模块与包
模块、包、库
模块(module) :一个.py 文件就是一个 module。模块可以包含可执行语句以及函数定义,这些语句用于初始化模块,它们仅在模块第一次在 import 语句中被导入时才执行(当文件被当作脚本运行时,它们也会执行)。
包(package) :包是一个有层次的文件目录结构,它定义了由 n 个模块或 n 个子包组成的 python 应用程序执行环境。通俗一点说,包是一个包含
__init__.py文件的目录(文件夹),该目录下有一个__init__.py文件和其他模块或子包。库(lib) :不同于模块与包,是一个抽象概念,它是参考其它编程语言的一种说法,就是指 python 中完成一定功能的代码集合,在 python 中可理解为是包和模块的抽象说法。只要你喜欢,什么都可以是 lib。
在 python 中,模块的使用方式都是一样的,但细说的话,模块可以分为四个通用类别:
- 使用 python 编写的.py 文件
- 已被编译为共享库或 DLL 的 C 或 C++扩展
- 把一系列模块组织到一起的文件夹(文件夹下有一个
__init__.py文件,该文件夹称之为包) - 使用 C 编写并链接到 python 解释器的内置模块
在一个模块内部,模块名(作为一个字符串)可以通过全局变量__name__的值获得。
脚本与模块
- 编写好的一个 python 文件可以有两种用途:
- 脚本:一个文件就是整个程序,用来被执行
- 模块:文件中存放着一堆功能,用来被导入使用
- python 为我们内置了全局变量
__name__:- 当文件被当作脚本执行时,
__name__等于'__main__' - 当文件被当作模块导入时,
__name__等于模块名
- 当文件被当作脚本执行时,
- 用来控制.py 文件在不同的应用场景下执行不同的逻辑的语句:
if __name__ == '__main__':
导入语句
出于效率的考虑,每个模块在每个解释器会话中只被导入一次,因此如果你更改了模块,想要以更改后的模块为准,则必须重新启动解释器,或者使用
importlib.reload().当使用
from package import item时,item可以是包的子模块(或子包),也可以是包中定义的其他名称,如函数,类或变量。import语句首先测试是否在包中定义item;如果没有,它假定它是一个模块并尝试加载它。如果找不到它,则引发ImportError异常。相反,当使用
import item.subitem.subsubitem这样的语法时,除了最后一项之外的每一项都必须是一个包;最后一项可以是模块或包,但不能是前一项中定义的类或函数或变量。
当一个名为 spam 的模块被导入的时候,解释器首先寻找具有该名称的内置模块,如果没有找到,解释器从 sys.path 变量给出的目录列表里寻找名为 spam.py 的文件,sys.path 初始有这些目录地址:
- 包含输入脚本的目录(或未指定文件时的当前目录);
- PYTHONPATH(一个包含目录名称的列表,它和 shell 变量 PATH 有一样的语法);
- 取决于安装的默认设置。
对于 from module import *语句:
若什么也不做,将导入所有不以下划线开头的;
在模块中定义一个
__all__变量可以明确指出通过from _导出的内容,此时使用from module import _将只导入__all__列表列举出的内容;若
__all__定义成一个空列表,将没有东西被导入,如果__all__包含未定义的名字,在导入时将引起AttributeError。
“编译过的”python 文件
为了加速模块载入,Python 在
__pycache__目录里缓存了每个模块的编译后版本,名称为 module.version.pyc,其中名称中的版本字段对编译文件的格式进行编码,它一般使用 python 版本号,此命名约定允许来自不同发行版和不同版本的 python 的已编译模块共存。python 根据编译版本检查源的修改缓存,以查看它是否已过期并需要重新编译,这是一个完全自动化的过程。此外,编译的模块与平台无关,因此可以在具有不同体系结构的系统之间共享相同的库。
python 在两种情况下不会检查缓存:首先,对于从命令行直接载入的模块,它从来都是重新编译并且不存储编译结果;其次,如果没有源模块,它不会检查缓存。为了支持无源文件(仅编译)发行版本,编译模块必须是在源目录下,并且绝对不能有源模块。
一个从.pyc 文件读出的程序并不会比它从.py 读出时运行的更快,.pyc 文件唯一快的地方在于载入速度。
compileall 模块可以为一个目录下的所有模块创建.pyc 文件。
包的绝对导入与相对导入
绝对导入: 以执行文件的 sys.path 为起始点开始导入,称之为绝对导入
- 优点: 执行文件与被导入的模块中都可以使用
- 缺点: 所有导入都是以 sys.path 为起始点,导入麻烦
相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入
符号:
.代表当前所在文件的文件夹,..代表上一级文件夹,...代表上一级的上一级文件夹优点: 导入更加简单
缺点: 只能在导入包中的模块时才能使用

