eval与query
2019/4/15大约 2 分钟约 540 字
高性能的eval()与query()
eval()与query()的设计动机:复合代数式(compound expression)。

也就是说,每段中间过程都需要显式地分配内存。如果x和y数组非常大,这样的运算就会占用大量的时间和内存消耗。
Numexpr程序库可以让你在不为中间过程分配全部内存的前提下,完成元素到元素的复合代数式运算。简单点儿说,这个程序库其实就是一用一个NumPy风格的字符串代数式进行运算:

这尤其适合处理大型数组。Pandas的eval()和query()工具就是基于Numexpr实现的。
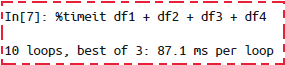
Pandas的eval()函数用字符串代数式实现了DataFrame的高性能运算:


pd.eval()支持的运算:
- 算术运算符
- 比较运算符(包括链式代数式)
- 位运算符
- 对象属性与索引
- 其他运算
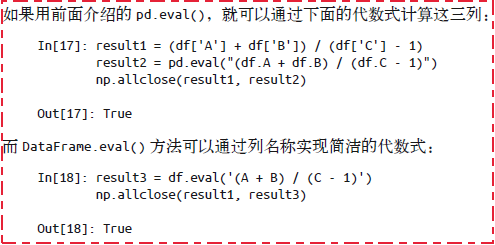
使用DataFrame的.eval()方法的好处是可以借助列名称进行运算:
使用
DataFrame.eval()新增列

DataFrame.eval()使用局部变量
@符号表示“这是一个变量名称而不是一个列名称”,从而让你灵活地用两个“命名空间”的资源(列名称的命名空间和Python对象的命名空间)计算代数式。@符号只能在DataFrame.eval()方法中使用,而不能在pandas.eval()函数中使用,因为pandas.eval()函数只能获取一个(Python)命名空间的内容。
DataFrame基于字符串代数式的运算实现了另一个方法,被称为query()方法,如:

这是一个用
DataFrame列创建的代数式,但是不能用DataFrame.eval()语法。此时,对于这种过滤运算,你可以用query()方法:
除了计算性能更优之外,这种方法的语法也比掩码代数式语法更好理解。需要注意的是,
query()方法也支持用@符号引用局部变量。
更新日志
2024/4/13 02:18
查看所有更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于4f800-于