容器类
1. 列表
Python内置的列表虽然名为列表,但其实更类似于其他语言中的数组而非链接列表,因为其访问元素的时间复杂度为O(1)。在列表的末尾添加和弹出元素非常快,但是在列表的开头插入或弹出元素却很慢,因为所有的其他元素都必须移动一位。
将列表命名为复数形式、遍历时使用单数形式有助于代码可读性:
for cat in cats:
pass
for dog in dogs:
pass
for item in list_of_items:
pass列表切片
列表切片
L[i:j]为左闭右开区间;所有的切片操作都返回一个包含所请求元素的新列表,这意味着以下切片操作会返回列表的一个浅拷贝:
>>> squares[:] [1, 4, 9, 16, 25] # 浅拷贝
列表的加法和乘法
列表之间没有算术运算,对于希望进行元素之间的求和或乘除等运算,应使用数组;
列表用加号
+连接表示列表的合并(右合并至左末尾);# 加法不同于.append()和.extend() >>> m = [1, 2, 3] >>> m + ['abc'] [1, 2, 3, 'abc'] >>> m # 返回的是新对象 [1, 2, 3]将列表与整数相乘,列表将重复自身几次:
>>> a = [[0]]*4 >>> a [[0], [0], [0], [0]] >>> a[0].append(1) >>> a [[0, 1], [0, 1], [0, 1], [0, 1]] >>> a[0] = 1 >>> a [1, [0, 1], [0, 1], [0, 1]] >>> a[1] = 2 >>> a [1, 2, [0, 1], [0, 1]]>>> b = [0]*4 >>> b [0, 0, 0, 0] >>> b[0] = 1 >>> b [1, 0, 0, 0]
列表推导式
[<expr> for <variable> in <iterable>][<expr> for <variable> in <iterable> if <condition>]
zip合并列表
可将两个初始列表的元素配对合并为一个新的列表,其结果是一个元组列表;
若两个列表长度不一,新列表将匹配较短的那个;
zip创建了一个特殊的可迭代对象,可通过list化将其转化为列表。ind = [0, 1, 2, 3, 4] color = ['red', 'green', 'blue', 'alpha'] list(zip(color, ind)) # [('red', 0), ('green', 1), ('blue', 2), ('alpha', 3)]
列表的方法
| 列表方法 | 说明 | 示例 |
|---|---|---|
append(x) | 在列表末尾添加元素 | .append('honda') |
extend(iterable) | 将某容器类型中的元素添加到列表末尾 (容器类型可为串、列表、元组、集合等) | .extend([1,2]) # […, 1, 2] .extend('abc') # […, 'a', 'b', 'c'] |
count(x) | 指定元素,返回其在列表中出现的次数 | .count('a') |
insert(i, x) | 插入,指定索引和值 | .insert(index, 'ducati') |
pop([i]) | 删除列表 末尾 / 指定索引位置 的元素 | .pop(3) |
clear() | 删除列表中所有的元素,相当于del a[:] | |
index(x[, start[, end]]) | 返回列表中第一个值为x的元素的从零开始的索引,可造参数start和end是切片符号,将限制搜索的范围 | |
remove(x) | 删除指定值的元素,指定值(若该值出现多次,只删除第一个) | .remove('yamaha') |
sort(key=None, reverse=False) | 对列表进行永久性排序 | .sort() .sort(reverse=True) |
reverse() | 永久性地修改列表元素的排列顺序 | .reverse() |
copy() | 返回列表的一个浅拷贝,相当于a[:] |
关于列表的语句或函数:
| 语句/函数 | 作用 | 示例 |
|---|---|---|
del | 删除列表元素,指定索引 | del motorcycles[0] |
in | 判断某值是否包含在列表中 | |
not in | 判断某值是否不包含在列表中 | |
sorted() | 对列表进行临时排序 | |
len() | 返回列表的长度 | |
min() | 返回列表最小值 | |
max() | 返回列表最大值 | |
sum() | 对列表元素求和 |
创建空列表对比
速度差异明显:
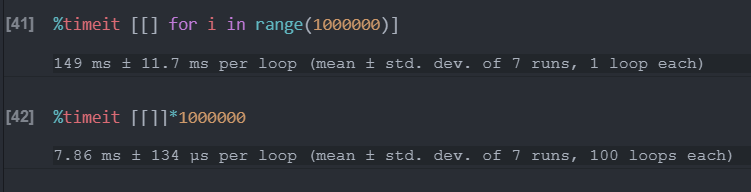
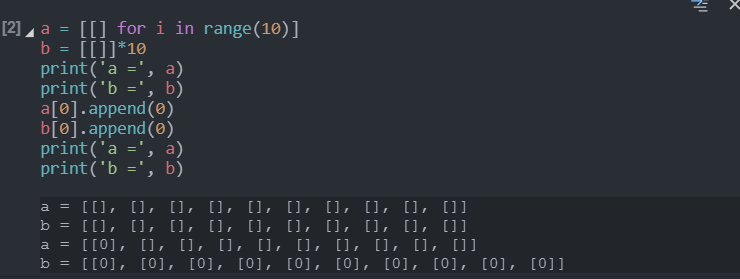
然而,重要的是,后一种创建方法会使得“同时赋值”,最终子列表互相之间完全相同!!
2. 元组
Python将不能修改的值称为 immutable (不可变的),而不可变的列表被称为元组(tupple) 。
相比于列表,元组是更简单的数据结构。
空元组可以直接被一对空圆括号创建,含有一个元素的元组可以通过在这个元素后添加一个逗号来构建(圆括号里只有一个值的话不够明确):
>>> empty = ()
>>> singleton = 'hello', # <-- note trailing comma
>>> len(empty)
0
>>> len(singleton)
1
>>> singleton
('hello',)交换技巧: a, b = b, a
a, b = b, a # (a, b) = (b, a)
1, 2 == 3, 4 # (1, False, 4)
(1, 2) == (3, 4) # False3. 字典
注意从Python 3.7开始,字典的遍历顺序一定和输入顺序一样。先前的版本并没有明确这一点,所以不同的实现可能不一致。
和list比较,dict有以下几个特点:
dict查找和插入的速度极快,不会随着key的增加而变慢;而list查找和插入的时间随着元素的增加而增加。
dict需要占用大量的内存,内存浪费多;而list占用空间小,浪费内存很少。
字典的创建
使用一对空的花括号
{}定义一个空字典dict()函数可以直接从键值对序列里创建字典
字典推导式可以从任意的键值表达式中创建字典

