前言
1. 命名及书写规约
命名:
- 在文件名和文件夹名中,最好使用小写字母,并用下划线来表示空格,这是 python 采用的命名约定。
- 应给 函数/模块 指定描述性名称,且只在其中使用小写字母和下划线。描述性名称可帮助你和别人明白代码想要做什么。
- 根据约定,在 python 中,首字母大写的名称指的是类。类名应采用驼峰命名法,即将类名中的每个单词的首字母都大写,而不使用下划线。
- 通常而言,应使用小写的 python 变量名。
- 慎用小写字母 l 和大写字母 O,因为它们可能被人错看成数字 1 和 0。
书写规约:
PEP:Python 增强提议的英文缩写,一个 PEP 就是一份设计文档。
- 行末尾的反斜框(\)将下一行标记为连续行,即显式行连接。如果行在所有圆括号关闭之前结束,则以下将自动识别为连续行,即隐式行连接。
- 在类中,可使用一个空行来分隔方法;而在模块中,可使用两个空行来分隔类。
- 需要同时导入标准库中的模块和你编写的模块时,先编写导入标准库模块的 import 语句,再添加一个空行,然后编写导入你自己编写的模块的 import 语句。
- 如果程序或模块包含多个函数,可使用两个空行将相邻的函数分开。
- 所有的 import 语句都应放在文件开头,唯一例外的情形是,在文件开头使用了注释来描述整个程序。
- 在程序中混合使用制表符和空格可能导致极难解决的问题,最好将文件中的所有制表符转换为空格。
- 很多 Python 程序员都建议每行不超过 80 字符。PEP8 还建议注释的行长都不超过 72 字符。
- 在条件测试的格式设置方面,PEP8 提供的唯一建议是:在诸如==、<=和>=等比较运算符两边各添加一个空格,如
if age < 4:要比if age<4:好。 - 给形参指定默认值时,等号两边不要有空格:
def function_name(parameter_0, parameter_1='default value'),对于函数调用中的关键字实参,也应遵循这种约定:function_name(value_0, paramter_1='value') - 如果形参很多,导致函数定义的长度超过了 79 字符,可在函数定义中输入左括号后按回车键,并在下一行按再次 Tab 键,从而将形参列表和只缩进一层的函数体区分开来。
有时代码虽然能够正确运行,但可做进一步的改进——将代码分为一系列完成具体工具的函数。这样的过程被称为重构,重构让代码更清晰、更易于理解、更容易扩展。
2. 概念统领
python 社区的理念都包含在 Tim Peters 撰写的python 之禅中。要获悉这些有关编写优秀 python 代码的指导原则,只需在解释器中执行命令import this.
Python 中把跟在一个点号之后的名称都称为属性。可写的属性同样可以用 del 语句删除。
字面值是用于表示一些内置类型的常量,如字符串字面值、数字字面值等。
Python 中万物皆对象,变量是为引用该对象而对其贴上的标签(自编)。
变量
变量是对某个对象的引用,一个对象可能有好几个引用。可以使用赋值运算符=给一个变量赋值。
x = [1, 2, 3]- # 1. 在内存中创建一个对象——列表[1, 2, 3]
- # 2. 在内存中创建一个名为 x 的变量,并将 x 指向列表[1, 2, 3] (将列表[1, 2, 3]的地址保存到 x 中)
- # 2. 上一步可直接理解为给内存中创建的[1, 2, 3]贴上一个标签 x(给其起个名叫 x)
- # 3. 于是可通过标签 x 操作实际内容[1, 2, 3]
y = x:# 再给 x 对应的内容([1, 2, 3])贴一个标签 y,该对象现在在两个标签: x 和 yx.append(4):# x, y 均变为[1, 2, 3, 4]x = "r u ok":- # 1. 在内存中创建一个字符串"r u ok"的对象
