迭代器-生成器-装饰器-描述器
迭代器
概念
迭代器(iterator)——用来表示一连串数据流的对象:
- 重复调用迭代器的
__next__()方法(或将其传给内置函数next())将逐个返回流中的项;当没有数据可用时则将引发StopIteration异常,此时迭代器对象的数据项已耗尽,继续调用其__next__()方法只会再次引发StopIteration异常。 - 迭代器必须具有
__iter__()方法用来返回该迭代器对象自身,因此迭代器必定也是iterable(可迭代对象),可被用于其他可迭代对象适用的大部分场合。
在幕后,for 语句迭代一个容器对象时,会调用其中的 __iter__(),该函数返回一个定义了 __next__() 方法的迭代器对象,该方法将逐一访问容器中的元素。当元素用尽时,__next__() 将引发 StopIteration 异常来通过终止 for 循环。
为不使用 for 循环去遍历可迭代对象,也可使用next()内置函数来调用如上的__next__()方法,并在代码中捕获StopIteration异常。通常来讲,StopIteration用来指示迭代的结尾。另外,在next()函数中,你还可以通过返回一个指定值为标记结尾,比如None。
def manual_iter1():
with open('/etc/passwd') as f:
try:
while True:
line = next(f)
print(line, end='')
except StopIteration:
pass
def manual_iter2():
with open('/etc/passwd') as f:
while True:
line = next(f, None)
if line is None:
break
print(line, end='')在表达式 for X in Y 中,Y 要么本身是一个迭代器,要么能够由iter()创建一个迭代器,以下两种表达是等价的:
for i in iter(obj):
print(i)
for i in obj:
print(i)自定义迭代器
由上可知,给一个类添加迭代器行为,只需定义一个__iter__()方法来返回一个带有__next__()方法的对象。
如果类已经定义了__next__(),则__iter__()可以简单地返回self.


这里的
iter()函数的使用简化了代码,iter(s)只是简单地通过调用s.__iter__()方法来返回对应的迭代器对象,就跟len(s)是调用s.__len__()的原理是一样的。class Node: def __init__(self, value): self._value = value self._children = [] def __repr__(self): return 'Node({!r})'.format(self._value) def add_child(self, node): self._children.append(node) def __iter__(self): return iter(self._children) # Example if __name__ == '__main__': root = Node(0) child1 = Node(1) child2 = Node(2) root.add_child(child1) root.add_child(child2) # Outputs Node(1), Node(2) for ch in root: print(ch)
迭代器工具
内置函数
rangeenumerate:enumerate()函数返回的是一个enumerate对象实例,是一种迭代器,返回连续的包含一个计数和一个值的元组,元组中的值通过在传入序列上调用next()返回。enumerate()对于跟踪某些值在列表中出现的位置是很有用的;如果你想将一个文件中出现的单词映射到它出现的行号上去,可以很容易地利用enumerate()来实现。示例 输出 说明 
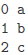


可传递一个开始参数使得输出时按指定的行号开始输出 
这一点可能并不重要,但也值得注意:就是当你在一个已经解压后的元组序列上使用 enumerate()函数时很容易掉入如左的陷阱。reversed: 反向迭代,其仅当对象的大小可预先确定,或对象实现了__reversed__()方法时才能生效,若两者都不符合则必须先转换为一个列表。比较而言,还是定义一个反向迭代器可使代码变得非常高效。



