数据操作
1. 索引取值
索引器
loc属性:表示取值和切片都是显式的。不同的是,Pandas的显式切片是闭区间。>>> data.loc[1] 'a' >>> data.loc[1:3] 1 a 3 b dtype: objectiloc属性:表示取值和切片都是Python形式的隐式索引(左闭右开区间)。>>> data.iloc[1] 'b' >>> data.iloc[1:3]ix属性:是前两种索引器的混合形式。在Series对象中ix等价于标准的取值方式,不过ix索引器主要用于DataFrame对象。>>> data.ix[:3, :'pop'] area pop California 423967 38332521 Florida 170312 38332521 Illinois 149995 12882135
Series对象的索引
用字典的方式
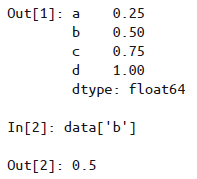
- 用
.keys()方法得到键(索引); - 用
.values属性得到值; - 用
.items()方法得到索引-值对的zip,可用list(data.items())将其列表化。
- 用
用一维数组的方式
注意,如上所说,Pandas的显式切片为闭区间。

DataFrame对象的索引
用字典的方式(注意,只能将列名当作字典形式的键):


- 不过,也可以用属性形式选择纯字符串列名的数据,上述
data['area']等价于data.area。如果列名不是纯字符串或列名与DataFrame的方法同名,就不能用这种形式的属性索引。 - 可以用
data['area']=z对列进行赋值,但应避免使用data.area=z。
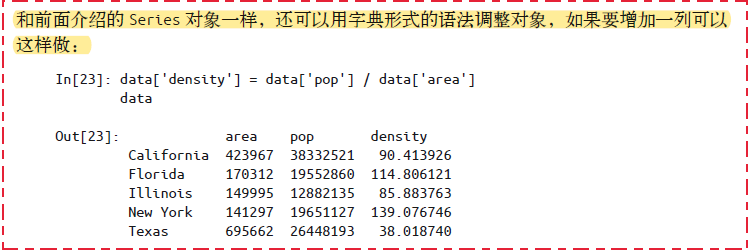
- 不过,也可以用属性形式选择纯字符串列名的数据,上述
用二维数组的方式
如
data.T可进行行列转置(视图):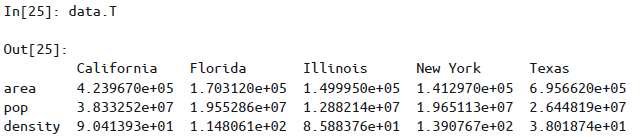
获取一行数据(无行列标签):

注意事项
以下操作方式其实与NumPy数组的语法类似,虽然它们与Pandas的操作习惯不太一致,但是在实践中非常好用。
如果对单个标签取值会对应列,而对多个标签用切片会对应行
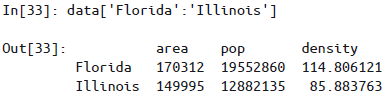
切片也可以不用索引值,而直接用行数来实现,即隐式索引切片
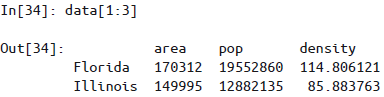
同ii,掩码操作也可以直接对每一行进行过滤,而不需要使用
loc索引器
2. 多级索引
层级索引(hierarchical indexing),也被称为多级索引(multi-indexing),配合多个有不同等级(level)的一级索引一起使用,可以将高维数组转换成类似一维Series和二维DataFrame对象的形式。
多级索引每增加一级,就表示数据增加一维,利用这一特点就可以轻松表示任意维度的数据了。
Pandas的MultiIndex类型提供了丰富的操作方法。
多级索引的Series
reindex():索引重置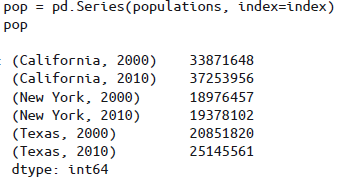