- # 2. 将标签 x 拿过来贴到对象"r u ok"上
- # 此时 y 依然是[1, 2, 3, 4]
y = x:- # 再将标签 y 拿过来贴到 x 对应的"r u ok"上
- # 此时由于[1, 2, 3, 4]没有了标签,成为了内存中的垃圾,将被回收
del x:# 将其中一个标签删除del y:# 两个标签均被删除:对象被删除。赋值操作=:故此,Python 中的赋值操作(=)均相等于贴标签(起别名)操作。故类似于 C++中的引用(Python 中全部为引用传递)
变量不是盒子
观点来自《流畅的 Python》:


对象的比较( is与== )
Python 中每个对象都有各自的编号、类型和值,一个对象被创建后,其编号就绝不会改变,可以将其理解为该对象在内存中的地址。
is:比较的是两个对象的编号是否相同(两个变量指向的对象是否是同一个对象,或者说两个变量是否是同一个对象的标签)>>> a = "hello world" >>> b = a >>> b is a True >>> b == a True==:比较的是两个对象的值(变量指向的内容)是否相等>>> a = "hello world" >>> b = "hello world" >>> a == b True >>> a is b Falseid()函数:返回一个代表对象编号的整型数,在 CPython 的实现中就是内存的地址。x is y为真等价于其内存地址相同,即id(x)等于id(y)x == y为真则不要求内存地址相同
使用区别:
is与==相比有一个比较大的优势,就是计算速度快,因为它不能重载,不用进行特殊的函数调用,少了函数调用的开销而直接比较两个整数 id。- 通常,我们关注的是值,而不是内存地址,因此 Python 代码中
==出现的频率比is高。 - 目前,最常使用
is的地方是判断对象是不是None。下面是推荐的写法:a is Nonea is not None
特殊情况:然后,需要注意的是,对于一些小的对象(网页上说是小的整型对象[-5, 256],以及长度 ≤20 的字符串,python 3.6),Python 认为它们经常用到,会对其进行缓存,使得这时候本应为假的
a is b为真。不过一些解释器如 pycharm 已经对此做出了优化,使得没有这种特殊情况。>>> a = 1 >>> b = 1 >>> a is b True >>> c = 'hello' >>> d = 'hello' >>> c is d True>>> m = 258 >>> n = 258 >>> m is n False >>> x = 'hello world' >>> y = 'hello world' >>> x is y False
垃圾回收
garbage collection(垃圾回收) :释放不再被使用的内存空间的过程。
Python 是通过引用计数和一个能够检测和打破循环引用的循环垃圾回收器来执行垃圾回收的。你也可以使用 gc 模块来控制垃圾回收器。
文档字符串(docstring)
第一行应该是对象目的的简要概述;
如果文档字符串中有更多行,则第二行应为空白,从而在视觉上将摘要与其余描述分开;后面几行应该是一个或多个段落,描述对象的调用约定,它的副作用等。
文档字符串第一行之后的第一个非空行确定了整个文档字符串的缩进量(我们不能使用第一行,因为它通常与字符串的开头引号相邻,其缩进在字符串文字中不明显),然后从字符串的所有行的开头剥离与该缩进“等效”的空格。
源码文件的编码
默认情况下,Python 源码文件以 UTF-8 编码方式处理,不过标准库中只用常规的 ASCII 字符作为变量或函数名,而且任何可移值的代码都应该遵守此约定。
