IO操作
Pandas有多种I/O API函数,它们为把大多数常用格式的数据作为DataFrame对象进行读写提供了极大的便利。这些函数分为完全对称的两大类,读取函数和写入函数:
| 格式 | 类型描述 | 读取函数 | 写入函数 |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google Big Query | read_gbq | to_bgq |
对于列表数据,如果文件由空格或制表符分隔数据,则这种格式一般为txt文件。
CSV文件读写
read_csv也可读取.txt格式。
对于列表数据,如果文件每一行的多个元素是用逗号隔开的,则这种格式叫作CSV,这可能是最广为人知和最受欢迎的格式。CSV文件中的数据为列表数据,位于不同列的元素用逗号隔开。
读取
设有如下CSV文件:

可通过
read.csv()函数读取它的内容,同时将其转换为DataFrame对象:
有时候,标识各列名称的表头不一定存在,即CSV文件的第一行就是列表数据,如:

此时可设置
header参数为None,则Pandas会为其添加默认表头:
此外,也可以使用
names参数设置指定表头:
复杂情况下,若需创建具有等级结构的
DataFrame对象,可使用index_col参数将所有想转换为索引的列名称赋给index_col:
写入
将创建的
DataFrame数据写入CSV文件,可通过to_csv()函数:

此时默认将索引和列名称都写入了文件,可通过
index和header参数取消这一行为:
需要注意的是,数据中的
NaN写入文件后显示为空字段:


不过可以通过
to_ csv()函数的na_rep参数将空字段替换为你需要的值,常用值有NULL、0和NaN等:
Excel文件读写
读取
假设有一个.xls(或.xlsx)文件,包含两个sheet:

用
read_excel()函数直接读取(默认读取第一个sheet)并将其转换为DataFrame对象:
若要读取第二个工作表(sheet)中的数据,可指定相应sheet名称:

写入
上述操作也适用于Excel写入操作:

工作目录中会生成一个Excel文件:
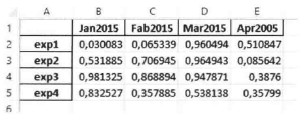
JSON文件读写
JSON(JavaScript Object Notation, JavaScript对象标记)已成为最常用的标准数据格式之一,特别是在Web数据的传输方面。
首先,定义一个
DataFrame对象,用to_json()函数或方法将其写入json文件:

将json文件读取也非常简单,用
read_json()函数:
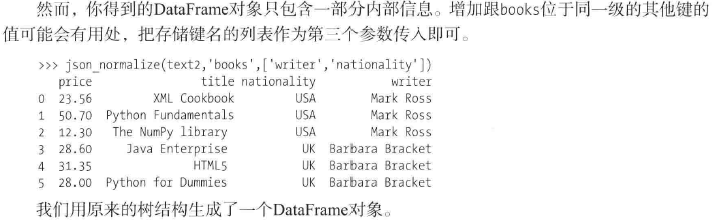
然而,json文件中的数据通常不是上述的列表形式。因此,你需要将字典结构的文件转换为列表形式,这个过程称谓规范化,pandas库的
json_normalize()函数可将字典或列表转换为表格:>>> from pandas.io.json import json_normalize假设用任意文件编辑器编写了如下json文件:


由于其不是列表形式,故无法再用
read_json()来处理。可这样处理,先加载json文件的内容,并将其转换为一个字符串:
然后可以调用
json_nornalize()函数。假设你可能想得到一个包含所有图书信息的表格:
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于4f800-于