Java集合概述
1. Java集合体系
Java 集合大致可分为 Set, List, Queue, Map 四种体系,集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类,所有的集合类都位于 java.util 包下。
为了处理多线程环境下的并发安全问题,Java 在 java.util.concurrent 包下也提供了一些多线程支持的集合类。
集合类和数组不一样,数组元素可以是基本类型的值/对象,而集合里只能保存对象,即引用类型(虽然集合里不能放基本类型的值,但 Java 支持自动装箱)。
1.1 接口体系
Java集合框架为不同类型的集合定义了大量接口,如下:
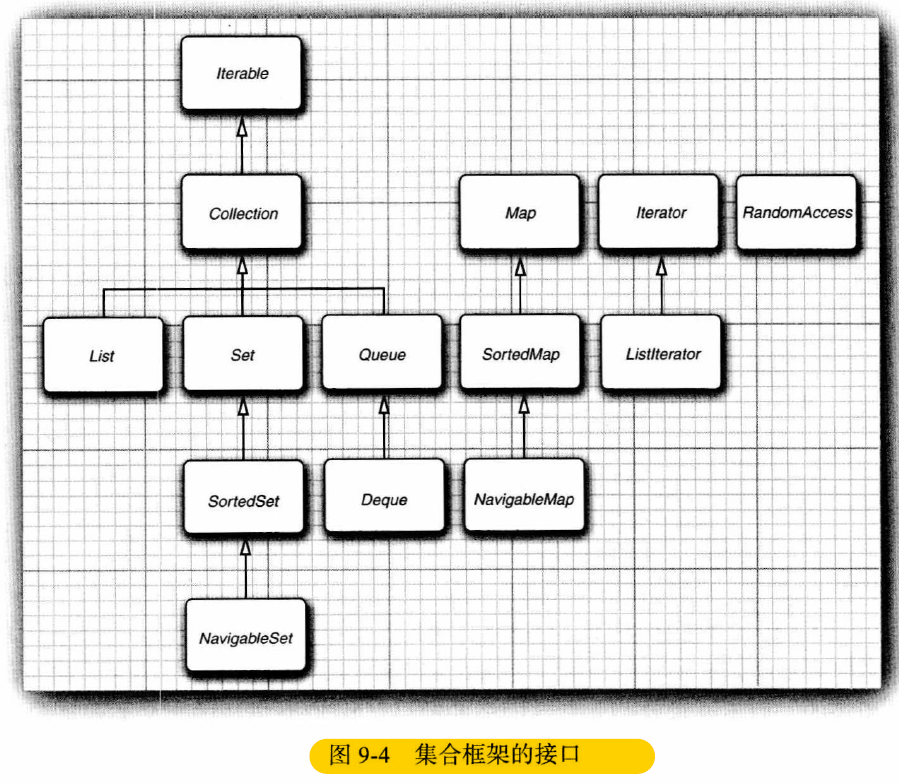
集合有两个基本接口:Collection和Map。
对于集合中的有序集合,实际上有两种,其性能开销有很大差异:
由数组支持的有序集合可以快速地随机访问,因此适合使用
get方法并提供一个整数索引来访问;与之不同,链表尽管也是有序的,但是随机访问很慢,所以最好使用迭代器来遍历。如果原先提供两个接口就会容易一些了,很遗憾的是,Java 集合框架在这个方面设计得不好。
为了避免对链表使用随机访问操作,Java1.4 引入了一个标记接口
RandomAccess,这个接口不包含任何方法,不过可以用它来测试一个特定的集合是否支持高效的随机访问:if (c instanceof RandomAccess) { // use random access algorithm } else { // use sequential access algorithm }
Set 接口实际上等同于 Collection 接口,不过其方法的行为有更严谨的定义,建立 Set 接口的目的也是为了从概念上严格区分这两种含义不同的集合。
1.2 具体集合类
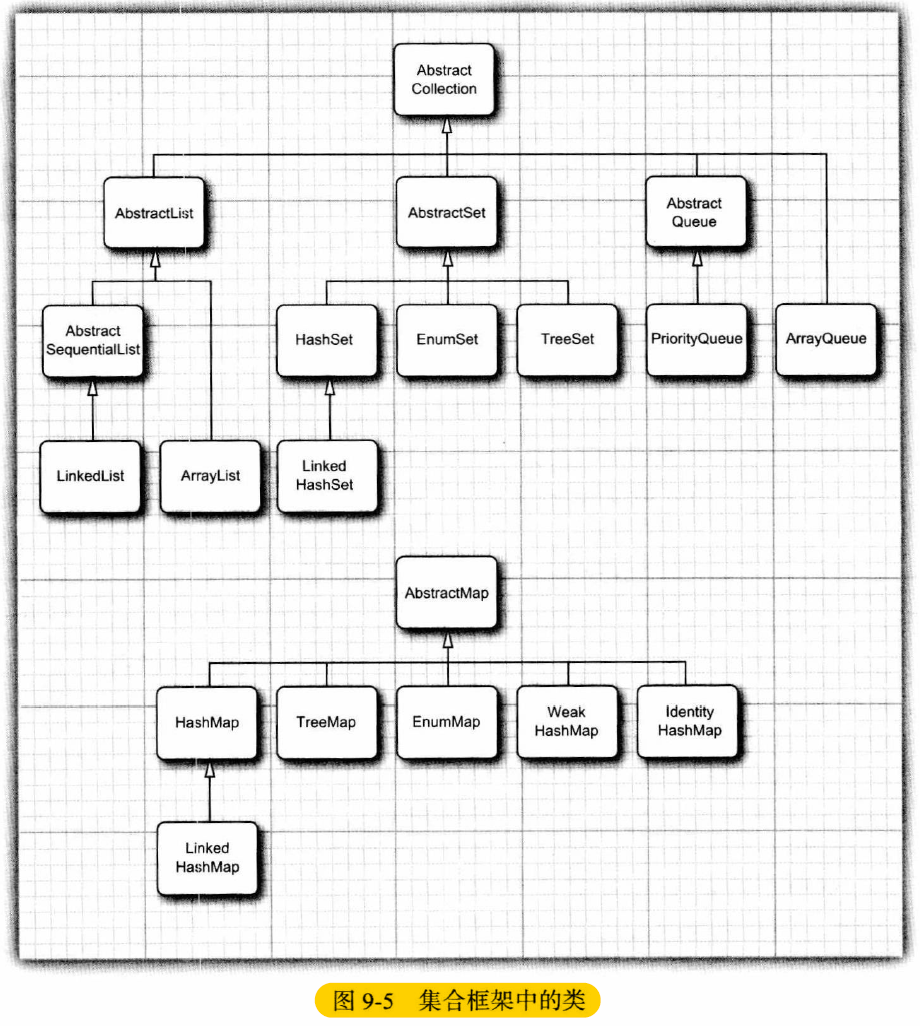
在 Java 程序设计语言中,所有链表实际上都是双向链接的,即每个节点还存放着其前驱的引用。
2. Collection接口
Collection 接口是 List, Set, Queue 接口的父接口。
2.1 Collection的方法
Collection<E>接口里定义了如下操作集合元素的方法:
| 方法 | 作用 |
|---|---|
int size() | 返回集合里元素的个数 |
Iterator<E> iterator() | 返回一个Iterator对象,用于遍历集合里的元素 |
boolean isEmpty() | 判断集合是否为空(集合长度为0:true,否则:false) |
boolean contains(Object o) | 判断集合里是否包含指定元素 |
boolean containsAll(Collection<?> c) | 判断集合里是否包含集合c里的所有元素 |
boolean add(Object o) | 向集合里添加一个元素,添加成功则返回true |
boolean addAll(Collection<? extends E> c) | 添加集合c里的所有元素,添加成功则返回true |
boolean remove(Object o) | 删除指定元素,若集合包含多个该元素,只删除第一个 |
boolean removeAll(Collection<?> c) | 删除集合c里包含的所有元素 |
default boolean removeIf(Predicate<? super E> filter) | 删除filter返回true的所有元素。如果这个调用改变了集合,则返回true。 |
void clear() | 清除集合里的所有元素,将集合长度变为0 |
boolean retainAll(Collection<?> c) | 只保留集合c里包含的元素,相当于求交集 |
Object[] toArray() | 返回这个集合中的对象的数组 |
T T[] toArray(T[] arrayToFill) |
当使用 System.out.println 方法来输出集合对象时,将输出 [ele1,ele2,…] 的形式,这是因为所有 Collection 实现类都重写了 toString() 方法,该方法一次性地输出集合中的所有元素。
为避免实现 Collection 接口的每一个类都要提供如此多的例行方法,Java类库提供了一类AbstractCollection,它保持基础方法size和iterator仍为抽象方法,但是为实现者实现了其他实例方法。