如果不使用 UTF-8 编码,应该要声明所使用的编码
文件的第一行要写成特殊的注释:
# -*- coding: encoding -*-上述的一种例外情况是,源码以 UNIX "shebang"行开头,此时编码声明写在文件的第二行:
#!/usr/bin/env python3 # -*- coding: cp1252 -*-
在 BSD 等类 UNIX 系统上,PYTHON 脚本可以直接执行,就像 shell 脚本一样,第一行添加:
#!/user/bin/env python3.5mutable 与 immutable
- immutable 对象,即不可变对象,包括数字、字符串 和 元组,这样的对象不能被改变,如果必须存储一个不同的值,则必须创建新的对象。
- immutable 对象在需要常量哈希值的地方起着重要作用,如作为字典的键。
- mutable(可变),可变对象可以在其
id()保持固定的情况下改变其取值。
hashable(可哈希):
一个对象的哈希值如果在其生命周期内绝不改变,就被称为可哈希(它需要具有__hash__() 方法),并可以同其他对象进行比较(它需要具有__eq__() 方法)。可哈希对象必须具有相同的哈希值比较结果才会相同。
可哈希性使得对象能够作为字典键或集合成员使用,因为这些数据结构要在内部使用哈希值。
- 大多数 Python 中的不可变内置对象都是可哈希的;
- 可变容器(例如列表或字典)都不可哈希;
- 不可变容器(例如元组和 frozenset)仅当它们的元素均为可哈希时才是可哈希的。
- 用户定义类的实例对象默认是可哈希的。它们在比较时一定不相同(除非是与自己比较),它们的哈希值的生成是基于它们的
id()。
iterable(可迭代对象):
可迭代对象是指能够逐一返回其成员项的对象。其可用于 for 循环以及许多其他需要一个序列的地方(zip(), map() ...)。
可迭代对象的例子包括:
- 序列类型(例如
list, str, tuple) dict- 文件对象
- 定义了
__iter__()方法的自定义类对象 - 实现了 Sequence 语义的
__getitem__()方法的自定义类对象
当一个可迭代对象作为参数传给内置函数 iter() 时,它会返回该对象的迭代器,这种迭代器适用于对值集合的一次性遍历。
在使用可迭代对象时,你通常不需要调用 iter() 或者自己处理迭代器对象,因为 for 语句会为你自动处理那些操作——创建一个临时的未命名变量用来在循环期间保存迭代器,参见 iterator、sequence 以及 generator。
sequence(序列):
序列是一种 iterable,它支持通过__getitem__()来使用整数索引进行高效的元素访问,并定义了一个返回序列长度的__len__()方法;
内置的序列类型有 list, str, tuple, bytes.
注意 dict 也支持__getitem__()和__len__(),但它被认为属于映射而非序列,因为它查找时使用任意的 immutable 键而非整数。
Python 中的任何序列类型都自动支持创建迭代器。
3. 疏理:Python 标准类型层级结构
序列
序列对象通常可以与相同序列类型的其他对象比较,这种比较使用字典式顺序:
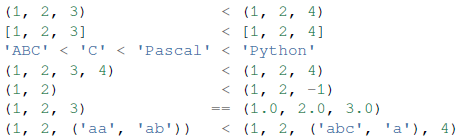
- 不可变序列:字符串、元组、字节串
- 可变序列:列表、字节数组
集合类型
- 集合:通过内置的
set()构造器创建 - 冻结集合:通过内置的
frozenset()构造器创建
- 集合:通过内置的
映射
