流
谓词:一个返回
boolean值的函数。
1. 介绍
1.1 感性认知
流是 Java API 的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。
在认识流的初始阶段,可以把它们看作遍历数据集的高级迭代器。
流还可以透明地并行处理,你无需写任何多线程代码了!
Java7 的写法:
List<Dish> lowCaloricDishes = new ArrayList<>(); for (Dish d : menu) { if (d.getCalories() < 400) { lowCaloricDishes.add(d); } } // 用匿名类对菜肴排序 Collections.sort(lowCaloricDishes, new Comparator<Dish>() { public int compare(Dish d1, Dish d2) { return Integer.compare(d1.getCalories(), d2.getCalories()); } }); // 处理排序后的菜名列表 List<String> lowCaloricDishesName = new ArrayList<>(); for (Dish d : lowCaloricDishes) { lowCaloricDishesName.add(d.getName()); }在这段代码中,使用了一个垃圾变量
lowCaloricDishes,它唯一的作用就是作为一次性的中间容器。而在 Java8 中,实现的细节被放在它本该归属的库里了。Java8 的写法:
import static java.util.Comparator.comparing; import static java.util.stream.Collectors.toList; List<String> lowCaloricDishesName = menu.stream() .filter(d -> d.getCalories() < 400) // 选出300卡路里以下的菜肴 .sorted(comparing(Dish::getCalories)) // 按照卡路里排序 .map(Dish::getName) // 提取菜肴名称 .collect(toList()); // 所有名称保存在List中更进一步地,如果希望利用多核架构并执行这段代码,只需要把
stream()换成parallelStream()即可:List<String> lowCaloricDishesName = menu.parallelStream() .filter(d -> d.getCalories() < 400) // 选出300卡路里以下的菜肴 .sorted(comparing(Dish::getCalories)) // 按照卡路里排序 .map(Dish::getName) // 提取菜肴名称 .collect(toList()); // 所有名称保存在List中因为
filter, sorted, map, collect等操作是与具体线程模型无关的高层次构件,所以它们的内部实现可以是单线程的,也可以透明地充分利用你的多核架构,这些 Stream API 都替你做好了!
Java8 新方式的好处是:
- 声明性——更简洁、更易读
- 可复合(链式结构)——更灵活
- 可并行——性能更好
1.2 严谨认知
流是从支持数据处理操作的源生成的元素序列。
- 元素序列:集合讲的是数据,流讲的是计算。
- 源:流会使用一个提供数据的源,如集合、数组、输入/输出资源。
- 数据处理操作:流的数据处理功能类似于数据库的操作,以及函数式编程语言中的常用操作,如
filter, map, reduce, find, match, sort等。流操作有两个重要特点:流水线:很多流本身会返回一个流,这样多个操作可以链接起来,形成一个大的流水线;
内部迭代:与使用迭代器显示迭代的集合不同,流的迭代操作是在背后进行的。
/* 下面这段代码来显示集合的for-each迭代、集合的迭代器迭代、流的迭代 */ // 集合:使用for-each循环外部迭代 List<String> names = new ArrayList<>(); for (Dish d : menu) { names.add(d.getName()); } // 集合:用背后的迭代器做外部迭代 List<String> names = new ArrayList<>(); Iterator<Dish> iterator = menu.iterator(); while (iterator.hasNext()) { Dish d = iterator.next(); names.add(d.getName()); } // 流:内部迭代 List<String> names = menu.stream() .map(Dish::getName) .collect(Collectors.toList());
流与集合都可以让我们转换和获取数据,但它们之间存在着显著的差异:
- 流并不存储其元素:这些元素可能存储在底层的集合中,或者是按需生成的。
- 流的操作不会修改其数据源:如,
filter方法不会从流中移除元素,而是会生成一个新的流,其中不包含被过滤掉的元素。 - 流的操作是尽可能惰性执行的:这意味着直到需要结果时,操作才会执行。
2. 流操作
中间操作如 filter, sorted 等会返回另一个流,这个多个操作可以连接起来形成一个查询,而且,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒,这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。