2.2 Collection的遍历
2.2.1 借助Iterable遍历集合
Java 为 Iterable 接口新增了一个 forEach(Consumer action) 默认方法,其参数类型是一个函数式接口,而 Iterable 接口是 Collection 接口的父接口,因此 Collection 集合可直接调用该方法;
当程序调用 Iterable 的 forEach(Consumer action) 遍历集合元素时,程序会依次将集合元素传给 Consumer 的 accept(T t) 方法。
import java.util.*;
public class CollectionEach {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("Java EE");
books.add("Java SE");
books.add("Java ME");
// 调用forEach()方法遍历集合
books.forEach(obj -> System.out.println(obj));
}
}2.2.2 使用Iterator遍历集合元素
直接遍历:
import java.util.*; public class IteratorTest { public static void main(String[] args) { Collection books = new HashSet(); books.add("Java EE"); books.add("Java SE"); books.add("Java ME"); // 获取books对应的迭代器 Iterator it = books.iterator(); while (it.hasNext()) { // it.next()返回的是Object类型,因此需要强制类型转换 String book = (String) it.next(); System.out.println(book); if (book.equals("Java ME")) { // 删除上一次next()方法返回的元素 it.remove(); } // 对book变量赋值,不会改变集合元素本身 book = "666666"; } System.out.println(books); } }使用 Lambda 表达式:
import java.util.*; public class IteratorTest { public static void main(String[] args) { Collection books = new HashSet(); books.add("Java EE"); books.add("Java SE"); books.add("Java ME"); // 获取books对应的迭代器 Iterator it = books.iterator(); // 使用Lambda表达式遍历 it.forEachRemaining(obj -> System.out.println(obj)); } }
2.2.3 使用foreach循环遍历
foreach 循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,因此在 foreach 循环中修改迭代变量的值也没有任何实际意义。
foreach 循环迭代访问集合元素时,该集合的结构也不能被改变,否则将引发 ConcurrentModificationException 异常。
import java.util.*;
public class ForeachTest {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("Java EE");
books.add("Java SE");
books.add("Java ME");
for (Object obj : books) {
// 此处的book变量也不是集合元素本身
String book = (String) obj;
System.out.println(book);
if (book.equals("Java ME")) {
// 下面会引发java.util.ConcurrentModificationException异常
books.remove(book);
}
}
System.out.println(books);
}
}2.3 Collection的流式API
Java 8 还新增了 Stream, IntStream, LongStream, DoubleStream 等流式API,支持串行和并行聚集操作的元素。
