函数
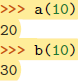
如你所料,川,在函数被调用时,实参是通过“对象引用”调用的
函数定义
函数的定义看起来可以像是这样:

其中,/ 和 * 是可选的。若使用这些符号,则表明可以通过何种形参将参数值传递给函数:仅限位置、位置或关键字、仅限关键字
- 仅限位置形参:要放在正斜杠
/之前,这个/用来从逻辑上分隔仅限位置形参和其它形参; - 仅限关键字形参:应在参数列表要求的第一个仅限关键字形参位置之前放置一个
*。
形参
parameter(形参) :函数中定义的命名实体,它指定函数可以接受的 argument(实参) ,共有 5 种形参:
positional-or-keyword(位置或关键字):是默认的形参类型,指定一个可以作为位置参数传入也可以作为关键字参数传入的实参,如下面的 foo 和 bar:def func(foo, bar=None): ...positional-only(仅限位置):指定一个只能按位置传入的参数;keyword-only(仅限关键字):指定一个只能通过关键字传入的参数。可通过在形参列表中包含单个可变位置形参或者在多个可变位置形参之前放一个*来定义,如下面的kw_only1, kw_only2:def func(arg, *, kw_only1, kw_only2): ...var-positional(可变位置):指定可以提供一个由任意数量的位置参数构成的序列(附加在其他形参已接受的位置参数之后),可通过在形参名称前加前缀*来定义,如下面的args:def func(*args, **kwargs): ...var-keyword(可变关键字):指定可以提供任意数量的关键字参数(附加在其他形参已接受的关键字参数之后),可通过在形参名称前加前缀**来定义,如上面的kwargs.
形参可以同时指定可选和必选参数,可以为某些可选参数指定默认值:
对于想设置默认参数的函数,注意如果默认参数是一个可修改的容器比如一个列表、集合或者字典,最好使用
None作为默认值:示例 说明 
传递一个None值和不传值是有区别的。 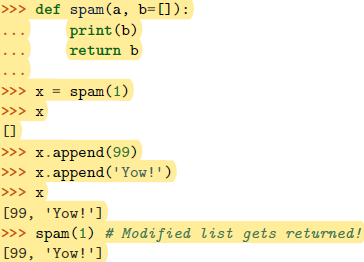
默认参数的值应该是不可变的对象,比如None, True, False, 数字或字符串。
如左的作法是强烈不建议的,如果你这么做,当默认值在其他地方被修改后你将遇到各种麻烦,因为这些修改会影响到下次调用该函数时的默认值。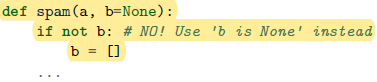
在测试None值时使用is操作符是很重要的,这也是关键 默认参数的值仅仅在函数定义的时候赋值一次
>>> x = 42 >>> def spam(a, b=x): ... print(a, b) ... >>> spam(1) 1 42 >>> x = 23 # Has no effect >>> spam(1) 1 42当一个函数需要测试某个可选参数是否被使用者传递进来时,需要小心的是不能用某个默认值比如None,0或者False值来测试用户提供的值(因为这些值都是合法的值,是可能被用户传递进来的)。
为了解决这个问题,你可以创建一个独一无二的私有对象实例,就像下面的_no_value变量那样。
_no_value = object() def spam(a, b=_no_value): if b is _no_value: print('No b value supplied') ... >>> spam(1) No b value supplied >>> spam(1, 2) # b = 2 >>> spam(1, None) # b = None
位置形参的好处:
如果某位置参数和
**kwds之间存在关键字名称的冲突,该参数名将总是绑定到位置形参之上:# 此时函数将永远返回False,因为'name'总是绑定到第一个形参 def foo(name, **kwds): return 'name' in kwds# 而此时,使用仅限位置形参,即可避免歧义 def foo(name, /, **kwds): return 'name' in kwds >>> foo(1, **{'name': 2}) True对于 API 来说,使用仅限位置形参可以防止形参名称在未来被修改时造成破坏性的 API 变动。
由上综合,其实可得,出现在*args参数之后的任何形式参数都是仅限关键字参数:

