类
Python类的概念
基于类创建对象时,每个对象都自动具备这种通用行为,然后可根据需要赋予每个对象独特的个性。
根据类来创建对象被称为实例化,创建的对象叫做实例对象。实例对象的唯一操作是属性引用,有两种有效的属性名称:数据属性和方法。
数据属性对应于 C++中的数据成员;
方法是从属于对象的函数。
当一个类定义了__init__()方法时,类的实例化操作会自动为新创建的类实例发起调用__init__()。
用 C++术语来讲,python 中的类成员,包括数据成员,都是 public 的(私有变量除外),所有成员函数都是 virtual 的。
类定义与函数定义一样,必须被执行才会起作用。
实例属性和类属性
这里的属性其实概括了数据属性和方法......
在类声明中指定的属性称为类属性,类变量也可以被实例所访问,但其仅限在类的层级上修改,而不能在类的实例中修改。
另外,任何一个作为类属性的函数都为该类的实例定义了一个相应方法(这也就是为什么
@classmethod也可以用实例来访问的原因,猜的)。

给实例绑定属性的方法是通过实例变量,或者通过 self 变量:

值得注意的是,有时你不自觉地希望从实例中更改类属性,于是你写了那样的一个语句,但综合以上两点,其实你写的语句并不是在修改类属性,而只是创建了一个和类属性同名的实例属性!
特点:
从设计理念上来说,实例变量用于作为每个实例的唯一数据,而类变量用于类的所有实例共享的属性和方法。
相同名称的实例属性将屏蔽掉类属性;但将实例属性删除后可访问对应的类属性。

python 中没有任何东西能强制隐藏数据,它是完全基于约定的;不过,用 C 语言编写的 python 实现则可以隐藏实现细节,并在必要时控制对象的访问,此特性可以通过用 C 编写 python 扩展来使用。
彼此依赖的属性
一些属性之间彼此依赖,此时修改被依赖的属性时其相关属性不会自动更新。针对这种情况,可定义一个在属性更改时执行的方法。
方法
实例方法与类方法
在(实例)方法的定义中,形参
self必不可少,还必须位于其他形参的前面。每个与类相关联的方法调用都自动传递实参self,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。以
self为前缀的变量都可供类中的所有方法使用,我们还可以通过类的任何实例来访问这些变量。
函数定义的文本并非必须包含于类定义之内,将一个函数对象赋值给一个局部变量也是可以的,如:

一般方法通过使用第一个参数来引用一个实例,而类方法第一个参数是引用该类的本身。按照约定,第一个参数分别称为 self (用于标准方法) 和 cls (用于类方法)。另外,类方法需在其定义前加上@classmethod
一般方法
class A: def fun(self, *args): ...类方法
class B: def fun(cls, *args): ...
@clssmethod与@staticmethod
类中通常定义的方法是成员/实例方法,其特点是用self作为第一个参数,因为其和实例绑定;
在当类内的函数加上@classmethod装饰器时,定义的函数应该以cls为第一个参数,因为这是一个跟类绑定的函数,而非和实例绑定,因此称类方法;
由于类方法中引入了
cls参数,因此这个函数能轻松和类进行交互:访问类本身的属性以及类本身的方法。类方法在被继承之后,
cls自动指向的也是子类而非基类(来源网络,不过合情合理)。类方法的一个重要用途就是用作
__init__()之外的构造函数,因为Python的动态语言特性不允许重载函数(尽管可以用*args,**kwargs解决),这个功能实际就类似于C++中的重载。import time class Date: """方法一:使用类方法""" # Primary constructor sef __init__(self, year, month, day): self.year = year self.month = month self.day = day # Alternate constructor @classmethod def today(cls): t = time.localtime() return cls(t.tm_year, t.tm_mon, t.tm_mday) a = Date(2012, 12, 21) # Primary b = Date.today() # Alternate
有时我们需要一些方法,它们既和类相关,但又不需要引用类cls和实例self中的任何信息,即我们只想把一些好像类外部函数的功能定义到这个类中,此时就可以使用@staticmethod装饰器定义所谓的静态方法.