unstack():方法快速将一个多级索引的Series转化为普通索引的DataFrame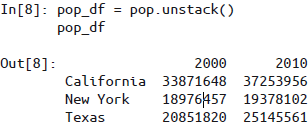
stack():方法快速将一个普通索引的DataFrame转化为多级索引的Series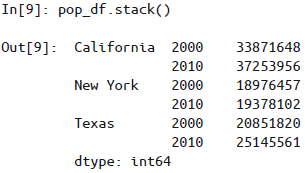
创建MultiIndex
隐式地创建多级索引:
为
Series或DataFrame创建多级索引最直接的办法就是将index参数设置为至少二维的索引数组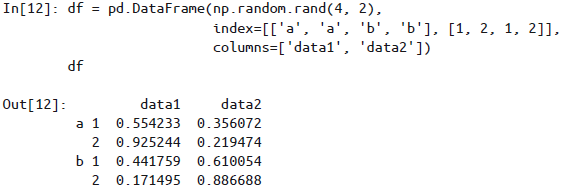
若将元组作为字典的键传递给Pandas,Pandas也会默认转换为
MultiIndex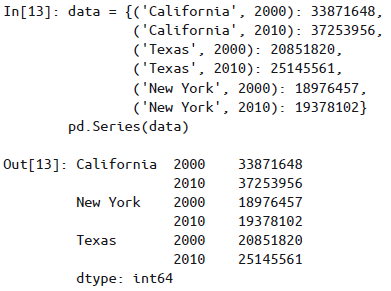
显示地创建多级索引:
通过一个由不同等级的若干简单数组构成的列表创建
MultiIndex
通过包含多个索引值的元组构成的列表创建
MultiIndex
用两个索引的笛卡尔积创建
MultiIndex
直接提供
levels(包含每个等级的索引值列表的列表)和labels(包含每个索引值标签列表的列表)创建MultiIndex
MultiIndex的特点
多级索引的等级名称——可以在
MultiIndex构造器中通过names参数设置等级名称,也可以在创建之后通过索引的names属性来修改名称: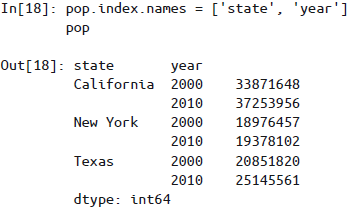
多级列索引——每个DataFrame的行与列都是对称的,也就是说既然有多级行索引,那么同样可以有多级列索引:

索引排序——局部切片和许多其他相似的操作都要求
MultiIndex的各级索引是有序的,Pandas提供了sort_index()和sortlevel()方法进行索引排序: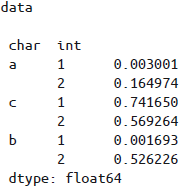
375 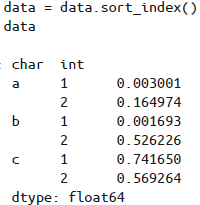
对于多级索引,可以设置参数
level实现对数据子集的统计操作。
多级索引的取值与切片
注意,如果MultiIndex不是有序的索引,大多数切片操作都会失败。
对于Series
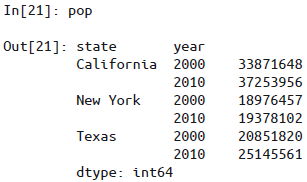
可以通过对多个级别索引值获取单个元素
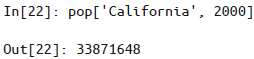
可局部取值,即只索引某一个层级,结果为一个新的
Series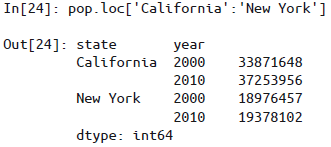
局部切片(要求
MultiIndex是按顺序排列的)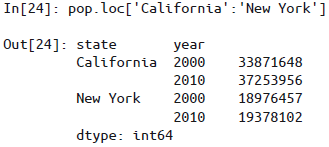
若索引已排序,可用较低层级地索引取值,第一层级可以用空切片
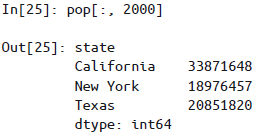
其他取值方法也都起作用,如布尔掩码和花哨的索引等
对于DataFrame
由于
DataFrame的基本索引是列索引,因此Series中多级索引的用法到了DataFrame中就应用在列上了。

