collections
关于collections标准库:
>>> help(collections)
Help on package collections:
NAME
collections
DESCRIPTION
This module implements specialized container datatypes providing
alternatives to Python's general purpose built-in containers, dict,
list, set, and tuple.
* namedtuple factory function for creating tuple subclasses with named fields
* deque list-like container with fast appends and pops on either end
* ChainMap dict-like class for creating a single view of multiple mappings
* Counter dict subclass for counting hashable objects
* OrderedDict dict subclass that remembers the order entries were added
* defaultdict dict subclass that calls a factory function to supply missing values
* UserDict wrapper around dictionary objects for easier dict subclassing
* UserList wrapper around list objects for easier list subclassing
* UserString wrapper around string objects for easier string subclassing
保留有限历史记录正是collections.deque()大显身手的时候。
在队列两端插入或删除元素时间复杂度都是
O(1),而在列表的开头插入或删除元素的时间复杂度为O(n)。
使用
deque(maxlen=N)构造函数会新建一个固定大小的队列,当新的元素加入并且这个队列已满的时候,最老的元素会自动被移除掉。
如果不设置最大列大小,那么就会得到一个无限大小队列,可以在队列的两端执行添加和弹出元素的操作。

找出一个序列中出现次数最多的元素,可以用collections.Counter类,它的一个most_common()方法直接给出了答案。
可用
update()方法更新计数:>>> morewords = ['why', 'are', 'you', 'not', 'looking', 'in', 'my', 'eyes'] >>> word_counts.update(morewords)


作为输入,
Counter对象可以接受任意的由可哈希(hashable)元素构成的序列对象。在底层实现上,一个
Counter对象就是一个字典,将元素映射到它再现的次数上。Counter实例一个鲜为人知的特性是它们可以很容易的跟数学运算操作相结合:

命名元组:
有时候我们不想通过下标来访问序列中的元素,因为这不易读,而希望通过名称来访问元素,此时可使用
collections.namedtuple()函数。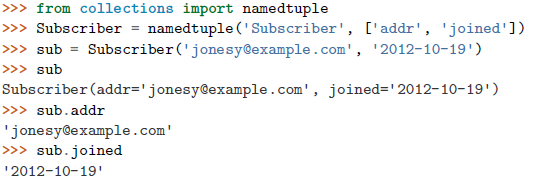
namedtuple的实例看起来像一个普通的类实例,但它跟元组类型是可交换的,支持所有的普通元组操作: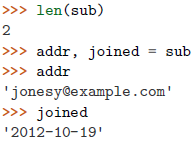
命名元组的另一个用途是作为字典的替代,因为字典存储需要更多的内存空间,如果你需要构建一个非常大的包含字典的数据结果,那么使用命名元组会更加高效,但是需要注意的是一个命名元组是不可更改的。(如果真的需要改变属性的值,可以使用命名元组实例的
_replace()方法,它会创建一个全新的命名元组并将对应的字段用新的值取代)最后,如果你的目标是定义一个需要更新很多实例属性的高效数据结构,那么命名元组并不是你的最佳选择,而应该考虑定义一个包含
__slots__方法的类。
要实现一种一个键对应多个值的字典(multidict),选择collections模块中的defaultdict。
defaultdict的一个特征是它会自动初始化每个key刚开始对应的值,所以你只需要关注添加元素的操作。需要注意的是,
defaultdict会自动为将要访问的键(就算当前字典中并不存在这样的键)创建映射实体。如果你不需要这样的特征,可以在一个普通的字典上使用setdefault()方法来代替。

因为每次调用都得创建一个新的初始值的实例(如上述的空列表[]),很多程序员觉得
setdefault()用起来有点别扭。
使用collections模块中的OrderedDict类可以控制一个字典中元素的顺序。
OrdereedDict内部维护着一个根据键插入顺序排序的双向链表,每当一个新的元素插入进来的时候,它会被放到链表的尾部,对于一个已经存在的键的重复赋值不会改变键的顺序。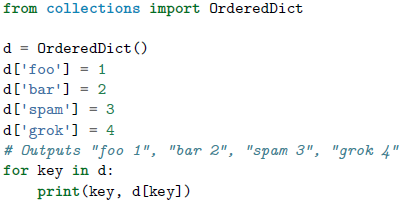
需要注意的是,一个
OrderedDict的大小是一个普通字典的两倍。
要将多个字典或者映射从逻辑上合并为一个单一的映射后执行某些操作,可使用collections模块中的ChainMap类。
一个
ChainMap接受多个字典并将它们在逻辑上变为一个字典,然后这些字典并不是真的合并了,而是只在内部创建了一个容纳这些字典的列表并重新定义了一些常见的字典操作来遍历这个列表,大部分字典操作都是可以正常使用的。ChainMap使用原来的字典,它自己不创建新的字典。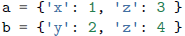

对于字典的更新或删除操作总是影响列表中的第一个字典:

使用collections模块的Iterable类可判断一个对象是否是可迭代对象:

使用collections模块的Iterator类判断一个对象是否是迭代器:

更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于ff50e-于