regex
1. 概要
正则表达式(Regular Expression, Regex) 用于文本内容的查找和替换。
Python 中所有正则表达式的函数都在标准库 re 中,故要 import re。
正则表达式的一般匹配步骤:
import re- 用
re.compile()函数将正则表达式的样式编译为一个Regex对象,可以用于匹配 - 向
Regex对象的search()方法传入想查找的字符串,它返回一个Match对象 - 调用
Match对象的group()方法,返回实际匹配文本的字符串。
向 re.compile()传入一个表示Regex的字符串值,它将返回一个 Regex 模式对象。注意:
这意味着,
re.compile()接收的是一个 Python 字符串,而由于 Python 字符串本身可能存在转义(且 Python 和 Regex 一样使用\来转义),即假设你传进去的字符串为'abc\\'(5 个字符),它在 Python 中表示的实际上是'abc\'(4 个字符),故re.compile()函数实际接收到的也是后者。所以为了保持一致性,最好在表示
Regex的字符串前均加上r来禁止 Python 转义,此后re.compile()接收到你传入的字符串后就会进行Regex的解析,即碰到''字符时将其视为Regex的转义符,以Regex规则来进行识别。
传递给 re.compile()的原始字符串中,\( 和 \) 转义字符将匹配实际的括号字符。

添加括号()将在正则表达式中创建分组,如(\d\d\d)-(\d\d\d-\d\d\d\d)。其中将第一对括号称为第 1 组,第二对括号是第 2 组。
Python 的 Regex 默认是贪心的,这表示在有二义的情况下,它们会尽可能匹配最长的字符串。可使用问号?来声明使用非贪心匹配,即匹配尽可能最短的字符串:
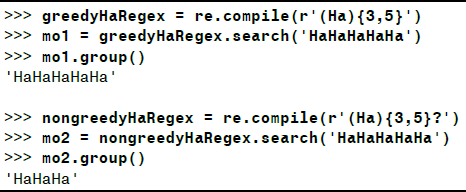
2. re.compile()函数
re.compile()的第二参数:
re.IGNORECASE或re.I: 让正则表达式匹配不区分大小写re.DOTALL: 结合使用.*与re.DOTALL,可以让句点字符匹配所有字符,包括换行字符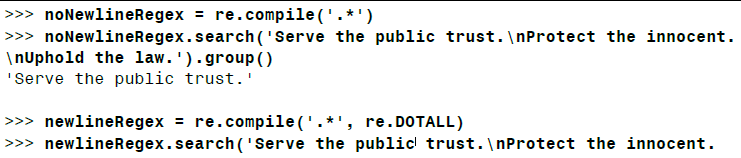

re.VERBOSE: 让 re.compile()忽略正则表达式字符串中的空白符和注释,从而可以管理复杂的正则表达式。Regex 中字符串的注释规则与 python 代码一样。


re.compile()函数只接受一个值作为它的第二个参数,即re.I, re.DOTALL, re.VERBOSE只能在函数中出现一个,那么如何同时满足这些参数所能达到的功能呢?
这时就可以用管道字符来将他们结合起来,管道字符在这里称为“按位或”操作符。
如,希望 Regex 不区分大小写,并且句点字符匹配换行,就可以这样构造 re.compile()函数:
someRegexValue = re.compile('foo', re.IGNORECASE | re.DOTALL)
管道
用管道匹配多个分组,字符|代表管道,意味着匹配许多表达式中的一个,类似于逻辑“或”:

也可以用管道来匹配多个模式中的一个,作为正则表达式的一部分,如以下意味着试图匹配 Batman、Batmobile、Batcopter、Batbat 中任意一个:

3. Regex 对象
Regex 对象的方法:
.search(): 查找传入的字符串,寻找该正则表达式的所有匹配。返回一个 Match 对象或 None,其对应第一次匹配的文本
.findall()若 Regex 对象无分组:返回一个字符串列表,包含被查找字符串中的所有匹配;

若 Regex 对象有分组:返回元组的列表,每个元组表示一个找到的匹配,其中的项就是 Regex 中每个分组的匹配字符串。

.sub(): 用新的文本替换掉匹配的文本模式。需要两个参数,第一个是一个字符串,用于取代发现的匹配;第 2 个是一个字符串,即正则表达式。返回值为替换完成后的字符串。

有时候你可能需要使用匹配的文本本身作为替换的一部分。在 sub()的第 1 个参数中,可以输入\1, \2, \3……表示在替换中输入分组 1, 2, 3 的文本:

4. Match 对象
常用变量名 mo 代表一个 Match 对象
Match 对象的方法:
.group(): 返回被查找字符串中实际匹配的文本。其不带参数或传入参数值 0,返回值为整个匹配的文本;
传入参数 1 或 2,代表着返回第 1 或第 2 分组的匹配文本。


.groups():一次获取所有的分组,返回值为多个值的元组。
5. re.*函数
参见官方标准库文档。
函数re.split()是非常实用的,因为它允许你为分隔符指定多个正则模式。不过当你使用re.split()函数时,需要特别注意正则表达式中是否包含一个括号捕获分组,若使用了捕获分组,那么被匹配的文本也将出现在结果列表中。


字符串搜索和替换:
对于复杂模式,使用
re.sub()函数,其第一个参数是被匹配的模式,第二个参数是替换模式
其中反斜杠数字比如
\3指向前面模式的捕获组号。如果除了替换后的结果外,还需要知道有多少替换发生了,使用
re.subn()函数
6. 特定符号
详见官方文档。
符号类型及含义:
| 符号 | 含义 | 示例 |
|---|---|---|
. | 匹配除了换行之外的所有字符,但只匹配一个字符 |  |
^ | 在Regex开始处使用^表式字符必须发生在查找文本开始处 |  |
$ | 在Regex末尾处加上$表示匹配字符串尾,或换行符的前一个字符 |  |
* | 意味着匹配零次或多次,即*之前的正则式可以在文本中出现任意次 | ab* 匹配 'a', 'ab', 或'a'后面跟任意多个'b' |
+ | 意味着匹配一次或多次,即+前面的正则式必须至少出现一次 | ab+ 匹配 'a' 后面跟1个以上到任意个 'b': |
? | 表示它前面的正则式匹配0到1次重复 | ab? 会匹配 'a' 或 'ab' |
.* | 组合使用点-星符,表示除换行外的任意文本 |  |
^$ | 同时使用^$,表示整个字符串必须匹配该Regex模式 |  |
{} | 指定其之前的正则式匹配固定(范围)次的重复 | 正则表达式(ha){3}将匹配hahaha正则表达式 (ha){3,5}将匹配hahaha, hahahaha 和 hahahahaha 正则表达式 (ha){3,}将匹配3次及以上的文本 |
\ | 转义特殊字符(允许你匹配'*', '?' 或者此类其他) | |
[] | 用[]定义自己的字符分类 | 如[aeiouAEIOU]将匹配所有元音字符 如字符分类 [a-zA-Z0-9]将匹配所有小写字母、大写字母和数字  |
() | 表示分组(组合),匹配括号内的任意Regex,并标识出组合的开始和结尾 | |
\d | 0到9的任何数字 | |
\D | 除0到9的数字以外的任何字符 | |
\w | 任何字母、数字或下划线字符(可以认为是匹配“单词”字符) | |
\W | 除字母、数字和下划线以外的任何字符 | |
\s | 空格、制表符或换行符(可以认为是匹配“空白”字符) | |
\S | 除空格、制表符和换行符以外的任何字符 |
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于ff50e-于