使用了@classmethod和@staticmethod的方法,既可以通过类的实例进行调用,又可以通过类名直接调用(他们都相当于跟类绑定的方法)。
方法调用特殊形式
使用内置的getattr()函数或者operator.methodcaller()函数可通过字符串形式的方法名称调用某个对象的对应方法。

使用
getattr()函数p = Point(2, 3) d = getattr(p, 'distance')(0, 0) # Calls p.distance(0, 0)使用
operator.methodcaller()函数import operator operator.methodcaller('distance', 0, 0)(p)当需要通过相同的参数多次调用某个方法时,使用
operator.methodcaller()函数就很方便了points = [ Point(1, 2), Point(3, 0), Point(10, -3), Point(-5, -7), Point(-1, 8), Point(3, 2) ] # Sort by distance from origin (0, 0) points.sort(key=operator.methodcaller('distance', 0, 0))
继承与封装
子类与父类
object是python中所有类的基类。可以创建object类的实例,但这些实例没什么实际用处,因为其没有任何有用的方法,也没有任何实例数据(因为它没有任何的实例字典,你甚至不能设置任何属性),用它们唯一能做的就是测试同一性:
_no_value = object()子类继承了其父类的所有属性和方法,同时还可以定义自己的属性和方法。
创建子类的实例时,Python 首先需要完成的任务是给父类的所有属性赋值。

创建子类时,父类必须包含在当前文件中,且位于子类前面。父类也称为超类(superclass),名称 super 因此而得名。
Python 3.x 和 Python 2.x 的一个区别就是 Python 3 可以直接使用
super().xxx代替super(Class, self).xxxPython 3.x 实例
class A: def add(self, x): y = x+1 print(y) class B(A): def add(self, x): super().add(x) b = B() b.add(2) # 3Python 2.x 实例
class A(object): # Python2.x 记得继承 object def add(self, x): y = x+1 print(y) class B(A): def add(self, x): super(B, self).add(x) b = B() b.add(2) # 3
对于派生类,如果请求的属性在类中找不到,搜索将转往基类中进行查找;如果基类本身也派生自其他某个类,则此规则将被递归地应用。
对于父类的方法,只要它不符合子类模拟的实物的行为,都可对其进行重写。为此,可在子类中定义一个这样的方法,即它与要重写的父类方法同名。这样,Python 将不会考虑这个父类方法,而只关注你在子类中定义的相应方法。
为了调用父类(超类)的一个方法,可以使用super()函数。
在
__init__()方法中确保父类被正确地初始化class A: def __init__(self): self.x = 0 class B(A): def __init__(self): super().__init__() self.y = 1调用父类(超类)的一个方法
class A: def spam(self): print('A.spam') class B(A): def spam(self): print('B.spam') super().spam() # Call parent spam()常常用来覆盖python特殊方法
class Proxy: def __init__(self, obj): self._obj = obj # Declare attribute lookup to internal obj def __getattr__(self, name): return getattr(self._obj, name) # Delegate attribute assignment def __setattr__(self, name, value): if name.startswith('_'): super().__setattr__(name, value) # Call original __setattr__ else: setattr(self._obj, name, value)
继承解析
python 有两个内置函数可被用于检查继承机制:
- 使用
isinstance()来检查一个实例的类型,isinstance(obj, int) - 使用
issubclass()来检查类的继承关系:issubclass(bool, int)
继承解析过程:
对于多数应用来说,在最简单的情况下,可以认为搜索从父类所继承属性的操作是深度优先、从左至右的,当层次结果中存在重叠时不会在同一个类中搜索两次;
真实情况实际上更复杂一些,方法解析顺序会动态改变以支持对
super()的协同调用;动态改变顺序是有必要的,因为所有多重继承的情况都会显示出一个或更多的菱形关联(即至少有一个父类可通过多条路径被最底层类所访问)。例如,所有类都是继承自
object,因此任何多重继承的情况都提供了一条以上的路径可以通向object。为了确保基类不会被访问一次以上,动态算法会用一种特殊方式将搜索顺序线性化,保留每个类所指定的从左至右的顺序,只调用每个父类一次,并且保持单调(即一个类可以被子类化而不影响其父类的优先顺序)。总而言之,这些特性使得设计具有多重继承的可靠且可扩展的类成为可能。
封装
Python程序员不依赖语言特性去封装数据,而是通过遵循一定的属性和方法命名规约来达到这个效果。
约定类内任何以单下划线
_开头的名字都应该是内部实现,这意思是“虽然我可以被访问,但是请把我视为私有变量,不要随意访问”。这个约定同样适应于模块名和模块级别函数。
class A: def __init__(self): self._internal = 0 # An internal attribute self.public = 1 # A public attribute def public_meth(self): pass def _internal_method(self): pass类内名字使用双下划线