zip: 当需要同时迭代多个序列时,使用zip()函数。zip(a, b)会生成一个可返回元组(x, y)的迭代器,其中 x 来自 a,y 来自 b。一旦其中某个序列达到结尾,迭代宣告结束,即迭代长度跟最短序列长度一致。>>> xpts = [1, 5, 4, 2, 10, 7] >>> ypts = [101, 78, 37, 15, 62, 99] >>> for x, y in zip(xpts, ypts): ... print(x, y) ... 1 101 5 78 4 37 2 15 10 62 7 99 >>> a = [1, 2, 3] >>> b = ['w', 'x', 'y', 'z'] >>> for i in zip(a, b): ... print(i) ... (1, 'w') (2, 'x') (3, 'y')若希望迭代跟最长序列保持一致,使用
itertools.zip_longest()函数>>> from itertools import zip_longest >>> for i in zip_longest(a, b): ... print(i) ... (1, 'w') (2, 'x') (3, 'y') (None, 'z') >>> for i in zip_longest(a, b, fillavlue=0): ... print(i) ... (1, 'w') (2, 'x') (3, 'y') (0, 'z')使用
zip()可以轻松地将两个序列打包成一个字典headers = ['name', 'shares', 'price'] values = ['ACME', 100, 490.1] s = dict(zip(headers, values))zip()当然可以接受多于两个的序列的参数>>> a = [1, 2, 3] >>> b = [10, 11, 12] >>> c = ['x', 'y', 'z'] >>> for i in zip(a, b, c): ... print(i) ... (1, 10, 'x') (2, 11, 'y') (3, 12, 'z')
itertools模块
itertools.count: 一个可能无限的整数迭代器itertools.islice: 迭代器/生成器切片,使用熟悉的 slicing 语法来截断迭代器。- 其返回一个可以生成指定元素的迭代器,它通过遍历并丢弃直到切片开始索引位置的所有元素,然后开始一个个得返回元素,直到切片索引位置。
- 需要强调的是,
islice()会消耗掉传入的迭代器中的数据,必须意识到迭代器是不可逆的这个事实,若你需要之后再次访问这个迭代器,考虑将它的数据放到一个列表。
示例 说明 



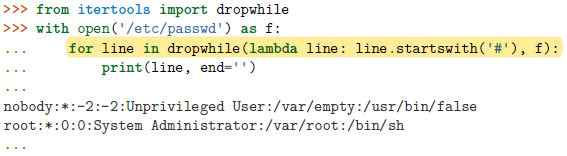
islice()函数最后的None参数意为至最后(终点为无),若None和 3 的位置对调,则为前三个元素,这个类似通常的 [3:] 和 [:3] 。itertools.dropwhile: 可用来在遍历可迭代对象的时候跳过某些元素。使用时向它传递一个函数对象和一个可迭代对象,它会返回一个迭代器对象,其丢弃了原有序列中直到函数返回False之前的所有元素,然后返回后面所有元素。假定在读取一个开始部分是几行注释的源文件
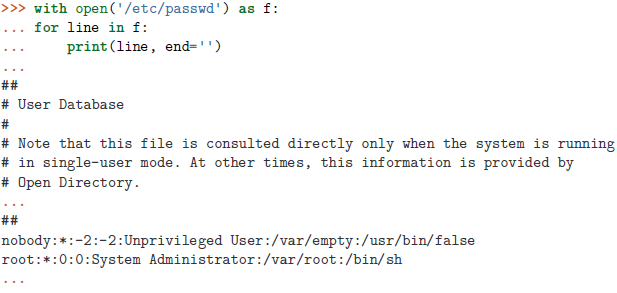
跳过注释行
itertools.chain: 可依次连续地返回多个可迭代对象中的元素,比先将序列合并再迭代要高效得多。其接受一个或多个可迭代对象作为输入参数。

排列组合
排列函数
itertools.permutations():其接受一个集合并产生一个元组序列,每个元组由集合中所有元素的一个可能排列组成。它可接受一个可选的长度参数如下(输出未截全):