- 其中
Stream是一个通用的流接口,而IntStream, LongStream, DoubleStream则代表元素类型为int, long, double的流。 - Java8 还为上面每个流式API提供了对应的
Builder,例如Stream.Builder, IntStream.Builder, LongStream.Builder, DoubleStream.Builder,开发者可以通过这些Builder来创建对应的流。
独立使用 Stream 的步骤如下:
使用
Stream或XxxStream的builder()类方法创建该Stream对应的Builder;重复调用
Builder的add()方法向该流中添加多个元素;调用
Builder的build()方法获取对应的Stream;调用
Stream的聚集方法。
对于大部分聚集方法而言,每个 Stream 只能执行一次(有点类似“Python迭代器”?),如下程序:
class IntStreamTest {
public static void main(String[] args) {
IntStream is = IntStream.builder().add(20).add(13).add(-2).add(18).build();
// 注意:下面调用聚集方法的代码每次运行只能执行一次
// 基本聚集函数
System.out.println(is.max().getAsInt());
System.out.println(is.min().getAsInt());
System.out.println(is.sum());
System.out.println(is.count());
System.out.println(is.average());
// is所有元素的平方是否都大于20
System.out.println(is.allMatch(ele -> ele * ele > 20));
// is是否包含任何元素的平方大于20
System.out.println(is.anyMatch(ele -> ele * ele > 20));
// 将is映射成一个新Stream,新Stream的每个元素是原Stream元素的2倍+1
IntStream newIs = is.map(ele -> ele * 2 + 1);
// 使用方法引用的方式来遍历集合元素
newIs.forEach(System.out::println); // 输出41 27 -3 37
}
}Stream 提供了大量的方法进行聚集操作,这些方法既可以是“中间的”(intermediate),也可以是“末端的”(terminal)。
中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法,如上面的
map()方法就是中间方法,中间方法的返回值是另外一个流;方法 作用 filter(Predicate predicate)过滤 Stream中所有不符合predicate的元素mapToXxx(ToXxxFunction mapper)对流中的元素执行一对一的转换 peek(Consumer action)依次对每个元素执行一些操作,该方法返回的流与原有流包含相同的元素。该方法主要用于调试 distinct()该方法用于排序流中所有重复的元素(判断元素重复的标准是使用 equals()比较返回true)sorted()该方法用于保证流中的元素在后续的访问中处于有序状态 limit(long maxSize)该方法用于保证对该流的后续访问中最大允许访问的元素个数 末端方法:末端方法是对流的最终操作,当对某个
Stream执行末端方法后,该流将会被耗尽而无法再使用,如上面的sum(), count(), average()等方法都是末端方法。方法 作用 forEach(Consumer action)遍历流中所有元素,对每个元素执行 actiontoArray()将流中所有元素转换为一个数组 reduce()该方法有三个重载的版本,都用于通过某种操作来合并流中的元素 min()返回流中所有元素的最小值 max()返回流中所有元素的最大值 count()返回流中所有元素的数量 anyMatch(Predicate predicate)判断流中是否至少包含一个元素符合 Predicate条件allMatch(Predicate predicate)判断流中是否每个元素都符合 Predicate条件noneMatch(Predicate predicate)判断流中是否所有元素都不符合 Predicate条件findFirst()返回流中的第一个元素 findAny()返回流中的任意一个元素