__开始意为声明其是私有的,这会导致名称变成其他形式,从而使得这种属性或方法无法通过继承被覆盖,官方称作“名称改写”。这里私有的
__private和__private_method()会分别被重命名为_B__private和_B__private_method()class B: def __init__(self): self.__private = 0 def __private_method(self): pass def public_method(self): pass self.__private_method()这里,私有名称
__private和__private_method()分别被重命名为_C__private和_C__private_method(),故跟其父类B中的名称是不同的,不会导致覆盖。class C(B): def __init__(self): super().__init__() self.__private = 1 # Does not override B.__private # Does nott override B.__private_method() def __private_methd(self): pass
在python中,变量名类似
__xxx__的,也就是以双下划线开头和结尾的,是特殊变量,特殊变量可以直接访问,它们不是private变量,但是请不要随意把你的变量名定义成这种形式。
大多数而言,应该让你的非公共名称以单下划线开头。但是若你清楚你的代码会涉及到子类,并且有些内容属性或方法在子类中应该被隐藏,那么才应考虑使用双下划线方案。
有时你定义的一个变量可能会和某个保留关键字冲突,这时候可使用单下划线作为后缀:
lambda_ = 2.0 # Trailing _ to avoid clash with lambda keyword其他
假设你写了很多仅仅用作数据结构的类,而不想写太多烦人的__init__()函数,可以选择在一个基类中写一个公用的__init__()函数,然后让其他类继承自这个基类,这可以大大简化代码。
import math
class Structure1:
# Class variable that specifies expected fields
_fields = []
def __init__(self, *args):
if len(args) != len(self._fields):
raise TypeError('Expected {} arguments'.format(len(self._fields)))
# Set the arguments
for name, value in zip(self._fields, args):
setattr(self, name, value)
# Example class definitions
class Stock(Structure1):
_fields = ['name', 'shares', 'price']
class Point(Structure1):
_fields = ['x', 'y']
class Circle(Structure1):
_fields = ['radius']
def area(self):
return math.pi * self.radius ** 2类的特殊方法
对于类的特殊方法名称,太多太重要了,一定要看官方文档!!!
Python类中的__XXX__()方法就是所谓的魔术方法(magic method) ,也叫特殊方法(special method) 。
__slots__
当你定义的某些类主要是用来当作简单的数据结构的时候,考虑给类添加__slots__属性来极大地减少实例所占内存。(slot: n.机会;窄缝 v.投放;插入;(被)塞进)
class Date:
__slots__ = ['year', 'month', 'day']
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day__slots__是一种写在类内部的声明,通过预先声明实例属性等对象并移除实例字典来节省内存。虽然这种技巧很流行,但想要用好却并不容易,最好是只保留在少数情况下采用,例如极耗内存的应用程序,并且其中包含大量实例。- 因为定义
__slots__后,python会为实例使用一种更加紧凑的内部表示,实例将通过一个很小的固定大小的数组来构建(跟元组或列表类似),而不是为每个实例分配一个字典。使用__slots__后节省的内存会跟存储属性的数量和类型有关,不过一般来讲使用的内存总量跟将数据存储在一个元组中差不多。 - 使用
__slots__的缺陷是我们不能再给实例添加新的属性了,只能使用在__slots__中定义的那些属性名;且定义了__slots__后的类不再支持一些普通类特性了,如多继承。 - 尽管
__slots__看上去很有用,很多时候你还是得减少对它的使用冲动。大多数情况下,你应该只在那些经常被使用到的用途数据结构的类上定义slots,比如在程序中需要创建某个类的几百万个实例对象。
__init__(), __new__()
类的构造器(初始化方法)
通常的
__init__()方法使用类方法(
@classmethod)import time class Date: """方法一:使用类方法""" # Primary constructor sef __init__(self, year, month, day): self.year = year self.month = month self.day = day # Alternate constructor @classmethod def today(cls): t = time.localtime() return cls(t.tm_year, t.tm_mon, t.tm_mday) a = Date(2012, 12, 21) # Primary b = Date.today() # Alternate可以通过
__new__()方法创建一个未初始化的实例。示例 说明 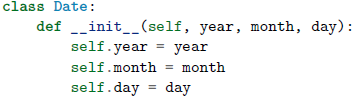
一个类的示例 

不调用 __init__()方法来创建这个Data实例
可见这个Data实例的属性还不存在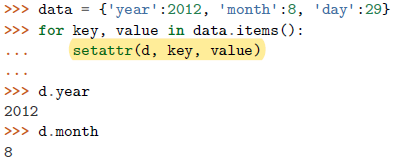
需手动初始化实例的属性
