字符串
1. 概述
Python中的字符串不能被修改,它们是immutable的。
字符串中的回车换行会自动包含到字符串中,如果不想包含,在行尾添加一个
\即可。print("""\ Usage: thingy [OPTIONS] -h Display this usage message -H hostname Hostname to connect to """)相邻的两个或多个字符串字面值(引号引起来的字符)将会自动连接到一起:
>>> 'Py' 'thon' 'Python' >>> text = ('Put several strings within parentheses ' ... 'to have them joined together.') >>> text 'Put several strings within parentheses to have them joined together.'对于字符串
s = 'adlkfjpeoqwiuf', 使用list(a)或set(a)可将其转换为单个字符构成的列表或集合。
2. print输出
print()函数输出多个变量时,会在参数项之间插入一个空格,以便格式化。
此外其还有一个end关键字参数,可控制每次调用print()函数输出完后的额外“结束操作”(默认不是输出一个换行符嘛)。
>>> i = 256*256
>>> print('The value of i is', i)
The value of i is 65536
>>> a, b = 0, 1
>>> while a < 1000:
... print(a, end=',')
... a, b = b, a+b
...
0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,3. 字符串的加法、乘法、比较
字符串加法运算即为字符串连接:
last_name = 'Carlsson' first_name = 'Johanna' full_name = first_name + ' ' + last_name # 'Johanna Carlsson'乘法是重复的加法:
game = 2 * 'Yo' # 'YoYo'当比较字符串时,使用的是字符顺序,同一字母的排序其大写形式优于其小写形式
'Anna' > 'Arvi' # False 'ANNA' < 'anna' # True '10B' < '11A' # True
4. 字符串连接
当我们使用加号
+操作符去连接大量的字符串时效率是非常低的,因为+连接会引起内存复制以及垃圾回收操作。特别的,永远都不应像下面这样写字符串连接代码:
这种写法会比使用
join()方法慢一些,因为每一次执行+=操作的时候会创建一个新的字符串对象。最好是先收集所有的字符串片段然后再将它们连接起来,一个相对聪明的技巧是利用生成器表达式转换数据为字符串的同时合并字符串:
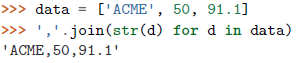
另外,注意不必要的字符串连接操作,不要多此一举:

5. str() 与 repr() 函数
两者都可将非字符串值表示为字符串;
str()函数用于返回人类可读的值的表示,repr()函数用于生成解释器可读的表示(如果没有等效的语法会强制执行SyntaxError);对于没有人类可读性表示的对象,
str()将返回和repr()一样的值;很多值使用任一函数都具有相同的表示,比如数字或类似列表和字典的结构,特殊的是字符串有两个不同的表示。

6. 字符串的方法
操作型
| 方法 | 作用 |
|---|---|
title() | 将串内每个单词的首字母都大写 |
Upper() | 将串内全部字母大写 |
lower() | 将串内全部字母小写 |
rstrip() | 剔除字符串右端的空白,返回副本 |
lstrip() | 剔除字符串左端的空白,返回副本 |
strip() | 同时剔除字符串两端空白,返回副本 |
split([, ';']) | 以空格或指定的字符(如;)为分隔符,将字符串分拆成多个部分,并以一个列表形式返回 |
join(iterable) | 将iterable中的元素以所用字符串为分界符连接起来 |
find() | 返回字符串所匹配的第一个索引值,即给定搜索子串的起始位置 |
startswith(…) | 检查字符串是否以…开头,若希望有多种匹配,传入一个元组(regex固然也可以实现,但有点大材小用了) |
endswith(…) | 检查字符串是否以…结尾,若希望有多种匹配,传入一个元组(regex固然也可以实现,但有点大材小用了) |
replace() | 搜索字符串中的匹配项以替换 |
translate() | 审查清理文本字符串 |