还可用
loc, iloc, ix索引器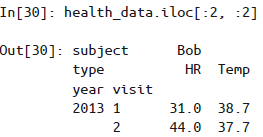
在
loc和iloc中可以传递多个层级的索引元组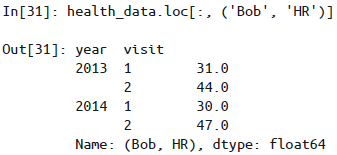
不过这种索引元组的用法不是很方便,且在元组中使用切片会导致语法错误。
使用
IndexSlice对象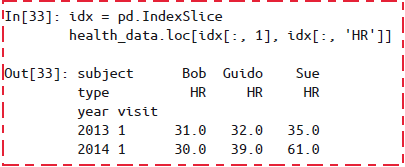
多级索引的相互转换
stack与unstack如上所述,可以将一个多级索引转换成简单的二维形式,通过
level参数设置转换的索引层级。
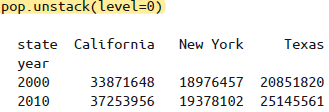
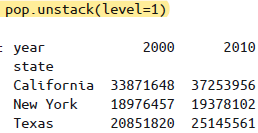
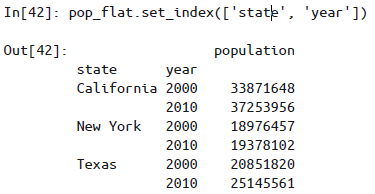
用
reset_index方法实现行列标签转换。也可以用DataFrame的set_index方法实现,返回结果就是一个带多级索引的DataFrame: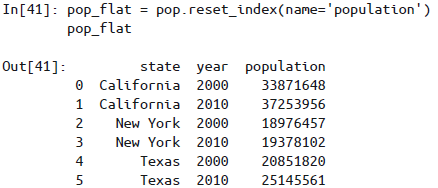
3. 运算规则
Pandas是建立在NumPy基础之上的,所以NumPy的通用函数同样适应于Pandas的Series和DataFrame对象。
- 对于一元运算(如三角函数),通用函数将在输出结果中保留索引和列标签;
- 对于二元运算(如加法和乘法),Pandas在传递通用函数时会自动对齐索引进行计算。
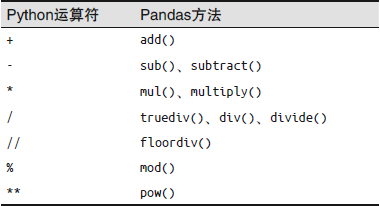
Pandas方法与Python运算符之间的映射关系:
当在两个Series或DataFrame对象上进行二元计算时,Pandas会在计算过程中对齐两个对象的索引:
Series索引对齐
结果数组的索引是两个输入数组索引的并集。
DataFrame索引对齐


两个对象的行列索引可以是不同顺序的,结果的索引会自动按顺序排列。
一个Series与一个DataFrame进行计算的行列对齐方式与上述类似,也与NumPy中二维数组与一维数组的运算规则相同。
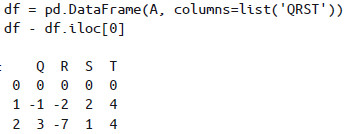
在Pandas里默认也是按行运算的,若要按列计算,可通过axis参数设置:
 |  |  |
|---|
4. 合并数据集
pd.concat()函数
Pandas 有一个pd.concat()函数与np.concatenate()语法类似,但参数更多:

Pandas 的pd.concat()函数有如下特点:
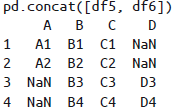
Pandas 在合并时会保留索引,即使索引是重复的:

对于上条,虽然 DataFrame 允许这么做,但结果并不是我们想要的,
pd.concat()提供了一些解决这个问题的方法:捕捉索引重复的错误:设置
verify_integrity参数为True,合并时若有索引重复就会触发异常。忽略索引:设置
ignore_index参数为True,合并时会创建一个新的整数索引。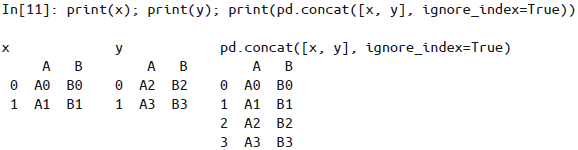
增加多级索引:通过
keys参数为数据源设置多级索引标签。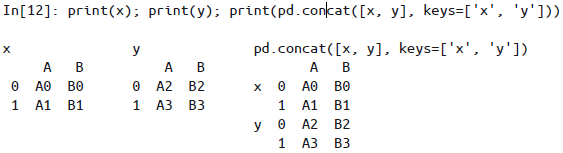
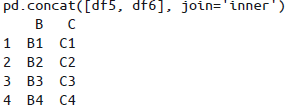
默认的合并方式是对所有输入列进行并集合并(
join='outer'),当然也可以用join='inner'实现对输入列的交集合并:

另一种合并方式是直接确定结果使用的列名,设置
join_axes参数,里面是索引对象构成的列表(列表的列表):
append()方法
使用append()方法:
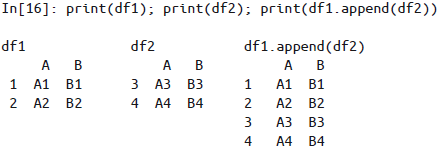
需要注意的是,与 Python 列表的 append()方法不同,Pandas 的 append()不直接更新原有对象的值,而是为合并后的数据创建一个新对象,因此它不能称之为一个非常高效的解决方案。所以,如果你需要进行多个 append 操作,还是建议先创建一个 DataFrame 列表,然后用 concat()函数一次性解决所有合并任务。
pd.merge()函数
Pandas 的基本特性之一就是高性能的内存式数据连接(join)和合并(merge)操作,其主接口是pd.merge()函数。
一对一连接
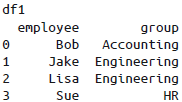
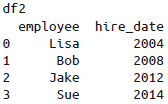

pd.merge()函数会发现两个DataFrame都有employee列,并自动以这列作为键进行连接。需要注意的是,
pd.merge()会默认丢弃原来的行索引,不过也可以自定义。多对一连接:多对一连接是指,在需要连接的两个列中,有一列的值有重复。通过多对一连接获得的结果
DataFrame将会保留重复值。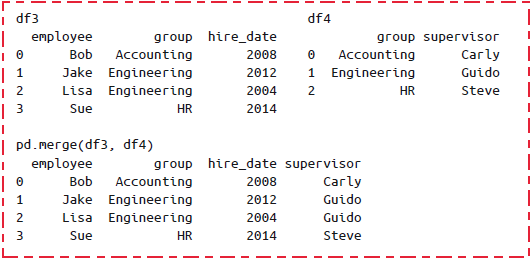
多对多连接:如果左右两个输入的共同列都包含重复值,那么合并的结果就是一种多对多连接。
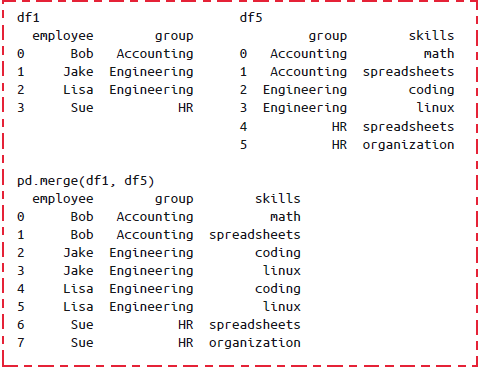
设置 pd.merge()合并的键
用参数
on这个参数只能在两个
DataFrame有共同列名的时候才可能使用。

