概述
Pandas简介
import pandas as pd
建立在 NumPy 数组结构上的 Pandas,尤其是它的 Series 和 DataFrame 对象,为数据科学家们处理那些消耗大量时间的“数据清理”(data munging)任务提供了捷径。
Pandas 有三个基本数据结构:Series, DataFrame, Index。
Pandas 中字符串类型通常是用 object 类型存储的。
Series对象
Pandas 的 Series 对象有 values 和 index 两个属性。
values属性返回的结果与 NumPy 数组类似;index属性返回的结果是一个类型为pd.Index的类数组对象。
Series 对象的特点:
Series对象是一个带索引数据构成的一维数组。可以用一个数组创建Series对象:>>> data = pd.Series([0.25, 0.5, 0.75, 1.0]) >>> data 0 0.25 1 0.50 2 0.75 3 1.00 dtype: float64Series是通用的 NumPy 数组。显式索引的定义让Series对象拥有了更强的能力,例如索引不再仅仅是整数,而可以是任意想要的类型:>>> data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd']) >>> data a 0.25 b 0.50 c 0.75 d 1.00 dtype: float64Series是特殊的字典。字典是一种将任意键映射到一组任意值的数据结构,而Series对象其实是一种将类型键映射到一组类型值的数据结构。用字典创建Series对象时,其索引默认按照顺序排列。
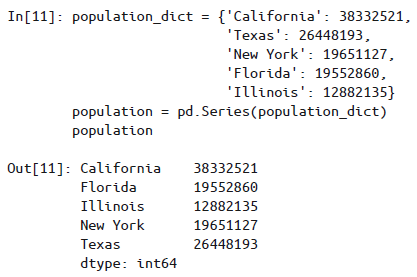
创建 Series 对象的通用形式:pd.Series(data, index=index)
data:支持多种数据类型index: 可选参数可以通过显式地指定索引筛选需要的结果:
>>> pd.Series({2: 'a', 1: 'b', 3: 'c'}, index=[3, 2]) 3 c 2 a dtype: object
DataFrame对象
DaraFrame 对象有values, index, columns三个属性。
- 其中
values和index的功能同Series对象,index属性和columns属性都是pd.Index对象 - 将
index属性叫做索引标签,columns属性叫做列标签。
DataFrame 对象的特点:
- 如果将
Series类比为带灵活索引的一维数组,那么DataFrame就可以看作是一种既有灵活的行索引,又有灵活列名的二维数组。也可以将DataFrame看成是含共同索引的若干Series对象。 DataFrame是特殊的字典。字典是一个键映射一个值,而DataFrame是一列映射一个Series的数据。
创建 DataFrame 对象:
通过单个
Series对象创建pd.DataFrame(population, columns=['population'])通过字典列表创建(元素是字典的列表),此时由字典的键对应
DataFrame的列标签>>> data = [{'a': i, 'b': 2 * i} for i in range(3)] >>> pd.DataFrame(data) a b 0 0 0 1 1 2 2 2 4通过
Series对象字典创建通过
NumPy二维数组创建
通过
NumPy结构化数组创建
Index对象
Index 对象的特点:
将 Index 看作不可变数组
- Index 对象与 NumPy 数组之间的不同在于,Index 对象的索引是不可变的,也就是说不能通过通常的方式进行调整。
将 Index 看作有序集合(实际上是个多集,因为可包含重复值)
Index 对象遵循 Python 标准库的集合(set)数据结构的许多习惯用法,包括并集、交集、差集等:
indA & indB # 交集 indA | indB # 并集 indA ^ indB # 异或这些操作还可以通过调用对象方法来实现,如
indA.intersection(indB)。
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于4f800-于