Test using at command
#
echo "This script ran at $(date +%B%d,%T)"
echo
sleep 5
echo "This is the script's end..."
#
$ at -f test13.sh now
job 7 at 2015-07-14 12:38
$at命令会显示分配给作业的作业号以及为作业安排的运行时间;-f选项指明使用哪个脚本文件;now指示at命令立刻执行该脚本。
作业队列与优先级
在你使用at命令时,该作业会被提交到作业队列(job queue),作业队列会保存通过at命令提交的待处理的作业。针对不同优先级,存在26种不同的作业队列。作业队列通常用小写字母a~z和大写字母A~Z来指代。作业队列的字母排序越高,作业运行的优先级就越低(更高的nice值),默认情况下,at的作业会被提交到a作业队列,如果想以更高优先级运行作业,可以用-q参数指定不同的队列字母。
atq命令可以查看系统中有哪些作业在等待:
$ at -M -f test13b.sh teatime
job 17 at 2015-07-14 16:00
$
$ at -M -f test13b.sh tomorrow
job 18 at 2015-07-15 13:03
$
$ at -M -f test13b.sh 13:30
job 19 at 2015-07-14 13:30
$
$ at -M -f test13b.sh now
job 20 at 2015-07-14 13:03
$
$ atq
20 2015-07-14 13:03 = Christine
18 2015-07-15 13:03 a Christine
17 2015-07-14 16:00 a Christine
19 2015-07-14 13:30 a Christine
$删除等待作业
一旦知道了哪些作业在作业队列中等待,就能用atrm命令来删除等待中的作业,只要指定想要删除的作业号就行了。不过只能删除你提交的作业,不能删除其他人的。如下:
$ atq
18 2015-07-15 13:03 a Christine
17 2015-07-14 16:00 a Christine
19 2015-07-14 13:30 a Christine
$
$ atrm 18
$
$ atq
17 2015-07-14 16:00 a Christine
19 2015-07-14 13:30 a Christine
$at 作业的输出
当作业在Linux系统上运行时,显示器并不会关联到该作业。取而代之的是,Linux系统会将提交该作业的用户的电子邮件地址作为STDOUT和STDERR。任何发到STDOUT或STDERR的输出都会通过邮件系统发送给该用户。然而,使用e-mail作为at命令的输出极其不便。at命令利用sendmail应用程序来发送邮件。如果你的系统中没有安装sendmail,那就无法获得任何输出!因此在使用at命令时,最好在脚本中对STDOUT和STDERR进行重定向。
8.2 crontab 命令:定期执行
Linux系统使用cron程序来安排要定期执行的作业。
cron 时间表
cron程序会在后台运行并检查一个特殊的表(被称作cron时间表),以获知已安排执行的作业。
cron时间表采用一种特别的格式来指定作业何时运行,其格式如下:
min hour dayofmonth month dayofweek commandcron时间表允许你用特定值、取值范围(比如1~5)或者是通配符(星号)来指定条目,如
15 10 * * * command;cron程序会用提交作业的用户账户运行该脚本,因此,需要注意相关的用户权限;
cron时间表的图解:
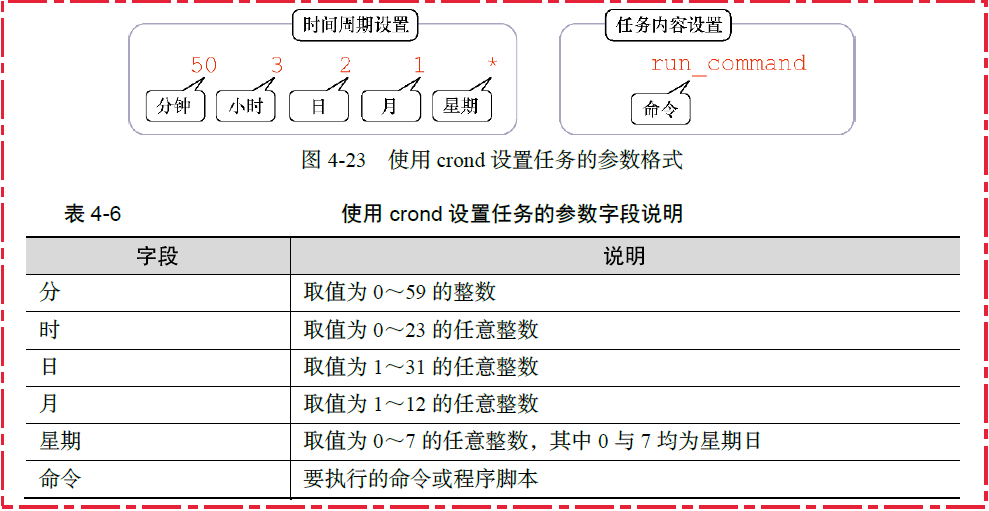
crontab 命令
每个系统用户(包括root用户)都可以用自己的cron时间表来运行安排好的任务。Linux提供了crontab命令来处理cron时间表。要列出已有的cron时间表,可以用-l选项。
| 命令 | 作用 |
|---|---|
crontab -l | 列出已有的cron时间表 |
crontab -e | 创建/编辑定期任务 |
预置的 cron 脚本目录
如果你创建的脚本对精确的执行时间要求不高,用预配置的cron脚本目录会更方便。有4个基本目录:hourly、daily、monthly和weekly:
$ ls /etc/cron.*ly
/etc/cron.daily:
cups makewhatis.cron prelink tmpwatch
logrotate mlocate.cron readahead.cron
/etc/cron.hourly:
0anacron
/etc/cron.monthly:
readahead-monthly.cron
/etc/cron.weekly:
$比如,如果脚本需要每天运行一次,只要将脚本复制到daily目录,cron就会每天执行它。
anacron 程序
cron程序的唯一问题是它假定Linux系统是7×24小时运行的,除非将Linux当成服务器环境来运行,否则此假设未必成立。
如果某个作业在cron时间表中安排运行的时间已到,但这时候Linux系统处于关机状态,那么这个作业就不会被运行。当系统开机时,cron程序不会再去运行那些错过的作业。要解决这个问题,许多Linux发行版还包含了anacron程序。
如果anacron知道某个作业错过了执行时间,它会尽快运行该作业。这意味着如果Linux系统关机了几天,当它再次开机时,原定在关机期间运行的作业会自动运行。
以后再说吧......
更新日志
899db-于eedbf-于d9dfd-于8aa7f-于47fa5-于c9215-于75141-于730b3-于01ff0-于43146-于0f4de-于95cef-于eadfa-于5617f-于d1aef-于446f8-于0e6a3-于ac5e8-于c1c12-于