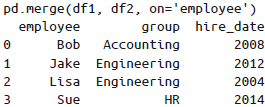
用
left_on与right_on参数
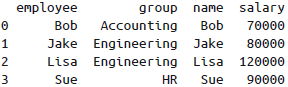
获取的结果中会有一个多余的列,可以通过
DataFrame的drop()方法去掉: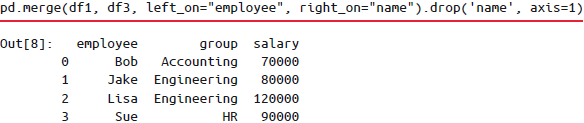
用
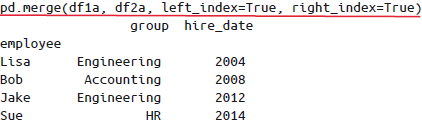
left_index与right_index参数有时需合并索引,可以通过这两个参数将索引设置为键来实现合并:
同时使用
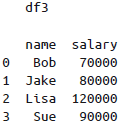
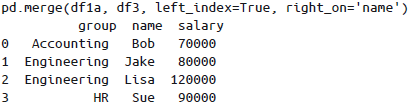
left_index与right_on(或left_on与right_index),如此可将索引与列混合使用: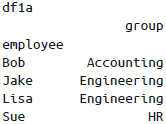
设置数据连接的集合操作规则
当一个值出现在一列却没有出现在另一列时,需要考虑集合操作规则。
内连接(inner join): 默认情况,结果只包含两个输入的交集。
外连接(outer join): 返回两个输入列的并集,缺失值用 NaN 填充。
左连接(left join)和右连接(right join): 返回的结果分别只包含左列和右列。
对于输出结果中有两个重复的列名的情况,pd.merge()函数会自动为它们增加后缀_x 和_y,当然也可以通过suffixes参数自定义后缀名:
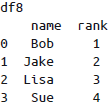  |   |
|---|
5. 累计与分组
累计
Pandas中Series的累计函数会返回一个统计值,而DataFrame的累计函数默认对每列进行统计。
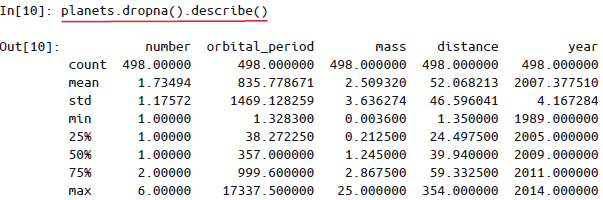
Pandas的Series和DataFrame函支持所有NumPy的常用累计函数另外,还有一个非常方便的describe()方法可以计算每一列的若干常用统计值:
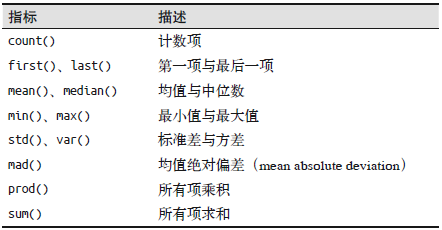
Pandas内置的一些累计方法如下:
分组
数据累计的下一级别是groupby操作,它可以让你快速、有效地计算数据各子集的累计值。
分组(group by)这个名字是借用SQL数据库语言的指令,但其理念引用发明R语言frame的Hadley Wickham的观点更合适:分割(split)、应用(apply)和组合(combine)。
以apply为求和函数为例,GroupBy的过程如下:
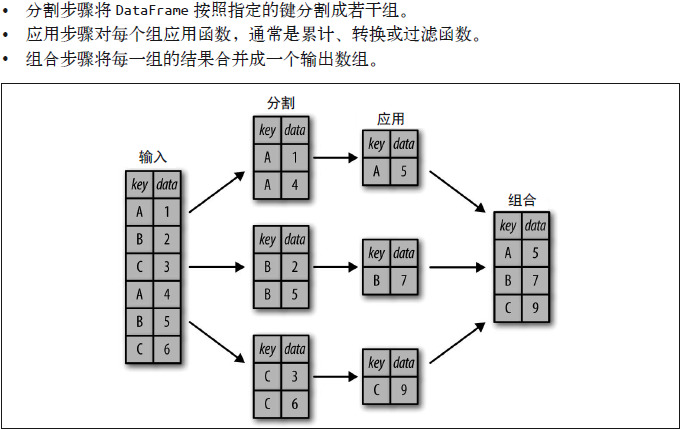
这种操作虽然也可以通过一系列的掩码、累计与合并操作来实现,但是要意识到分割过程不需要显式地暴露出来这一点十分重要。
GroupBy经常只需要一行代码就可以计算每组的和、均值、计数、最小值等。GroupBy的用处就是将这些步骤进行抽象:用户不需要知道在底层如何计算,只要把操作看成一个整体就够了。
GroupBy的基本操作方法:
按列取值
按组迭代
调用方法
GroupBy设置分割的键:
最一般地,用列名分割DataFrame
将列表、数组、Series或索引作为分组键
用字典或Series将索引映射到分组名称
任意Python函数
多个有效键构成的列表
GroupBy中最重要的操作可能就是aggregate、filter、transform和apply(累计、过滤、转换、应用)了:

累计:

过滤:过滤操作可以按照分组的属性丢弃若干数据。
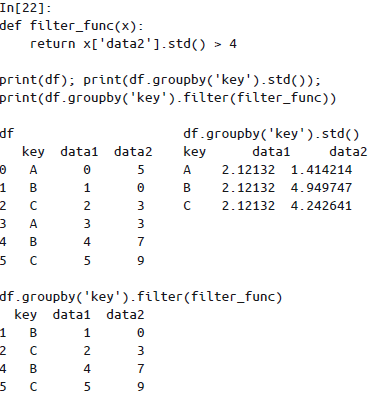
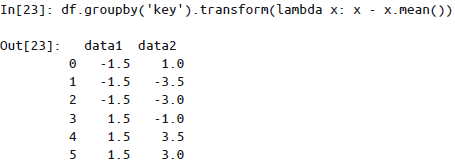
转换:累计操作返回的是对组内全量数据缩减过的结果,而转换操作会返回一个新的全量数据。数据经过转换之后,其形状与原来的输入数据是一样的。常见的例子就是将每一组的样本数据减去各组的均值,实现标准化。
应用:
apply()方法让你可以在每个组上应用任意方法。这个函数输入一个DataFrame,返回一个Pands对象(DataFrame或Series)或一个标量(scalar,单个数值)。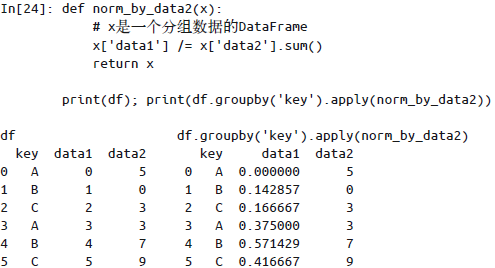
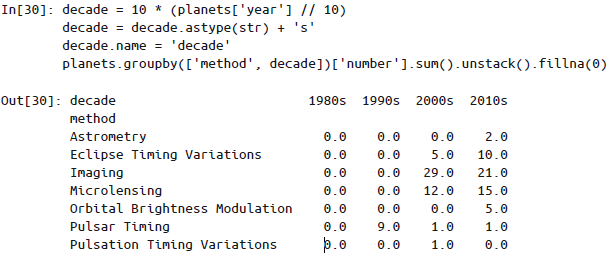
分组案例


数据透视表
数据透视表(pivot table)是一种类似GroupBy的操作方法,常见于Excel与类拟的表格应用中。数据透视表将每一列数据作为输入,输出将数据不断细分成多个维度累计信息的二维数据表。数据透视表更像是一种多维的GroupBy累计操作。
由于二维的GroupBy应用场景非常普遍,Pandas提供了一个快捷方式pivot_table来快速解决多维的累计分析任务。
DataFrame的pivot_talbe方法完整签名如下:

6. 向量化字符串
Python的一个优势就是字符串处理起来比较容易。在此基础上创建的Pandas同样提供了一系列向量化字符串操作(vectorized string operation) ,它们都是在处理(清洗)现实工作中的数据时不可或缺的功能。
Pandas为包含字符串的Series和Index对象提供的str属性堪称两全其美,它既可以满足向量化字符串操作的需求,又可以正确地处理缺失值。
向量化操作简化了纯数值的数组操作语法——我们不需要再担心数组的长度或维度,只需要关心需要的操作。然而,由于NumPy并没有为字符串数组提供简介的接口,因此需要通过繁琐的for循环来解决问题:
虽然这么做对于某些数据可能是有效的,但是假如数据中出现了缺失值,那么这样做就会引起异常。
>>> data = ['peter', 'Paul', 'MARY', 'gUIDO']
>>> [s.capitalize() for s in data]
['Peter', 'Paul', 'Mary', 'Guido']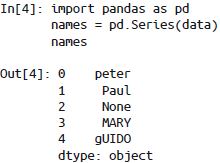 | 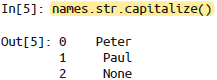  Pandas中缺失值会被跳过。 |
|---|
Pandas字符串方法:
与Python字符串方法相似的方法
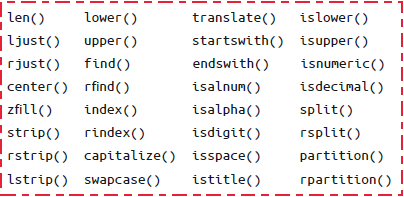
使用正则表达式的方法

其他字符串方法

7. 其他
删除指定的一个或多个索引及其对应的值时,使用.drop()方法,此方法默认产生一个新的对象,不会改变原有对象;若想直接在原对象上进行删除,可以使用参数 inplace=True,但要慎用!!!
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于4f800-于