重要警告:对于含有默认值的函数,其默认值只会执行一次,这在默认值为可变对象时就很重要,其更改这个可变对象即可更改函数默认值:
def f(a, L=[]): L.append(a) return L print(f(1)) # [1] print(f(2)) # [1, 2] print(f(3)) # [1, 2, 3] # 若不想在后续调用中共享默认值,可这样写 def f(a, L=None): if L is None: L = [] L.append(a) return L
实参
argument(实参) :在调用函数时传给函数的值,分为两种形式:
关键字参数:在函数调用中前面带有标识符(例如 name=)或者作为包含在前面带有
**的字典里的值传入。举例来说,3 和 5 在以下对complex()的调用中均属于关键字参数:
位置参数:不属于关键字参数的参数。位置参数可出现于参数列表的开头以及/或者作为前面带有
*的 iterable 里的元素被传入。举例来说,3 和 5 在以下调用中均属于位置参数: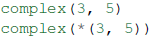
如果要让函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后。Python 先匹配位置实参和关键字实参,再将余下的实参都收集到最后一个形参中。
*和**参数
内涵上的差别:
- 让一个函数接受任意数量的位置参数,使用
*开头的参数; - 让函数接受任意数量的关键字参数,使用
**开头的参数; - 希望函数能同时接受任意数量的位置参数和关键字参数,同时使用
*和**。
位置上的差别:
- 一个
*参数只能出现在函数定义中最后一个位置参数后面,在*参数后面仍然可以定义其他参数; - 而
**参数只能出现在最后一个参数:
def a(x, *args, y):
pass
def b(x, *args, y, **kwargs):
pass可强制函数的某些参数使用关键字参数传递,只需将相应参数放到某个*参数后面即可:
很多情况下,使用强制关键字参数会比使用位置参数表意更加清晰,程序也更具有可读性;另外,使用强制关键字参数比使用
**kwargs参数在使用 help 的时候输出也更容易理解。
def recv(maxsize, *, block):
'Receives a message'
pass
recv(1024, True) # TypeError
recv(1024, block=True) # Ok
def minium(*values, clip=None):
m = min(values)
if clip is not None:
m = clip if clip > m else m
return m
minimum(1, 5, 2, -5, 10) # Returns -5
minimum(1, 5, 2, -5, 10, clip=0) # Return 0廖雪峰:*args是可变参数,args接收的是一个tuple,**kw是关键字参数,kw接收的是一个dict:
- 可变参数既可直接传入:
func(1, 2, 3),又可以先组装成list或tuple,再通过*args传入:func(*(1, 2, 3)); - 关键字参数既可直接传入:
func(a=1, b=2),又可先组装成dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
return语句
- 若函数定义中没有
return语句,则函数返回None. - Python 中的函数总是返回单个对象;如果一个函数必须返回多个对象,那么这些对象将被打包并作为一个元组对象返回。
函数标注
函数标注以字典的形式存放在函数的__annotations__属性中,并且不会影响函数的任何其他部分。
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:
>>> a = abs # 变量a指向abs函数
>>> a(-1) # 所以也可以通过a调用abs函数
1特殊类型的函数
递归函数
递归函数通常会有一个level参数,执行递归函数传递的 level 次数称为递归尝试,这个数不应该太大。
最大递归深度取决于使用的计算机的内存容量。
Lambda函数
Lambda表达式本质上其实只是正常函数定义的语法糖。
所谓语法糖我理解就是本来有其他方法,和这个操作是完全等价的,但是语法糖提供了一种更简便和简洁的操作。
lambda表达式允许你定义简单函数,它的使用是有限制的,只能指定单个表达式,其值就是最后的返回值。
- lambda表达式典型的使用场景是排序或数据reduce等。