Java8 允许使用流式 API 来操作集合,Collection 接口提供了一个 stream() 默认方法,该方法可返回该集合对应的流,接下来即可通过流式 API 来操作集合元素,由于 Stream 可以对集合元素进行整体的聚集操作,因此 Stream 极大地丰富了集合的功能。
3. Map接口
Java 集合框架不认为 Map 本身是一个集合,而其他语言的数据结构框架通常认为映射是一个键/值对的集合。
3.1 Map含义
Map 用于保存具有映射关系的数据,因此 Map 集合里保存着两组值,一组值用于保存 Map 的 key,另外一组值用于保存 Map 里的 value,key 和 value 都可以是任何引用类型的数据,但 key 不允许重复。
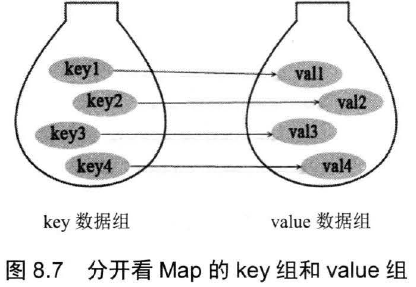
实际上,如果把 Map 里的 key 放在一起看,它们就组成了一个 Set 集合,故而所有对 Set 元素的要求基本就是对 Map 里的 key 的要求,Map 里 key 集和 Set 里的元素集的存储形式很像。
Map 子类和 Set 子类在名字上也惊人地相似,如下对比:
| Set | Map |
|---|---|
HashSet | HashMap |
LinkedHashSet | LinkedHashMap |
SortedSet(接口) | SortedMap(接口) |
TreeSet | TreeMap |
EnumSet | EnumMap |
实际上,从 Java 源码来看,Java 是先实现了 Map,然后通过包装一个所有 value 都为 null 的 Map 就实现了 Set 集合!
所有的 Map 实现类都重写了 toString() 方法,调用 Map 对象的 toString() 方法总是返回如下格式的字符串:{key1=value1, key2=value2, …}
3.2 哈希算法
有一种众所周知的数据结构,可以用于快速地查找对象,这就是散列表(hash table)。散列表为每个对象计算一个整数,称为散列码(hash code)。HashSet 和 HashMap 里用的都是 hash 算法。
桶
hash 算法中,hash 表里可以存储元素的位置叫做桶。
通常情况下单个桶里存储一个元素,此时具有最好的性能:hash 算法根据 hashCode 值计算出桶的存储位置,然后从桶中取出元素。
但 hash 表的状态是 open 的:在发生 hash 冲突的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。
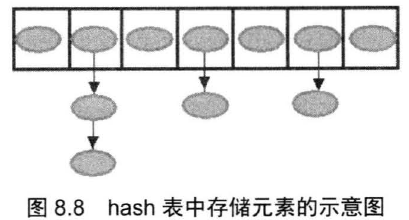
39 在 Java8 中,桶满时会从链表变为平衡二叉树。
因为使用 hash 算法来决定其元素的存储,HashSet 和 HashMap 的 hash 表具有如下属性:
- 容量(capacity):hash 表中桶的数量。
- 初始化容量(initial capacity):创建 hash 表时桶的数量。
HashSet和HashMap都允许在构造器中指定初始化容量。 - 尺寸(size):当前 hash 表中记录的数量。
- 负载因子(load factor):。
- 负载因子为0,表示空的 hash 表;
- 0.5表示半满的 hash 表,依此类推。
- 轻负载的 hash 表具有冲突少、适宜插入与查询的特点,但是使用
Iterator迭代元素时比较慢。
装填因子
装填因子,即 Java 给哈希表设定的一个负载极限。其是一个 0~1 的数值,其决定了 hash 表的最大填满程度。当 hash 表中的负载因子达到指定的“负载极限”时,hash 表会自动创建一个桶数成倍增加的表,并将所有元素插入到这个新表中,然后丢弃原来的表,这称为再散列(rehashing)。
HashSet 和 HashMap 的构造器允许指定一个负载极限,其默认值为 0.75。
如果大致知道最终会有多少个元素要插入到散列表中,就可以设置桶数。通常,将桶数设置为预计元素个数的 75%~150%。标准类库使用的桶数是2的幂,默认值为16。
如果开始就知道 HashSet 和 HashMap 会保存很多记录,可以在创建时就使用较大的初始化容量。
4. Iterator接口
Iterator 接口也是 Java 集合框架的成员,其主要用于遍历 Collection 集合中的元素,Iterator 对象也被称为迭代器。
4.1 方法