组合函数
itertools.combinations():用法同上

组合函数
itertools.combinations_with_replacement():用法同上,但允许一个元素被同时选中多次
heap模块
heapq.merge: 若有一些排序序列,想将它们合并而得到一个排序序列并在上面迭代遍历,使用heapq.merge()函数。heapq.merge可迭代意味着它不会立马读取所有序列,这意味可以在非常长的序列中使用它而不会有太大的开销。- 需强调的是
heapq.merge()需要输入序列均为排过序的。
>>> import heapq >>> a = [1, 4, 7, 10] >>> b = [2, 5, 6, 11] >>> for c in heapq.merge(a, b): ... print(c) ... 1 2 4 5 6 7 10 11
生成器
概念
生成器(generator) 是一个用于创建迭代器的简单而强大的工具,它的写法类似标准的函数,不同点在于它们要返回数据时会使用 yield 语句。生成器返回一个 generator iterator,可供 for 循环使用或是通过 next()函数逐一获取。
可以用生成器来完成的操作两样可以用基于类的迭代器来完成,但生成器的写法更为紧凑,因为它会自动创建__iter__()和__next__()方法。
生成器可以被看成可恢复的函数。yield 和 return 最大的区别就在于,到达 yield 的时候生成器的执行状态会挂起并保留局部变量,在下一次调用生成器__next__()方法的时候,函数会恢复执行。
| 生成器定义 | 使用示例 |
|---|---|
 |   |
 |     |
Python 官方文档建议:在处理
yield表达式返回值的时候,总是两边写上括号,如val = (yield i),从语法角度来讲,括号并不总是必须的,但是这样不容易使人迷惑。
生成器表达式相比完整的生成器更紧凑但较不灵活,相比等效的列表推导式则更为节省内存。
生成器也可以采用另一个生成器作为输入参数。
如下通过生成器实现了深度优先遍历:

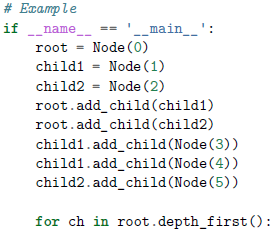
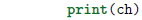

生成器的方法
每个生成器还自动包含有三个方法,send(), throw(), close():
send(value):向生成器发送值,它会恢复执行生成器的代码,然后yield表达式返回特定的值:

throw(type, value=None, traceback=None):用于在生成器内部抛出异常,这个异常会在生成器暂停执行时由yield表达式抛出。close():会在生成器内部抛出GeneratorExit异常来结束迭代。- 当接收到这个异常时,生成器的代码会抛出
GeneratorExit或者StopIteration;捕捉这个异常作其他处理是非法的,并会发出RuntimeError。 close()也会在 Python 垃圾回收器回收生成器的时候调用。- 如果你要在
GeneratorExit发生时清理代码,建议使用try…finally…组合来代替GeneratorExit。
- 当接收到这个异常时,生成器的代码会抛出
协程
生成器也可以成为协程,即一种更广义的子过程形式。子过程可以从一个地方进入,然后从另一个地方退出(从函数的顶端进入,从 return 语句退出),而协程可以进入、退出,然后在很多不同的地方恢复(yield 语句)。
生成器与管道
生成器函数是一个实现管道机制的好办法:
- 以管道方式处理数据可以用来解决各类其他问题,包括解析、读取实时数据、定时轮询等
- 为了理解上述代码,重要是要明白 yield 语句作为数据的生产者而 for 循环语句作为数据的消费者。当这些生成器被连在一起后,每个 yield 会将一个单独的数据元素传递给迭代处理管道的下一阶段。
- 这种方式一个非常好的特点是每个生成器函数很小并且都是独立的。这们的话就容易编写和维护它们了。
- 上述代码即使是在一个超大型文件目录中也能工作的很好。事实上,由于使用了迭代方式处理,代码运行过程中只需要很小很小的内存。
yield from
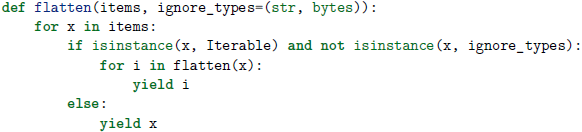
若想将一个多层嵌套的序列展开成一个单层列表,可使用yield from语句优雅地解决这个问题。
yield from 在你想要从生成器中调用其他生成器作为子例程的时候非常有用,如果不使用它的话就必须写额外的繁琐的 for 循环了(其实,yield from 在涉及到基于协程和生成器的并发编程中扮演着更加重要的角色):