- 字典:此类对象表示由几乎任意值作为索引的有限个对象的集合
可调用类型
用户自定义函数
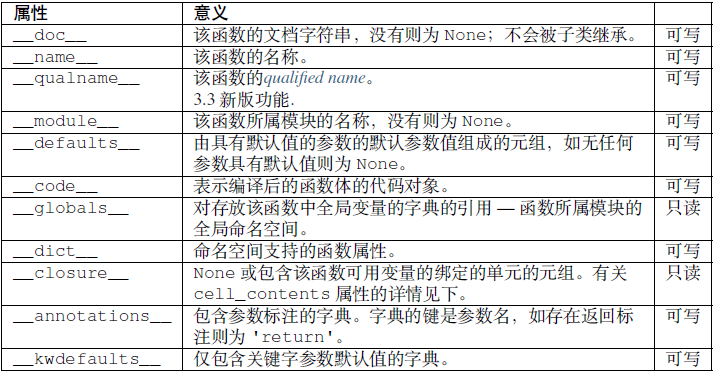
实例方法
属性 含义 __self__类实例对象本身 只读 __func__函数对象 只读 __doc__方法的文档,与 __func__.__doc__作用相同只读 __name__方法的名称,与 __func__.__name__作用相同只读 __module__方法所属模块的名称,没有则为 None只读 生成器函数:一个使用 yield 语句的函数或方法,这样的函数在被调用时,总是返回一个可以执行函数体的迭代器对象
协程函数
异步生成器函数
内置函数:内置函数对象是对于 C 函数的外部封装。特殊的只读属性有:
__doc____name____self__:设定为 None__module__
内置方法:此类型实际上是内置函数的另一种形式,只不过还包含了一个传入 C 函数的对象作为隐式的额外参数。内置方法的一个例子是 alist.append(),其中 alist 为一个列表对象。在此示例中,特殊的只读属性
__self__会被设为 alist 所标记的对象。类:类是可调用的。此种对象通常是作为“工厂”来创建自身的实例,类也可以有重载
__new__()的变体类型。调用的参数会传给__new__(),而且通常也会传给__init__()来初始化新的实例类实例:任意类的实例通过在所属类中定义
__call__()方法即能成为可调用的对象
模块:Python 代码的基本组织单元
属性 意义 __name__模块的名称 可写 __doc__模块的文档字符串 可写 __annotations__可选,一个包含变量标的字典,是在模块体执行时获取的 可写 __file__模块对应的被加载文件的路径名(如果它是加载自一个文件的话),某些类型的模块可能没有此属性 可写 __dict__以字典为对象表示的模块命名空间 只读 自定义类
特殊属性 __name____module____dict____bases____doc____annotations__类实例
特殊属性 __self____dict____class__... I/O 对象(或称文件对象)
内部类型
内部类型 说明 代码对象 表示编译为字节的可执行 Python 代码,或称 bytecode 帧对象 帧对象表示执行帧。它们可能出现在回溯对象中(见下文),还会被传递给注册跟踪函数 回溯对象 回溯对象表示一个异常的栈跟踪记录。当异常发生时会隐式地创建一个回溯对象,也可能通过调用 types.TracebackType显式地创建切片对象 切片对象用来表示 __getitem__()方法得到的切片。该对象也可使用内置的 slice() 函数来创建静态方法对象 静态方法对象提供了一种避免上文所述将函数对象转换为方法对象的方式。静态方法对象为对任意其他对象的封装,通常用来封装用户定义方法对象。当从类或类实例获取一个静态方法对象时,实际返回的对象是封装的对象,它不会被进一步转换。静态方法对象自身不是可调用的,但它们所封装的对象通常都是可调用的。静态方法对象可通过内置的 staticmethod()构造器来创建类方法对象 类方法对象和静态方法一样是对其他对象的封装,会改变从类或类实例获取该对象的方式。类方法对象在此类获取操作中的行为已在上文” 用户定义方法” 一节中描述。类方法对象可通过内置的 classmethod()构造器来创建
4. 赋值语句
赋值语句用于将名称(重)绑定到特定值,以及修改属性或可变对象的成员项(官方文档):

赋值语句会对指定的表达式列表(“参数列表”的那个“列表”,而非数据结构的那个“列表”)进行求值(注意这可能为单一表达式或是由逗号分隔的列表,后者将产生一个元组),并将单一结果对象从左至右逐个赋值给目标列表。