Iterator<E>接口里定义了4个方法:
| 方法 | 作用 |
|---|---|
boolean hasNext() | 被迭代的集合元素还未遍历完时返回true |
E next() | 返回集合里的下一个元素 |
void remove() | 删除集合里上一次next()方法返回的元素 |
void forEachRemaining(Consumer action) | 用于使用 Lambda 表达式来遍历集合元素 |
Java 集合类库中的迭代器与其他语言类库中的迭代器在概念上有着重要的区别。
- 如 C++ 的标准模板库,迭代器是根据数组索引建模的,如果给定一个迭代器,可以查找存储在指定位置上的元素,就像如果知道数组索引
i,就可以查找数组元素a[i]。 - 而在 Java 中,迭代器与之不同,查找操作与位置变更紧密耦合,查找一个元素的唯一方法是调用
next,而在执行查找操作的同时,迭代器的位置就会随之向前移动。 - 因为,可以认为 Java 迭代器位于两个元素之间。当调用
next时,迭代器就越过下一个元素,并返回刚刚越过的那个元素的引用。
4.2 注意事项
next 方法和 remove 方法调用之间存在依赖性。如果调用 remove 之前没有调用 next,将是不合法的。如果这样做,将会抛出一个 IllegalStateException 异常。
当使用 Iterator 迭代访问 Collection 集合元素时,Collection 集合里的元素不能被改变,只有通过 Iterator 的 remove() 方法删除上一次 next() 方法返回的集合元素才可以;否则会引发 java.util.CocurrentModificationException 异常。
import java.util.*;
public class IteratorErrorTest {
public static void main(String[] args) {
Collection books = new HashSet();
books.add("Java EE");
books.add("Java SE");
books.add("Java ME");
// 获取books集合对应的迭代器
Iterator it = books.iterator();
while (it.hasNext()) {
String book = (String) it.next();
System.out.println(book);
if (book.equals("Java ME")) {
// 使用Iterator迭代时不能修改集合元素,下面代码引发异常
books.remove(book);
}
}
}
}Iterator 迭代器采用的是快速失败(fail-fast)机制,一旦在迭代过程中检测到该集合已经被修改(通常是程序中的其他线程修改),程序立即引发异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
4.3 ListIterator接口
ListIterator 接口是 Iterator 的一个子接口。它定义了一个方法用于在迭代器位置前面增加一个元素:
void add(E element)ListIteraotr 接口还有两个方法,可以用来反向遍历链表:
E previous();
boolean hasPrevious();ListIteraotr 还有两个方法,可以告诉你当前位置的索引。这两个方法的效率非常高,因为有一个迭代器保持着当前位置的计数值:
int nextIndex();
int previousIndex();5. Collections工具类
Java 提供了一个操作 Set, List, Map 等集合的工具类:Collections,该工具类提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了将集合对象设置为不可变、对集合对象实现同步控制等方法。
详见后续章节描述。
6. 遗留的集合
从 Java 第1版问世以来,在 Java 集合框架出现之前已经存在大量“遗留的”容器类。这些容器类已经不推荐使用了,这里仅是简单提一嘴。
Hashtable类Enumeration接口Properties类:属性映射Stack类:栈BitSet类
更新日志
b5553-于899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于8bf74-于eb626-于0e6a3-于2979f-于73b32-于09561-于83bde-于016df-于