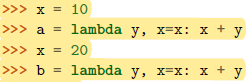
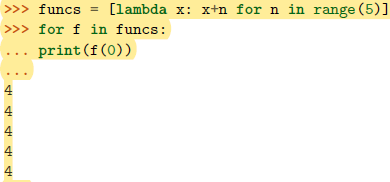
一般地,lambda表达式中的其他变量是自由变量,在运行时绑定,而不是定义时就绑定,这不同于函数的默认值参数定义;如果想让lambda函数在定义时就捕获到值,可以将该参数定义成默认参数。
其实,把lambda表达式想象成等价的 def 函数就可以了。
定义 使用 


偏函数
对于一个已存在的函数,如果你需要多次调用而同时某个参数在你调用的过程中是不需要变化的,可以通过functools.partial()函数为该函数设置默认值参数减少重复输入。此即所谓的偏函数(非数学上的偏函数)。
def spam(a, b, c, d):
print(a, b, c, d)
>>> from functools import partial
>>> s1 = partial(spam, 1) # a = 1
>>> s1(2, 3, 4)
1 2 3 4
>>> s1(4, 5, 6)
1 4 5 6
>>> s2 = partial(spam, d=42) # d = 42
>>> s2(1, 2, 3)
1 2 3 42
>>> s2(4, 5, 5)
4 5 5 42
>>> s3 = partial(spam, 1, 2, d=42) # a = 1, b = 2, d = 42
>>> s3(3)
1 2 3 42
>>> s3(4)
1 2 4 42
>>> s3(5)
1 2 5 42闭包
简单来讲,一个闭包就是一个函数,只不过在函数内部带上了一个额外的变量环境,闭包的关键特点就是它会记住自己被定义时的环境。
大多数情况下,可以使用闭包来将单个方法的类优雅简洁地转换成函数。
任何时候只要你碰到需要给某个函数增加额外的状态信息的问题,都可以考虑使用闭包。
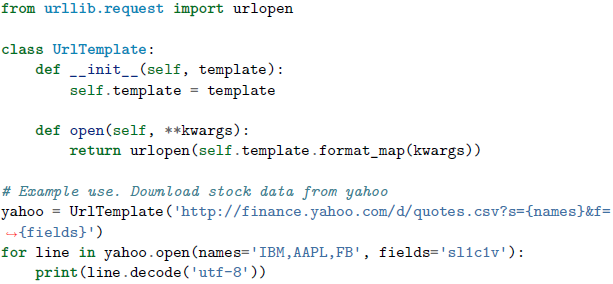
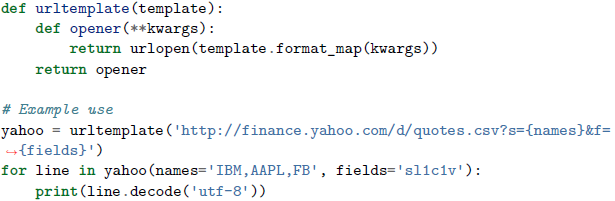
在下面的例子中,opener()函数记住了template参数的值,并在接下来的调用中使用它:
通常来讲,闭包的内部变量对于外界来讲是完全隐藏的。但是,也可以编写访问函数并将其作为函数属性绑定到闭包上来实现这个目的:
nonlocal声明可以让我们编写函数来修改内部变量的值。- 函数属性允许我们用一种很简单的方式将访问就去绑定到闭包函数上,这跟实例方法很像。
- 闭包的方案运行起来稍快一些。