__str__(), __repr__()
要改变一个实例的字符串表示,可重新定义它的__str__()和__repr__()方法。
__repr__()方法返回一个实例的代码表示形式,通常用来重新构造这个实例,可通过内置的repr()函数返回这个字符串;__str__()方法将实例转换为一个字符串,可通过str()或print()函数输出这个字符串;如果__str__()没有被定义,那么就会使用__repr__()来代替输出。class Pair: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return 'Pair({0.x!r}, {0.y!r})'.format(self) def __str__(self): return '({0.x!s}, {0.!s})'.format(self) >>> p = Pair(3, 4) >>> p Pair(3, 4) # __repr__() output >>> print(p) (3, 4) # __str__() output!r格式化代码指明输出使用__repr__()来代替默认的__str__()- 格式化代码
{0.x}对应的是第1个参数的x属性,因此0实际上指的是self本身。
__len__(), __getitem__(), __add__()
__len__()方法:使得类实例支持len()函数操作;
__getitem__()方法:使得类实例支持索引操作;
__add__()方法:使得类实例支持加法操作。
from collections import namedtuple
allcards = namedtuple('allcards', ['ranks', 'color'])
class Poker(object):
numberRanks = [str(card) for card in range(2, 11)]
charRanks = list('JQKA')
allRanks = numberRanks + charRanks
colors = 'heart spade diamond club'.split()
jokes = 'red black'.split()
def __init__(self):
self.cards = [allcards(r, s) for r in self.allRranks for s in self.colors] + [allcards('joke', s) for s in self.jokes]
def __len__(self):
return len(self.cards)
def __getitem__(self, p):
return self.cards[p]
def __add__(self, other):
return self.cards + list(other)
mycard = Poker()
print(f"扑克牌的数量是 {len(mycard)} 张")
# 输出:扑克牌的数量是 54 张
print( list( i for i in mycard ))
# 输出:[allcards(ranks='2', color='heart'), allcards(ranks='2', color='spade'), … … allcards(ranks='joke', color='black')]
print(f"第5张牌是 {mycard[4]} ")
# 输出:第5张牌是 allcards(ranks='3', color='heart')
mycard2 = Poker()newcard = mycard + mycard2__enter__(), __exit__()
为了让一个对象兼容with语句(上下文管理协议),需要实现__enter__()和__exit__()方法。
编写上下文管理器的主要原理是你的代码会放到with语句块中执行:
- 当出现
with语句时,对象的__enter__()方法被触发,它返回的值(若有的话)会被赋值给as声明的变量; - 然后,
with语句块里面的代码开始执行; - 最后
__exit__()方法被触发进行清理工作。
不管with代码块中发生什么,上面的控制流都会执行完,即使代码块中发生了异常。
事实上,__exit__()方法的第三个参数包含了异常类型、异常值和追溯信息(若有的话),__exit__()方法能自己决定怎样利用这个异常信息,或者忽略它并返回一个None值。如果__exit__()返回True,异常会被清空,就像什么都没发生一样,with语句后面的程序继续正常执行。
from socket import socket, AF_INET, SOCK_STREAM
class LazyConnection:
"""
这个类的关键特点在于它表示了一个网络连接,但是初始化的时候并不会做任何事情(比如它并没有建立一个连接)。连接的建立和关闭是使用with语句自动完成的。
"""
def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
self.address = address
self.family = family
self.type = type
self.sock = None
def __entr__(self):
if self.sock is not None:
raise RuntimeError('Already connected')
self.sock = socket(self.family, self.type)
self.sock.connect(self.address)
return self.sock
def __exit__(self, exc_ty, exc_val, tb):
self.sock.close()
self.sock = Nonefrom functools import partial
conn = LazyConnection(('www.python.org', 80))
# Connection closed
with conn as s:
# conn.__enter__() executes: connection open
s.send(b'GET /index.html HTTP/1.0\r\n')
s.send(b'Host: www.python.org\r\n')
s.send(b'\r\n')
resp = b''.join(iter(partial(s.recv, 8192), b''))