2.1 中间操作
这个结果很有意思,其中的好几种优化利用了流中间操作的延迟性质:

| 中间操作 | 作用 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
|---|---|---|---|---|
| filter | 用谓词筛选过滤 | Stream<T> | Predict<T> | T -> boolean |
| distinct | 筛选各异的元素(顺序不变) | Stream<T> | ||
| skip | 跳过前 n 个元素,如果流中元素不足 n,返回一个空流 | long | ||
| limit | 截断流。 注意limit也可以用在无序流上,如源为Set的流,此时limit的结果也是无序的 | Stream<T> | long | |
| map | 对流中的每一个元素应用函数 | Stream<R> | Function<T, R> | T -> R |
| flatMap | 流的扁平化——该方法与map不同的是,让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。 | Stream<R> | Function<T, Streeam<R>> | T -> Stream<R> |
| sorted | Stream<T> | Comparator<T> | (T, T) -> int | |
| takeWhile | ||||
| dropWhile |
map与flatMap的比较
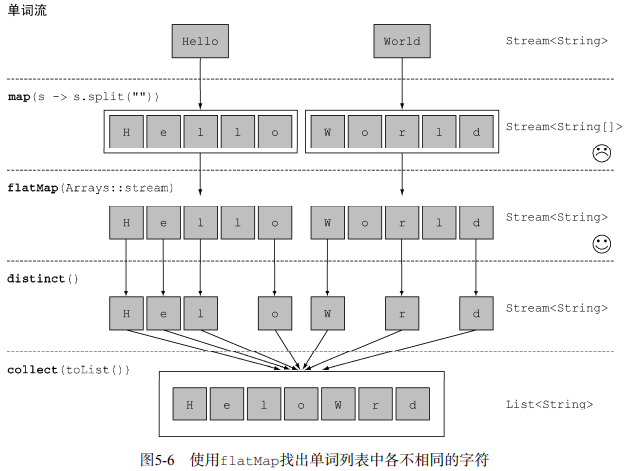
2.2 终端操作
终端操作会从流的流水线生成结果,其结果不再是流,可以为List, Integer, void等任何其他值。
| 终端操作 | 作用 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
|---|---|---|---|---|
| max | Optional<T> | Comparator<? super T> | ||
| min | Optional<T> | Comparator<? super T> | ||
| anyMatch | boolean | Predict<? super T> | T -> boolean | |
| noneMatch | boolean | Predict<? super T> | T -> boolean | |
| allMatch | boolean | Predict<? super T> | T -> boolean | |
| findAny | Optional<T> | |||
| findFirst | Optional<T> | |||
| forEach | 消费流中的每个元素并对其应用Lambda | void | Consumer<? super T> | T -> void |
| collect | 使用收集器把流收集成一个集合,如List, Map甚至是Interger | R | Collector<? super T, A, R> | |
| reduce | “约简操作”,使用Lambda反复结合每个元素,直到流被归约成一个值。 reduce还有一个重载的变化,它不接受初始值,返回一个Optional对象 | Optional<T> | BinaryOperator<T> | (T, T) -> T |
| count | 返回流中元素的个数 | long | ||
| toArray | Object[] | |||
| toArray | A[] | IntFunction<A[]> |
findAny相比findFirst显然更容易执行并行化。
3. 数值流
3.1 数值流API
为避免暗含的装箱成本,Stream API提供了原始类型流特化,专门支持处理数值流的方法。具体而言,包含三个原始类型流特化接口:
| 原始类型流特化接口 | 生成方法(和map方法相同) | OPtional原始类型特化版本 |
|---|---|---|
| IntStream | mapToInt | OptionalInt |
| DoubleStream | mapToDouble | OptionalDouble |
| LongStream | mapToLong | OptionalLong |
如果想要把特化流转换回非特化流,可以使用装箱方法boxed()。例如:
// 将Stream转换为数值流
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
// 将数值流转换为Stream
Stream<Integer> stream = intStream.boxed();关于Optional原始类型特化版本的使用,例如要找到IntStream中的最大元素,可以调用max方法,它会返回一个OptionalInt:
OptionalInt maxCalories = menu.stream()
.mapToInt(Dish::getCalories)
.max();
// 此时,如果没有最大值的话,就可以显示处理OptionalInt去定义一个默认值了:
int max = maxCalories.orElse(1);3.2 生成数值范围
Java8在IntStream和LongStream中提供了两个静态方法,可以用来生成数值范围:
- range:左闭右开区间
- rangeClosed:闭区间
4. Stream接口的静态方法
除了前述的中间/终端操作,Stream接口中还含有若干静态方法来创建流:
| 静态方法 | 作用 |
|---|---|