虽然只改了一点点,但显然
yield from更简洁。
装饰器
概念
装饰器语法只是一种语法糖。
decorator(装饰器) 是一种返回值为另一个函数的函数,通常使用@wrapper 语法形式来进行函数变换。
需要强调的是装饰器并不会修改原始函数的参数签名以及返回值。
一个函数定义可以被一个或多个 decorator 表达式所包装,当函数被定义时将在包含该函数定义的作用域中对装饰器表达式求值,求值结果必须是一个可调用对象,它会以该函数对象作为唯一参数被发起调用。
示例 1
@f1(arg) @f2 def func(): passdef func: pass func = f1(arg)(f2(func))示例 2
@timethis def countdown(n): passdef countdown(n): pass countdown = timethis(countdown)示例 3
class A: @classmethod def method(cls): passclass A: def method(cls): pass method = classmethod(method)
内置的装饰器比如@staticmethod, @classmethod, @property 等原理也是一样的。
用装饰器可给被包装函数增加额外的参数,且不影响该函数现有的调用规则——这种用法并不常见,但它确实可以避免一些重复代码。
from functools import wraps
def optional_debug(func):
@wraps(func)
def wrapper(*args, debug=False, **kwargs):
if debug:
print('Calling', func.__name__)
return func(*args, **kwargs)
return wrapper
@optional_debug
def spam(a, b, c):
print(a, b, c)
# 1 2 3
spam(1, 2, 3)
# Calling spam
# 1 2 3
spam(1, 2, 3, debug=True)
# 精确的程序可能发现被包装函数的签名其实是错误的,还可以做一些修改自定义装饰器:@wraps
任何时候你定义装饰器的时候,都应该使用 functools 库中的@wraps装饰器来注解底层包装函数,以防止该函数的重要元信息如名字、文档字符串、注解和参数签名等丢失:
定义一个装饰器,在内部对将要被包装的函数使用
@wraps(func)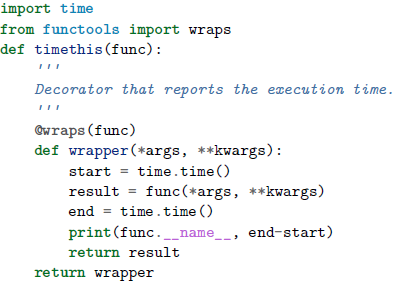
使用内部带
@wraps的装饰器
使用了
@wraps的被包装函数的元信息不变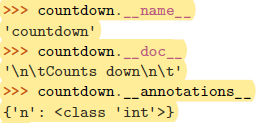
未使用
@wraps的被包装函数的元信息丢失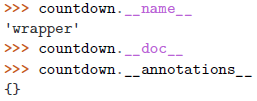
@wraps的重要特征就是它能让你通过属性__wrapped__直接访问被包装函数,也就是说通过__wrapped__可以直接解除装饰器>>> countdown.__wrapped__(100000) >>> >>> @somedecorator >>> def add(x, y): ... return x + y ... >>> orig_add = add.__wrapped__ >>> orig_add(3, 4) 7 >>>
关于__wrapped__:
通过
__wrapped__解除装饰器的时候如果有多个装饰器,那么访问__wrapped__属性的行为是不可预知的,应该避免这样做。另外值得一提的是,并不是所有的装饰器都使用了
@wraps,因此__wrapped__解除装饰器的方案并不全部适用,特别地,内置的装饰器@staticmethod和@classmethod就没有遵循这个约定,它们把原始函数存储在属性__func__中。
自定义装饰器:在类中
在类中定义装饰器,可实现为实例方法或类方法:
在类中定义装饰器有个难理解的地方就是对于额外参数 self 或 cls 的正确使用:尽管最外层的装饰器函数比如 decorator1() 或 decorator2() 需要提供一个 self 或 cls 参数,但是在两个装饰器内部被创建的 wrapper() 函数并不需要包含这个 self 参数。你唯一需要这个参数是在你确实要访问包装器中这个实例的某些部分的时候,其他情况下都不用去管它。
from functools import wraps
class A:
# Decorator as an instance method
def decorator1(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
print('Decorator 1')
return func(*args, **kwargs)
return wrapper
# Decorator as a class method
@classmethod
def decorator2(cls, func):
@wraps(func)
def wrapper(*args, **kwargs):
print('Decorator 2')
return func(*args, **kwargs)
return wrapper
# As an instance method
a = A()
@a.decorator1
def spam():
pass
# As a class method
@A.decorator2
def grok():
pass类里面定义的装饰器在涉及到继承的时候若要在子类中调用父类的装饰器,需要显式地使用父类的名字去调用它,而不能用子类的名称去调用,因为在方法被定义时子类还未被创建。
class B(A):
@A.decorator2
def bar(self):
pass在类中使用装饰器时,若对同一个方法还要同时使用@classmethod 或 @staticmethod,要确保你要使用的装饰器放在@classmethod 或 @staticmethod 之后!
原因在于
@classmethod, @staticmethod实际上不创建可直接调用的对象,而是创建特殊的描述器对象。
| 代码定义 | 说明 |
|---|---|
 | 一个自定义装饰器 |
  | 装饰后的类和静态方法可正确工作,只不过增加了额外的计时功能: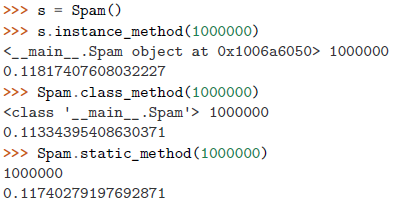 |
 | 如果顺序写错了就会出错: 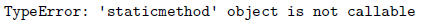 |
自定义装饰器:装饰器类
装饰器也可以定义为一个类,但要确保它实现了__call__()和__get__()方法:
import types
from functools import wraps
class Profiled:
def __init__(self, func):
# functools.wraps()函数的作用跟之前还是一样,将被包装函数的元信息复制到可调用实例中去
wraps(func)(self)
self.ncalls = 0
def __call__(self, *args, **kwargs):
self.ncalls += 1
return self.__wrapped__(*args, **kwargs)
def __get__(self, instance, cls):
if instance is None:
return self
else:
return types.MethodType(self, instance)
# 直接把@Profiled当作普通的装饰器使用即可
@Profiled
def add(x, y):
return x + y
# 直接把@Profiled当作普通的装饰器使用即可
class Spam:
@Profiled
def bar(self, x):
print(self, x)
@property 装饰器实际上是一个类,它里面定义了三个方法 getter(), setter(), deleter(),每一个方法都是一个装饰器:

类装饰器
类也可以被装饰,就像装饰函数一样。将一个装饰器扣在一个类定义的头上,即是一个类装饰器:
def log_getattribute(cls):
# Get the original implementation
orig_getattribute = cls.__getattribute__
# Make a new definition
def new_getattribute(self, name):
print('getting', name)
return orig_getattribute(self, name)
# Attach to the class and return
cls.__getattribute__ = new_getattribute
return cls
# Example use
# 以下即叫作“类装饰器”,它重写了特殊方法__getattribute__()
@log_gettribute
class A:
def __init__(self, x):
self.x = x
def spam(self):
pass
a = A(42)
a.x
# getting: x
# 42
a.spam()
# getting: spam类装饰器通常可以用作其他高级技术如混入或元类的一种非常简洁的替代方案,它可以扩充类的功能。某种程度上,类装饰器显得更加直观,并且它不会引入新的继承体系,运行速度也更快一些,因为它不依赖super()函数。
如果你想在一个类上面使用多个类装饰器,那么就需要注意下顺序问题。例如,一个装饰器 A 会将其装饰的方法完整替换成另一种实现,而另一个装饰器 B 只是简单地在其装饰的方法中添加些额外逻辑,那么装饰器 A 就需要放在装饰器 B 的前面。
描述器
概念
一般来讲,一个描述器(descriptor) 是一个包含“绑定行为”的对象,对其属性的存取会被你定义的描述器协议中的方法覆盖,这些方法有__get__(), __set__() 和 __delete__()。换句话说,如果某个对象中定义了这些方法中的任意一个,这个对象就可以被称为一个描述器。
重新提醒一下,Python 中把跟在一个点号之后的名称都称为属性。
属性访问的默认行为是从一个对象的字典中获取、设置或删除属性。例如,a.x 的查找顺序会从a.__dict__['x']开始,然后是type(a).__dict__['x'],接下来依次查找 type(a)的基类,不包括元类。如果找到的值是定义了某个描述器方法的对象,则 Python 可能会重载默认行为并转而调用描述器方法,这具体发生在优先级链的哪个环节则要根据所定义的描述器方法及其被调用的方式来决定。
描述器协议:
| 描述器协议 |
|---|
descr.__get__(self, obj, type=None) -> value |
descr.__set__(self, obj, value) -> None |
descr.__delete__(self, obj) -> None |
- 如果一个对象只定义了
__get__(),就称之为 non-data descriptor(非数据型描述器,自译); - 如果一个对象定义了
__set__()或__delete__(),就称之为 data descriptor(数据型描述器,自译)。 - Data and non-data descriptors differ in how overrides are calculated with respect to entries in an instance’s dictionary. If an instance’s dictionary has an entry with the same name as a data descriptor, the data descriptor takes precedence. If an instance’s dictionary has an entry with the same name as a non-data descriptor, the dictionary entry takes precedence.
- 如果要定义一个只读的 data descriptor,就同时定义
__get__()和__set__(),并让__set__()被调用时引发AttributeError异常。
事实上,Python 的 properties, bound methods, static methods, class methods 等都是基于描述器协议实现的技术。
描述器示例:
class RevealAccess (object):
"""A data descriptor that sets and returns values
normally and prints a message logging their access.
"""
def __init__(self, initval=None, name='var'):
self.val = initval
self.name = name
def __get__(self, obj, objtype):
print('Retrieving', self.name)
return self.val
def __set__(self, obj, val):
print('Updating', self.name)
self.val = val
class MyClass(object):
x = RevealAccess(10, 'var "x"')
y = 5
>>> m = MyClass()
>>> m.x
Retrieving var "x"
10
>>> m.x = 20
Updating var "x"
>>> m.x
Retrieving var "x"
20
>>> m.y
5调用描述器
描述器可以通过其方法名称直接调用,如
descr.__get__(obj),或者通过属性访问的方式引发调用;描述器是通过
__getattribute__()方法被引发调用的,覆盖__getattribute__()方法会阻止描述器的自动调用;object.__getattribute__()和type.__getattribute__()对__get__()协议的调用不同;data descriptors 总是会覆盖实例底层的字典(instance dictionarires)
non-data descriptors 可能会被实例字典所覆盖
自定义描述器
构造描述器最简洁的方法是使用 property():
property(fget=None, fset=None, fdel=None, doc=None) -> property attributeproperty的一种典型使用方法:class C(object): def getx(self): return self.__x def setx(self, value): self.__x = value def delx(self): del self.__x x = property(getx, setx, delx, "I'm the 'x' property.")property()的纯 python 实现等价如下(貌似实际中它是用 C 实现的):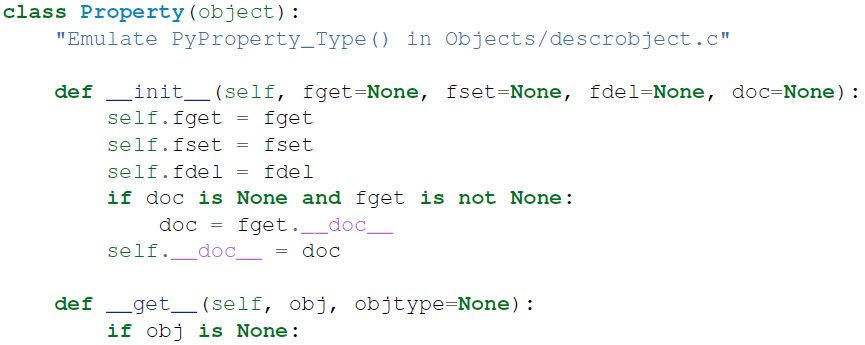