but:

增强赋值语句:
- 增强赋值语句例如
x += 1可以改写为x = x + 1获得类似但并非完全等价的效果。在增强赋值的版本中,x 仅会被求值一次。而且,在可能的情况下,实际的运算是原地执行的,也就是说并不是创建一个新对象并将其赋值给目标,而是直接修改原对象。 - 不同于普通赋值,增强赋值会在对右手边求值之前对左手边求值。例如,
a[i] += f(x)首先查找 a[i],然后对 f(x) 求值并执行加法操作,最后将结果写回到 a[i]。 - 除了在单个语句中赋值给元组和多个目标的例外情况,增强赋值语句的赋值操作处理方式与普通赋值相同。类似地,除了可能存在原地操作行为的例外情况,增强赋值语句执行的二元运算也与普通二元运算相同。
5. pip
第三方库安装
pip 安装(最主要方法)
集成安装方法(如 Anaconda 支持近 800 个第三方库)
文件安装方法
| 常用 pip(/pɪp/ )命令 | 说明 |
|---|---|
| pip install <第三方库名> | 安装指定的库 |
| pip install -U <第三方库名> | 更新已安装的指定库 |
| pip uninstall <第三方库名> | 卸载指定的库 |
| pip download <第三方库名> | 下载但不安装指定库 |
| pip show <第三方库名> | 列出指定库的详细信息 |
| pip search <关键词> | 根据库名称和介绍中的关键词搜索第三方库 |
| pip list | 列出当前系统(环境?)所安装的第三方库 |
可以通过提示包名称后跟==和版本号来安装特定版本的包:

6. IPython
IPython : interactive Python 的简称,即交互式 Python。
Jupyter Notebook 是 IPython shell 基于浏览器的图形界面。
IPython 的帮助和文档:
| 符号 | 作用 | 备注 |
|---|---|---|
? | 获取某一对象、方法等的 docstring | 类似 Python 内置的 help()函数 |
?? | 同上,获取源代码 | 若不能显示源代码,则查询目标不是用 Python 实现的,可能是 C 语言等。此时??相当于? |
.<Tab> | 以列表形式返回对象的属性和方法 | 类似 Python 内置的 dir() 函数; 可通过输入属性或方法的前几个字符缩小范围; 默认省略了私有方法和特殊方法(可通过键入一条下划线来明确显示) |
* | 通配符匹配 | *Warning? 列出命名空间中所有以 Warning 结尾的对象 *find*? 列出名称中包含 find 字符串的对象 |
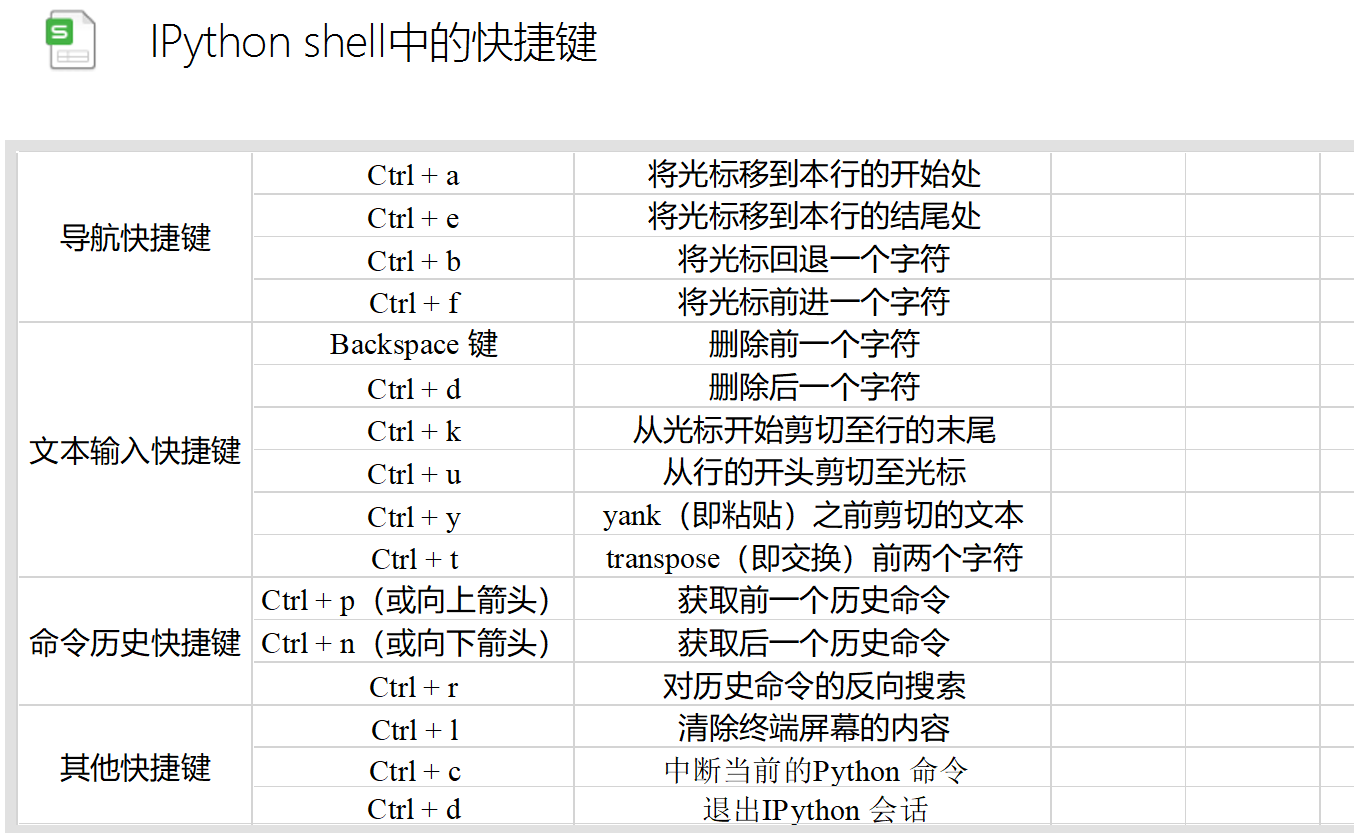
IPython shell 中的快捷键:
IPython 魔法命令:一些 IPython 在普通 Python 语法基础之上的增强功能,都以%符号为前缀。
- 行魔法(%):作用于单行输入
- 单元魔法(%%):作用于多行输入
| 魔法命令 | 作用 | 补充说明 |
|---|---|---|
%magic | 获得可用魔法函数的通用描述以及一些示例 | |
%lsmagic | 快速而简单地获得所有可用魔法函数的列表 | |
%time | 对单个语句的执行时间进行计时 | 即使同样对已排序的列表进行排序,用%time 计时也比用%timeit 计时花费的时间要长。这是由于%timeit 在底层做了一些很聪明的事情来阻止系统调用对计时过程的干扰。 |
%timeit | 对单个语句的重复执行进行计时,以获得更高的准确度。 | 用%%变为单元魔法可处理多行输入 |