回调函数
带额外状态信息的回调函数(7.10)和内联回调函数(7.11)。
高阶函数
既然变量可以指向函数,函数的参数又能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。如:
def add(x, y, f):
return f(x) + f(y)map
map()是Python内置的高阶函数,它接收一个函数 f 和一个iterable, 并通过把函数 f 依次作用在 iterable 的每个元素上(映射),返回一个可转换为Python 内置iterable对象的map对象,而传入的原对象不变:
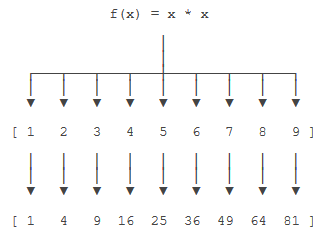
f = lambda x: x*x
l = list(range(1, 10)) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
ans = map(f, l) # <map object at 0x000001743BE5DEB8>
list(ans) # [1 ,4, 9, 16, 25, 36, 49, 64, 81]map()函数根据传入的 f 的性质可接收多个iterable(本质将其组合成元组):
g = lambda x, y: x*y
list(map(g, [1,2,3], [3,2,1])) # [3, 4, 3]
list(map(g, [1,2,3], [3,2,1,0]) # [3, 4, 3],多余的元素被忽略借助map()函数可避免使用for循环而进行一些类型转换:
list(map(int, (1,2,3))) # [1,2,3] 当然list((1,2,3))会更直接一些
tuple(map(int, '1234')) # (1, 2, 3, 4)
list(map(int, {'1': 'a', 2: 23})) # [1, 2] 对字典的操作会针对它的键
list(map(tuple, 'abc')) # [('a',), ('b',), ('c',)]
set(map(int, '123123')) # {1, 2, 3}
set(map(int, 123123)) # TypeError: 'int' object is not iterablereduce
fuctools标准库的reduce()函数也是高阶函数。
reduce()函数也以接收两个参数,一个是函数,一个是序列,reduce()将这个函数作用在这个序列上,其含义是将结果继续和序列的下一个元素做累积计算,其效果相当于:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x2, x2), x3), x4)如,假设要对一个序列求和(当然这完全可以使用sum()函数):

又如,把序列[1, 3, 5, 7, 9]变成整数13579:

filter与sorted
Python内建的filter()函数甚至sorted()函数也是高阶函数。
sorted()函数可以接收一个key参数来实现自定义的排序,其中key指定的函数将作用于序列的每一个元素上,并根据key函数的返回结果进行排序。例如
假设要按照绝对值大小排序:

忽略大小写的排序(默认情况下,对字符串排序是按照ASCII的大小比较的,由于
'Z' < 'a',导致的结果是大写字母Z会排在小写字母a的前面):

sum
如果一个列表里面的每个元素都是列表,可以用sum把它拉平:
>>> a = [[1], [2, 3], [4, 5, 6]]
>>> sum(a, [])
[1, 2, 3, 4, 5, 6]>>> b
[1, [2, 3], [4, 5, 6]]
>>> sum(b, [])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate list (not "int") to list如果是嵌套列表的话,可以用递归的方法把它拉平,这也是lambda函数的一种优美的使用方法:
不过,真的有必要掌握这种奇怪语法吗?
>>> nested_lists = [[1, 2], [[3, 4], [[5, 6], [7, 8]]]]
>>> flatten = lambda x: [y for i in x for y in flatten(i)] if type(x) is list else [x]
>>> flatten(nested_lists)
[1, 2, 3, 4, 5, 6, 7, 8]函数式编程
函数式编程将一个问题分解成一系列函数,著名的函数式语言有ML家族和Haskell(C语言是过程式编程),函数式编程可以被认为是面向对象编程的对立面。
函数式编程的一个特点是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此Python不是纯函数式编程的语言。
既然变量可以指向函数,函数的参数又能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。如:
def add(x, y, f):
return f(x) + f(y)Python内建/标准库中的map, reduce, filter, sorted函数等,都是高阶函数。
装饰器亦属于函数式编程,装饰器主要用于在代码运行期间动态增加功能。本质上,装饰器就是一个返回函数的高阶函数。
迭代器、生成器也属于函数式编程思想的重要组成部分。
在函数内部定义了另一个函数,且函数返回值为内部函数的函数名;该内部函数可以引用外部函数的参数和局部变量,外部函数在返回时相关参数和变量都会保存在返回的函数中,这种程序结构称为闭包。闭包在很多地方拥有极大的威力:
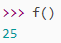
返回的函数没有立刻执行,而是直到调用了f()才执行。


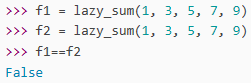
闭包每次调用时都会返回一个新的函数,即使传入的是相同的参数。
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于e18f8-于076c4-于8ff00-于