<T> Stream<T> of(T... values) | 产生一个元素为给定值的流 |
<T> Stream<T> empty() | 产生一个不包含任何元素的流 |
<T> Stream<T> ofNullable(T t) | 如果t为null,返回一个空流,否则返回包含t的流 |
<T> Stream<T> generate(Supplier<T> s) | 产生一个无限流,它的值是通过反复调用函数s而构造的 |
<T> Stream<T> iterate(T seed, UnaryOperator<T> f) | 产生一个无限流,它的元素包含seed,它的元素包含seed、在seed上调用f产生的值、在前一个元素上调用f产生的值,等等。 |
<T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> f) | 同上,但在碰到第一个不满足hasNext谓词的元素时终止 |
<T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) | 产生一个流,它的元素是a的元素后面跟着b的元素 |
5. 流的收集器
流的终端操作collect实际上是一个归约操作,将流中的元素累积成一个汇总结果,该归约操作通过Collector接口来参数化。此外Java8还提供了一个名为Collectors的工具类,其中有很多静态工厂方法可以方便地创建常见的收集器。
注意,这些概念不要跟Java集合体系的根接口
Collection混淆了。
5.1 Collector接口
Collector接口包含了一系列方法,为实例具体的归约操作(即收集器)提供了范本。
你也可以为Collector接口提供自己的实现,从而自由地创建自定义归约操作。Collector接口中声明了5个方法:
其中前4个都会返回一个会被collect方法调用的函数,而第5个方法则提供了一系列特征,也就是一个提示列表,告诉collect方法在执行收集操作的时候可以应用哪些优化(比如并行化)。
public interface Collector<T, A, R> {
Supplier<A> supplier(); // 建立新的可变容器
BiConsumer<A, T> accumulator(); // 将元素添加到上述结果的可变容器
BinaryOperator<A> combiner(); // 接收两个部分结果的容器并把它们合并
Function<A, R> finisher(); // 对上述结果容器A应用最后转换,转换为R类型的容器
Set<Characteristics> characteristics(); // 返回一个说明此Collector的特征的集,这个集需要是不可变的
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
// ...
}
public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A, R> finisher,
Characteristics... characteristics) {
// ...
}
/**
* Characteristics indicating properties of a {@code Collector}, which can
* be used to optimize reduction implementations.
*/
enum Characteristics {
CONCURRENT,
UNORDERED,
IDENTITY_FINISH
}
}5.2 Collectors类
5.2.1 纲述
以下各个静态工厂方法用来创建用于收集若干类型的收集器:
| 静态工厂方法 | 收集类型及作用 |
|---|---|
<T> Collector<T, ?, List<T>> toList() | List<T>,把流中所有项目收集到一个List |
<T> Collector<T, ?, Set<T>> toSet() | Set<T>,把流中所有项目收集到一个Set,删除重复项 |
<T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) | Collection<T>,把流中所有项目收集到给定的供应源创建的集合 |
Collector<CharSequence, ?, String> joining() | String,连接对流中的每个项目调用toString方法所生成的字符串 |
<T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) | 归约操作产生的类型。从一个作为累加器的初始值开始,利用BinaryOperator与流中的元素逐个结合,从而将流归约为单个值 |
<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher) | 转换函数返回的类型。包裹另一个收集器,对其结构应用转换函数 |
<T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) | Map<K, List<T>>,根据项目的一个属性的值对流中的项目作分组,并将属性值作为结果Map的键 |
<T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) | Map<Boolean, List<T>>,根据对流中每个项目应用谓词的结果来对项目进行是和否的分区 |
<T> Collector<T, ?, Long> counting() | Long,计算流中元素的个数 |
<T> Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper) | Integer,对流中项目的一个整数属性求和 |