%prun | 利用分析器运行代码 | |
%lprun | 利用逐行分析器运行代码 | 不与IPython捆绑,需安装line_profiler |
%memit | 测量单个语句的内存使用 | 不与IPython捆绑,需安装memory_profiler |
%mprun | 通过逐行的内存分析器运行代码 | 不与IPython捆绑,需安装memory_profiler |
%paste | 粘贴代码块 | 同时输入并执行该代码 |
%cpaste | 粘贴代码块 | 打开一个交互式多行输入提示 |
%run | 执行外部代码 | 可用%run?查看帮助文档 |
%history | 一次性获取此前所有的输入历史 | |
%rerun | 重新执行部分历史命令 | |
%save | 将部分历史命令保存到一个文件中 | |
%debug | 调试 | 如果你在捕获异常后调用该调试器,它会在异常点自动打开一个交互式调试提示符。 |
%pdb | 设置为在发生任何异常时都自动启动调试器: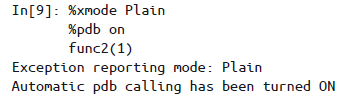 | |
%xmode | 异常模式 | 模式有3 个可选项:Plain, Context, Verbose示例: %xmode Plain |
IPython 实际上创建了叫作In和Out的Python 变量,这些变量自动更新以反映命令历史。
In对象是一个列表,按照顺序记录所有的命令(列表中的第一项是一个占位符,以便In[1]可以表示第一条命令)。Out 对象不是一个列表,而是一个字典。它将输入数字映射到相应的输出(如果有的话)。
Out[X]有一个简写形式是_XIn [1]: import math In [2]: math.sin(2) Out [2]: 0.9092974268256817 In [3]: math.cos(2) Out [3]: -0.416... In [4]: print(In) ['', 'import math', 'math.sin(2)', 'math.cos(2)', 'print(In)'] In [5]: Out Out[5]: {2: 0.9092974268256817, 3: -0.416...} In [6]: print(In[1]) import math请注意,不是所有操作都有输出,例如import语句和print语句就不影响输出,对于后者而言,任何返回值是None的命令都不会加到Out变量中。
变量
_(单下划线)用于更新以前的输出In [9]: print(_) 1.0甚至可以用两个下划线获得倒数第二个历史输出,三个下线划获取倒数第三个历史输出(跳过任何没有输出的命令)
在python IDLE或命令行的交互模式下,其实上一次打印出来的表达式被赋值给了变量_,这个变量只应该被当作是只读类型,不要向它显式地赋值:
>>> tax = 12.5 / 100 >>> price = 100.50 >>> price * tax 12.5625 >>> price + _ 113.0625 >>> round(_, 2) 113.06
标准的Python 交互式调试工具是pdb,它是Python 的调试器。这个调试器允许用户逐行运行代码,以便查看可能导致错误的原因。IPython 增强版本的调试器是ipdb,它是IPython专用的调试器。
ipdb提示符让你可以探索栈空间的当前状态,探索可用变量,甚至运行Python命令!
ipdb的命令:

更新日志
899db-于eedbf-于47fa5-于c9215-于73b75-于75141-于730b3-于0e6a3-于29df4-于ff50e-于e18f8-于076c4-于8ff00-于