实际上,Python 的面向对象特性是基于函数的,是 non-data descriptor 将两者无缝地衔接起来。
类字典把方法存放为函数,在类定义中,方法像函数一样由 def 或 lambda 来定义,不同之处仅在于方法的第一个参数是为对象实例所保留的,通常写作 self;
为了支持方法调用,函数包含了
__get__()用作属性访问时的绑定方法,这意味着所有的函数都是 non-data descriptor,用于当他们被对象调用时返回其绑定的方法,这个原理用纯 Python 语言可描述如下:class Function(object): # ... def __get__(self, obj, objtype=None): "Simulate func_descr_get() in Objects/funcobject.c" if obj is None: return self return types.MethodType(self, obj)如下示意了“函数描述器”在实践中是如何工作的:
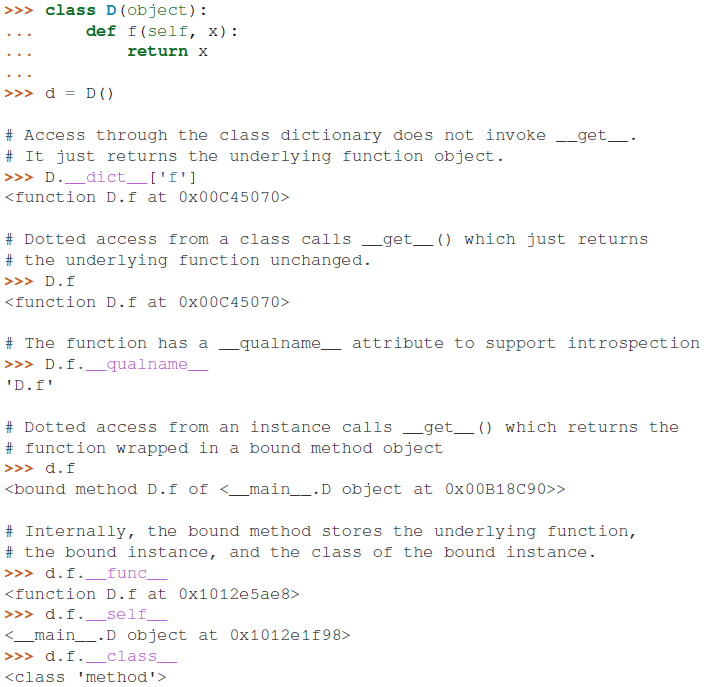
来自 Python Cookbook
作为输入,描述器的每一个方法会接收一个操作实例。为了实现请求操作,会相应地操作实例底层的字典(
__dict__属性)。描述器的self.name属性存储了在实例字典中被实际使用到的key。当一个描述器被放入一个类的定义时,每次访问属性时它的
__get__(), __set__(), __delete__()方法不会被触发。不过,如果一个描述器仅仅只定义了一个__get__()方法的话,它比通常的具有更弱的绑定,只有当被访问属性不在实例底层的字典中时__get__()方法才会被触发。描述器可实现大部分 Python 类特性中的底层魔法,包括
@classmethod,@staticmethod,@property,甚至__slots__特性。通过定义一个描述器,你可以在底层捕获核心的实例操作(get, set, delete),并且可完全自定义它们的行为,这是一个强大的工具,有了它你可以实现很多高级功能,并且它也是很多高级库和框架中的重要工具之一。最后指出,如果你只想简单地定义某个类的单个属性访问,不用去写描述器,使用
property技术会更加容易。当程序中有很多重复代码的时候描述器就很有用了。定义一个描述器


描述器的一个比较困惑的地方是它只能在类级别被定义,而不能为每个实例单独定义。

为了使用一个描述器,需将这个描述器的实例作为属性放到一个类的定义中。
这样做后,所有对描述器属性(如 x 或 y)的访问会被
__get__(), __set__(), __delete__()方法捕获到。

更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于e18f8-于076c4-于