# conn.__exit__() executes: connection closed类的比较
让类支持比较操作:
- Python类对每个比较操作都需要实现一个特殊方法来支持,如
>=操作的__ge__()方法。这样子定义一个方法没什么问题,但如果要实现所有的比较方法就比较烦人了。 - 装饰器
functools.total_ordering可以简化实现所有比较操作,你只需定义一个__eq__()方法,外加其他方法(__lt__, __le__, __gt__, __ge__)中的一个,然后装饰器会自动为你填充其它比较方法。
__call__()
__call__()方法让类的实例的行为表现得像函数一样,允许一个类的实例像函数一样被调用。
class A(): # 一个定义了def __call__(self, …)方法的类
…
a = A() # 创建实例
a(*args) # 实例可以像函数那样执行,这等价于执行a.__call__(*args)方法由此,用类的实例后面加上括号()即等同于调用实例的__call__()方法。
混入类
当需要实现“对某些实例属性的赋值进行类型检查”的功能时:
- 使用描述器:所有描述器类都是基于混入类来实现的。混入类的一个比较难理解的地方是,调用
super()函数时,并不知道究竟要调用哪个具体的类,你需要跟其他类结合后才能正确地使用。 - 使用类装饰器
- 所有方法中,类装饰器方案应该是最灵活和最高明的。它不依赖任何其他技术,比如元类,且可以很容易地添加和删除。
- 装饰器方式要比之前的混入类方式几乎快100%。
- 使用元类
混入类似乎叫Mixin类(《Python Cookbook》8.18节)
混入类不能直接被实例化
混入类没有自己的状态信息,也就是说它们并没有定义
__init__()方法,并且没有实例属性。这也是为什么经常在其中明确定义__slots = ()还有一种实现混入类的方式是使用类装饰器
抽象基类:ABC
鸭子编程
duck-typing(鸭子编程) :指一种编程风格,它并不依靠查找对象类型来确定其是否具有正确的接口,而是直接调用或使用其方法或属性(“看起来像鸭子,叫起来也像鸭子,那么肯定就是鸭子”)。
由于强调接口而非特定类型,设计良好的代码可通过允许多态替代来提升灵活性。
鸭子类型避免使用 type() 或 isinstance() 检测, 而往往会采用 hasattr() 检测或是 EAFP编程(但要注意鸭子类型可以使用抽象基类作为补充)。
EAFP: “求原谅比求许可更容易”的英文缩写:
- 这种Python 常用代码编写风格会假定所需的键或属性存在,并在假定错误时捕获异常。
- 这种简洁快速风格的特点就是大量运用try 和except 语句。
- 于其相对的则是所谓 LBYL风格,常见于C 等许多其他语言。
ABC
abstract base class(抽象基类, ABC) ,是对 duck-typing 的补充,它提供了一种定义接口的新方式,相比之下其他技巧如hasattr()显得过于笨拙或有微妙错误(如使用magic method)。
- 你可以使用
abc模块来创建自己的ABC。 collections模块也定义了很多抽象基类,当你想自定义容器类的时候它们会非常有用。比如如果你想让你的类支持迭代,那么让你的类继承collections.Iterable即可,不过你需要实现collections.Iterable所有的抽象方法,否则会报错。
ABC引入了虚拟子类,这种类并非继承自其他类,但却仍能被isinstance()和issubclass()所认可,详见abc模块官方文档。
Python 自带许多内置的 ABC 用于实现:
- 数据结构:在
collections.abc模块中 - 数字:在
numbers模块中 - 流:在
io模块中 - 导入查找器和加载器:在
importlib.abc模块中
ABC不能被直接实例化,其目的就是让别的类继承它并实现特定的抽象方法。ABC的一个主要用途是在代码中检查某些类是否为特定类型,它帮助实现了特定接口。
定义ABC
from abc import ABCMeta, abstractmethod class IStream(metaclass=ABCMeta): @abstractmethod def read(self, maxbytes=-1): pass @abstractmethod def write(self, data): passABC不能直接被实例化
# TypeError: Can't instantiate abstract class # ISteam with abstract methods read, write a = IStream()继承
class SocketStream(IStream): def read(self, maxbytes=-1): pass def write(self, data): pass检查类型
def serialize(obj, stream): if not isintance(stream, IStream): raise TypeError('Expected an IStream') pass
设计模式
代理是一种设计模式,它将某个操作转移给另外一个对象来实现。如下是一个简单的代理形式(关于代理更多的内容还得以后再看):
class A:
def spam(self, x):
pass
def foo(self):
pass
class B1:
"""简单的代理"""
def __init__(self):
self._a = A()
def spam(self, x):
# Delegate to the internal self._a instance
return self._a.spam(x)
def foo(self):
# Delegate to the internal self._a instance
return self._a.foo()
def bar(self):
pass状态模式是一种设计模式。如果代码中出现太多的条件判断语句,代码就会变得难以维护和阅读,一种解决方案是将每个状态抽取出来定义成一个类。
  |  |  |  |   |
|---|
访问者模式(???,8.21节)的一个缺点就是它严重依赖递归,如果数据结构嵌套层次太深可能会出问题。不过有时候可用生成器和协程实现非递归模式的算法版本。
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于a51c1-于0e6a3-于29df4-于4693e-于e18f8-于076c4-于8ff00-于