<T> Collector<T, ?, Double> averagingInt(ToIntFunction<? super T> mapper) | Double,计算流中项目Integer属性的平均值 |
<T> Collector<T, ?, IntSummaryStatistics> summarizingInt(ToIntFunction<? super T> mapper) | IntSummaryStatistics,惧关于流中项目Integer属性的统计值,如最大、最小、总和、平均值 |
<T> Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator) | Optional<T>,一个包裹了流中按照给定比较器选出的最大元素的Optional,或如果流为空则为Optional.empty() |
<T> Collector<T, ?, Optional<T>> minBy(Comparator<? super T> comparator) | Optional<T>,与上反 |
5.2.2 Map类型
对于Map类型,Collectors有如下静态工厂方法用于创建收集器:
几乎有同样版本的toConcurrentMap版本。
<T, K, U> Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper)<T, K, U> Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction)<T, K, U, M extends Map<K, U>> Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier)
5.2.3 groupingBy的下游收集器
groupingBy方法会产生一个映射表,它的每个值都是一个列表,如果现在想要以某种方式来处理这些列表,就需要提供一个“下游收集器”。例如,如果想要获得集而不是列表,那么可以使用Collectors.toSet收集器:
Map<String, Set<Locale>> countryToLocalSet = locales.collect(groupingBy(Locale::getCountry, Collectors.toSet()));实际上,只要理解了Collector接口,理解所谓下游收集器便是顺理成章的事了。
6. 流的并行化
并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
对于流,顺序流与并行流之间的转换非常容易:
- 顺序流 -> 并行流:
parallel() - 并行流 -> 顺序流:
sequential()
本节通过示例来说明:
long n = 100000000L;
Long sum;
// 顺序流
sum = Stream.iterate(1L, i -> i + 1)
.limit(n)
.reduce(0L, Long::sum);
System.out.println("顺序流:" + sum);
// 并行流
sum = Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel() // 将流转化为并行流,使得归约过程(求和)并行运行
.reduce(0L, Long::sum);
System.out.println("并行流:" + sum);对于上面的并行流,Stream在内部分成了几块,因而可以对不同的块独立并行进行归纳操作,最后进行汇总,如下图:
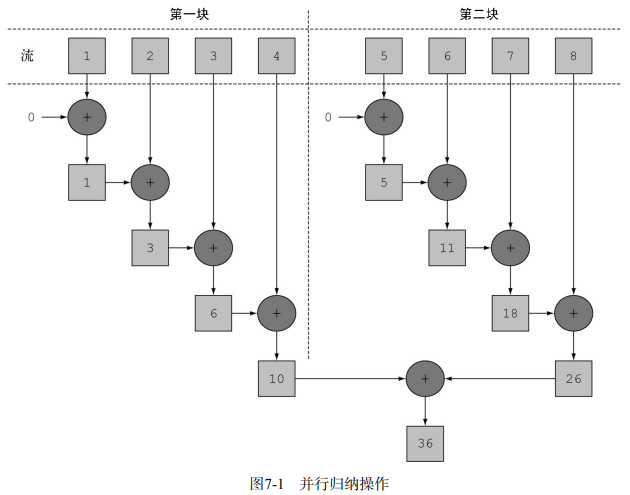
值得一提的是,在现实中,对顺序流调用parallel方法并不意味着流本身有任何实际的变化,它在内部其实只是设了一个boolean标志,表示你想让调用parallel之后进行的所有操作都并行执行。类似地,你只需要对并行流调用sequential方法就可以把它变成顺序流。
需要注意的是,你可能以为能够把parallel和sequential两个方法结合起来,从而更细化地控制在遍历流时哪些操作要并行执行,哪些要顺序执行,但这样是不行的,因为这两个方法的最后一次调用会影响整个流水线。也就是行,下面的流水线其实是并行执行的:
// 这段代码相当于只有出现在最后的那个parallel()生效
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();不要指望通过将所有的流都转换为并行流就能够加速操作,要牢记下面几条:
- 并行化会导致大量的开销,只有面对非常大的数据集才划算;
- 只有在底层的数据源可以被有效地分割为多个部分时,将流并行化才有意义;
- 并行流使用的线程池可能会因诸如文件I/O或网络访问这样的操作被阻塞而饿死。
另:Optional类
Optional<T>类(java.util.Optional)是一个容器类,代表一个值存在或不存在。
| 方法 | 作用 |
|---|---|
| isPresent() | Optional包含值的时候返回true,否则为false |
| ifPresent(Consumer<T> block) | 在Optional包含值的时候执行给定代码块 |
| T get() | 在值存大时返回值,否则抛出一个NoSuchElement异常 |
| T orElese(T other) | 在值存在时返回值,否则返回一个默认值 |
更新日志
b5553-于899db-于eedbf-于c9215-于75141-于730b3-于cad65-于c2b34-于0e6a3-于99a3f-于09561-于