如果模块 mypackage.A.spam 要导入同目录下的模块 grok:
# mypackage/A/spam.py from . import grok在包内,既可以使用相对路径也可以使用绝对路径导入:
# mypackage/A/spam.py from mypackage.A import grok # OK from . import grok # OK import grok # Error(not found)注意:
相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包
如果包的部分被作为脚本直接执行,它们将不起作用:
% python3 mypackage/A/spam.py # Relative imports fail如果使用 python 的-m 选项来执行先前的脚本,则相对导入将会正确运行:
% python3 -m mypackage.A.spam # Relative imports work
试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
延迟导入
对于一个很大的模块,可能你只想组件在需要时被加载,要做到这一点,__init__.py有细微的变化:

在这个版本中,类 A 和类 B 被替换为在第一次访问时加载所需的类的函数。对于用户,这看起来不会有太大的不同,如
>>> import mymodule >>> a = mymodule.A() >>> a.spam() A.spam()延迟加载的主要缺点是继承和类型检查可能会中断。如下,对于某些情况你可能需要稍微改变你的代码:
if instance(x, mymodule.A): # Error pass if instance(x, mymodule.a.A): # OK pass
运行目录
如果你的应用程序已经有多个文件,可以把你的应用程序放进它自己的目录并添加一个__main__.py文件。
例如,可以像这样创建目录:

如果
__main__.py存在,就可以简单地在顶级目录运行 python 解释器(如右)。解释器将执行__main__.py文件作为主程序:bash % python3 myapplication
读取位于包中的数据文件,在如下的目录结构中,假设 spam.py 文件需要读取 somedata.dat 文件中的内容,下述代码的 data 产生的变量是包含该文件的原始内容的字节字符串:


一个特别值得注意的模块sys,它被内嵌到每一个 python 解释器中,变量sys.ps1和sys.ps2定义用作主要和辅助提示的字符串:

__future__ 模块是一种伪模块,可被程序员用来启用与当前解释器不兼容的新语言特性:

封装成包
封装成包是很简单的。在文件系统上组织你的代码,并确保每个目录都定义了一个__init__.py文件。文件__init__.py的目的是要包含不同运行级别的包的可选的初始化代码,如
假设你执行了语句
import graphics,文件graphics/__init__.py将被导入,建立graphics命名空间的内容;假设执行了
import graphics.format.jpg这样的导入语句,文件graphics/__init__.py和文件graphics/formats/__init__.py将在文件graphics/formats/jpg.py导入之前导入。

相应的 import 语句:
import graphics.primitive.line from graphics.primitive import line import graphics.formats.jpg as jpg
绝大部分时候让__init__.py文件空着就好,但是有些时候可以包含代码。如,__init__.py能够用来自动加载子模块:

像这样一个文件,用户可以仅仅通过
import graphics.formats来代替import graphics.formats.jpg以及import graphics.formats.png语句。
其实,即使没有__init__.py文件存在,python 仍然会导入包。此时实际上创建了一个所谓的“包命名空间”。然而,如果你着手创建一个新的包的话,包含一个__init__.py文件吧。
包命名空间
从本质上讲,包命名空间是一种特殊的封装设计,其合并不同目录的代码到一个共同的命名空间。
对于大的框架,这可能是有用的,因为它允许一个框架的部分被单独地安装下载。它也使人们能够轻松地为这样的框架编写第三方附加组件和其他扩展。包命名空间的一个重要特点是任何人都可以用自己的代码来扩展命名空间。
包命名空间的关键是确保顶级目录中没有
__init__.py文件来作为共同的命名空间。缺失__init__.py文件使得在导入包的时候会发生有趣的事情:这并没有产生错误,解释器创建了一个由所有包含匹配包名的目录组成的列表。特殊的包命名空间模块被创建,只读的目录列表副本被存储在其__path__变量中。一个包是否被作为一个包命名空间的主要方法是检查其
__file__属性,如果没有,那么包就是个命名空间。
| 图片 | 说明 |
|---|---|
 | 在这 2 个目录里,都有着共同的命名空间 spam,但在任何一个目录里都没有__init__.py文件。 |
 | 两个不同的包目录被合并到一起,可以导入 spam.blah 和 spam.grok,并且它们可以工作。 |
 | 在定位包的子组件时,目录__path__将被用到。 |
 | 检查一个包是否被作为一个包命名空间。 |
包支持另一个特殊属性__path__ ,它被初始化为一个列表,其中包含在执行该文件中的代码之前保存包的文件__init__.py 的目录的名称。这个变量可以修改;这样做会影响将来对包中包含的模块和子包的搜索。
python 有一个用户安装目录,通常类似~/.local/lib/python3.3/site-packages,要强制在这个目录下安装包,可以使用安装选项--user如:
python3 setup.py install --user
# 或
pip install --user packagename在
sys.path中用户的site-packages目录位于系统的site-packages目录之前。因此,你安装在里面的包就比系统已安装的包优先级高(尽管并不总是这样,要取决于第三方包管理器,比如distribute或pip)。通常包会被安装到系统的
site-packages目录中去,路径类似/usr/local/lib/python3.3/site-packages。
虚拟环境
使用pyvenv命令可创建一个新的“虚拟”环境,这个环境被安装在 python 解释器同一目录,或 windows 上面的 Scripts 目录。
| 命令 | 说明 |
|---|---|
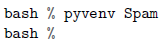 | 传给 pyvenv 命令的名字是将要被创建的目录名。 |
 | 当被创建后,spam 目录如左。 |
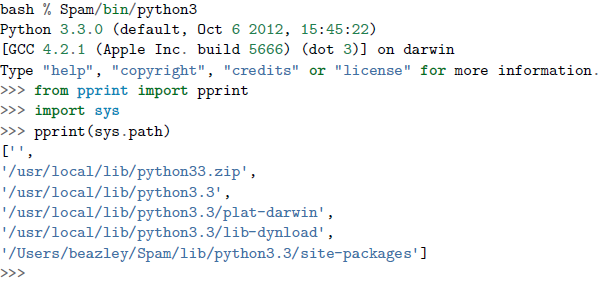 | 在 bin 目录中,你会找到一个可以使用的 python 解释器。这个解释器的特点就是他的 site-packages 目录被设置为新创建的环境,安装的第 三方包将会被安装在这里,而不是通常的 site-packages 目录。 |
有了一个新的虚拟环境,下一步就是安装一个包管理器,比如 distribute 或 pip。但安装这样的工具和包的时候,你需要确保你使用的是虚拟环境的解释器,它会将包安装到新创建的 site-packages 目录中去。
尽管一个虚拟环境看上去是 python 安装的一个复制,不过它实际上只包含了少量几个文件和一些符号链接。所有标准库函文件和可执行解释器都来自原来的 python 安装。因此,创建这样的环境是很容易的,且几乎不会消耗机器资源。
默认情况下,虚拟环境是空的,不包含任何额外的第三方库。若想将一个已经安装的包作为虚拟环境的一部分,可以使用
-system-site-packages选项来创建虚拟环境:
分发代码
如果你想分发你的代码:
第一件事就是给它一个唯一的名字,并且清理它的目录结构。一个典型的函数库包会如下:

要让你的包可以发布出去,要编写一个 setup.py,如下:
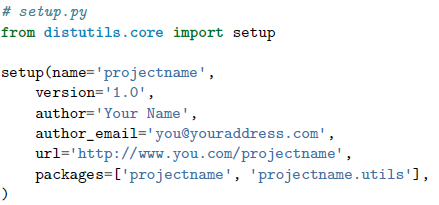
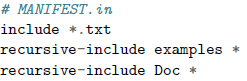
下一步是创建一个 MANIFEST.in 文件,列出所有在你的包中需要包含进来的非源码文件:
确保 setup.py 和 MANIFEST.in 文件放在你的包的最顶级目录中。至此你已经可以像下面这样执行命令来创建一个源码分发包了,它会创建一个文件如"projectname-1.0zip"或"projectname-1.0.tar.gz",具体依赖于你的系统平台。如果一切正常,这个文件就可以发送给别人使用或者上传至 Python Package Index.
%bash python3 setup.py sdist对于涉及到 C 扩展的代码打包与分发就更复杂点了。
更新日志
1f3d7-于899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于e18f8-于076c4-于