格式化型
str.format(): 格式化字符串course_code = 'NUMA21' "This course's name is {}".format(course_code) # "This course's name is NUMA21" num = 33.45 "{:f}".format(num) # 33.450000 "{:1.1f}".format(num) # 33.5 "{:.2e}".format(num) # 3.35e+01 "{name} {value: .1f}".format(name='num', value=num) # "num 33.5"format方法扫描字符串以便发现占位符,这些占位符是用大括号{}括起来的。这些占位符以其中所定义的格式说明符的形式被替换,其中格式说明符以:作为其前缀来表示。- 对于有多个占位符,将需要插入的对象名作为参数放入占位符中。
- 一个字符串中可能包含一对大括号,此视其不应被视为
format方法的点位符。在这种情况下要使用双括号。
以下的这些对齐方法都能接受一个可选的填充字符
str.rjust(): 通过在左侧填充空格来对给定宽度的字段中的字符串进行右对齐
str.ljust(): 左对齐

str.center(): 居中对齐str.zfill(): 在数字数字串的左边填充零,它能识别正负号
7. 字符串格式化输出
类C语言的
%格式化>>> "Hello, %s." % "world" # %s 表示字符串 'Hello, world.' >>> "Hello, %s. Pi is %f" % ("world", 3.14) # %f 表示符点数 'Hello, world. Pi is 3.140000' >>> "Hello, %s. Pi is %1.2f" % ("world", 3.14) # %1.2f 指定打印的数字位数 'Hello, world. Pi is 3.14'控制符 说明 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %u 格式化无符号整型 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化浮点数字,可指定小数点后的精度 %e 用科学计数法格式化浮点数 %E 作用同%e,用科学计数法格式化浮点数 %g %f和%e的简写 %G %F 和 %E 的简写 %p 用十六进制数格式化变量的地址 * 定义宽度或者小数点精度 - 用做左对齐 + 在正数前面显示加号( + ) <sp> 在正数前面显示空格 # 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') 0 显示的数字前面填充'0'而不是默认的空格 % '%%'输出一个单一的'%' (var) 映射变量(字典参数) m.n. m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) 使用格式化字符串字面值:在字符串的开始引号之前加上一个
f或F,在此字符串中,可以在{}括号内直接插入引用的变量或字面值的python表达式
字符串的
str.format()方法类上操作

使用
<, >, ^字符后面紧跟一个指定的宽度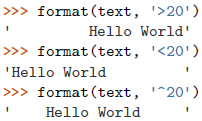
若想指定一个非空格的填充字符,将它写到对齐字符的前面即可

format()函数的一个好处是它不仅适用于字符串,还可以用来格式化任何值,故非常通用,如左的格式化数字
当格式化多个值的时候,这些格式代码也可以被用在
format()方法中:
8. 字节字符串
字节字符串同样也支持大部分和文本字符串一样的操作:
内置操作
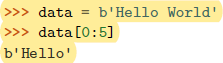
切片

正则表达式匹配:不过正则表达式本身必须也是字节串
需强调的是:
字节字符串的索引操作返回整数而不是单独字符

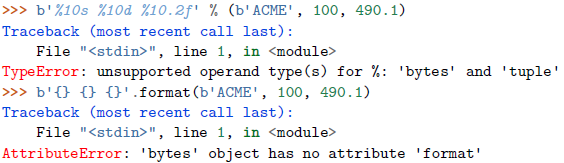
字节字符串不会提供一个美观的字符串表示,也不能很好地打打印出来,除非它们先被解码为文本字符串

也不存在任何适用于字节字符串的格式化操作
如果希望这样做,须先使用标准的文本字符串再编码字字节字符串
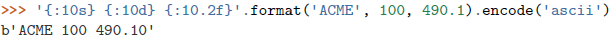
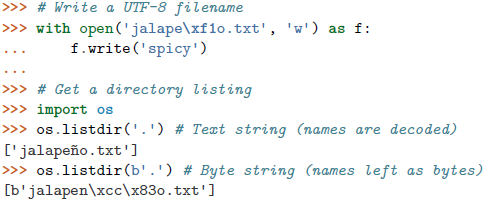
使用字节字符串可能会改变一些操作的语义,特别是那些跟文件系统有关的操作
最后提一点,一些程序员为了提升程序执行的速度会倾向于使用字节字符串而不是文本字符串,这样做通常会导致非常杂乱的代码。坦白讲,如果你在处理文本的话,就直接在程序中使用普通的文本字符串而不是字节字符串吧,不作死就不会死!
字节串可用普通字符串的.encode()方法获得,同时字节串的.decode()方法可将其解码回普通字符串:
>>> s = "hello"
>>> sb = s.encode()
>>> sb
b'hello'
>>> sb.decode()
'hello'
>>> type(s)
<class 'str'>
>>> type(sb)
<class 'bytes'>更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于e18f8-于8ff00-于