缺失值处理
缺失值处理的方法
此处涉及的缺失值主要有三种形式:null, NaN, NA(not available)。
处理缺失值的方法一般可分为两种:掩码法、标签值法。
使用单独的掩码数组会额外出现一个布尔类型数组,从而增加存储与计算的负担;而标签值方法缩小了可以被表示为有效值的范围,可能需要在 CPU 或 GPU 算术逻辑单元中增加额外的(往往也不是最优的)计算逻辑。通常使用的 NaN 也不能表示所有数据类型。
掩码法是通过一个覆盖全局的掩码表示缺失值。掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0 或 1)表示有缺失值的局部状态。
标签值法是用一个标签值表示缺失值。标签值可能是具体的数据(例如用-9999 表示缺失的整数),也可能是些极少出现的形式。标签值还可能是更全局的值,比如用 NaN(不是一个数)表示缺失的浮点数,它是 IEEE 浮点数规范中指定的特殊字符。
Pandas的缺失值处理
Pandas 最终选用标签值法表示缺失值,包括两种 Python 原有的缺失值:浮点数据类型的 NaN 值,以及 Python 的 None 对象。
None:Python 对象类型的缺失值None是一个 Python 单体对象,经常在代码中表示缺失值。- 由于是对象,所以它不能作为任何 NumPy 或 Pandas 数组类型的缺失值,只能用于
object数组类型(即由 Python 对象构成的数组)。 - 这种类型的数组任何操作最终都会在 Python 层面完成,所以要比其他原生类型数组消耗更多资源。
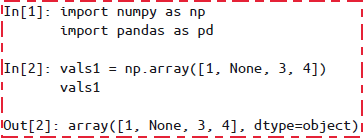
NaN:数值类型的缺失值- Not a Number,是一种按照 IEEE 浮点数标准设计、在任何系统中都兼容的特殊浮点数。
- 可以把
NaN看作是一个数据类病毒——它会将与它接触过的数据同化,即无论和NaN进行何种操作,最终结果都是NaN。
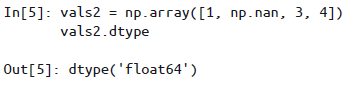
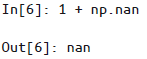

Pandas 中
NaN与None的差异:Pandas 把 NaN 和 None 看成是可以等价交换的,在适当的时候会将两者进行替换: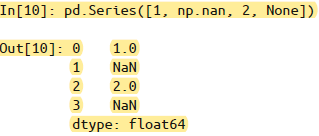
Pandas 中不同类型缺失值的转换规则
再次提醒:Pandas 中字符串类型通常是用
object类型存储的。
处理缺失值的相关方法
| 缺失值处理方法 | 说明 | |
|---|---|---|
| isnull() | 创建一个布尔类型的掩码标签缺失值 | |
| notnull() | 与 isnull()操作相对 | |
| dropna() | 返回一个剔除缺失值的数据 | DataFrame 中使用需要设置一些参数 |
| fillna() | 返回一个填充了缺失值的数据副本 | 可选参数 method='ffill' 或'bfill' |
对于
dropna()方法:默认情况下,
dropna()会剔除任何包含缺失值的整行数据可以设置按不同的坐标轴剔除缺失值,如
axis=1(或axis='columns')会剔除任何包含缺失值的整列数据默认设置是
how='any',即只要有缺失值就剔除整行或整列。可设置为how='all',则只会剔除全部是缺失值的行或列。可以通过
thresh参数设置行或列中非缺失值的最小数量图片 图片 图片 

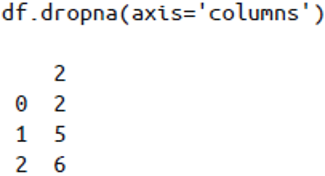
![df[3] - nan NaN 4.6 2 Nan 5 Nan 6 Nan](https://figure-bed.chua-n.com/Python/353.png)


![In[22]: thresh=3) Outt22J: 1 5 NaN](https://figure-bed.chua-n.com/Python/356.png)
对于
fillna()方法:可用一个单独的值来填充缺失值
可用缺失值前面的有效值来从前往后填充(forward-fill)
可用缺失值后面的有效值来从后往前填充(back-fill)
DataFrame的操作方法与Series类似,只是填充时可能需要设置axis参数注意,假如从前往后填充时,需要填充的缺失值前面没有值,那以它填充后仍然是缺失值
图片 图片 图片 图片 





更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于4f800-于