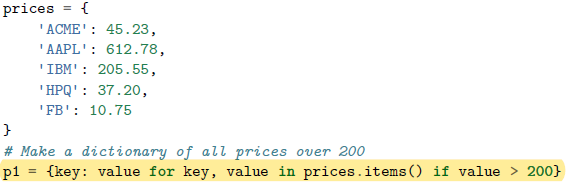
虽然大多数情况下字典推导能做到的,通过创建一个元组序列然后把它传给
dict()函数也能实现,但是字典推导方式表意更清晰,且实际运行也更快些:
当关键字是简单字符串时,通过直接关键字参数来指定键值对更方便:

字典是一种动态结构,可随时在其中添加键-值对。
每当需要在字典中将一个键关联到多个值时,都可以在字典中嵌套一个列表;或选择
collections模块中的defaultdict
字典的方法
items():遍历字典中的键-值对,返回一个包含(键,值) 对的元素视图对象。这个对象同样也支持集合操作,并且可以被用来查找两个字典有哪些相同的键值对。keys():遍历字典中的键,返回一个展现键集合的键视图对象。键视图的一个很少被了解的特性就是它们也支持集合操作,比如集合并、交、差运算。values():遍历字典中的值。尽管字典的values()方法返回的对象也是类似,但是它并不支持这里介绍的集合操作,因为值视图不能保证所有的值互不相同。
字典的遍历
字典是以关键字为索引的,关键字可以是任意 immutable 类型。
对一个字典执行list(d)将返回包含该字典中所有键的列表,按插入次序排序。
按顺序遍历字典中的键:
for name in sorted(favorite_languages.keys()):
print(name.title() + ", thank you for taking the poll.")字典的运算
以一个字典为例:
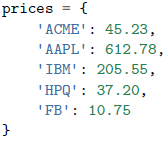
如果在一个字典上执行普通的数学运算,你会发现它们仅仅作用于键,而不是值 :
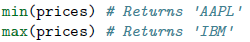
若想对值进行操作的同时知道对应的键的信息,当然可以在
min()和max()函数中提供key函数参数来提取对应键的信息
对字典值执行计算操作——使用
zip()函数先将键和值反转过来:
使用
zip()和sorted()函数来排列字典数据:
为了寻找两个字典的相同点,可以简单的在两字典的keys()或者items()方法的返回结果上执行集合操作(一个字典就是一个键集合与值集合的映射关系):

4. 集合
一个元素只能在集合中出现一次;集合是无序的。
Python 集合能够包含所有类型的可哈希对象,即数值对象、字符串和布尔值等。
创建集合
空集合:
set()一个空集不能由
{}来定义(其将返回空字典),而应由empty_set = set()来定义的。推导式形式:

集合的方法
""" A = {1,2,3,4} B = {5} """ C = A.union(B) # C = A∪B D = A.intersection(C) # D = A∩C E = C.difference(A) # E = C\A 5 in C # 5 ∈ C
union(): 求并集A.union(B) # A, B本身不变intersection(): 求交集A.intersection(C) # A, C本身不变difference(): 求差集C.difference(A) # A, C本身不变issubset(): 判断是否是子集{2, 4}.issubset({1,2,3,4,5}) # Trueissuperset(): 判断是否是子集{1,2,3,4,5}.issuperset({2,4}) # Trueadd(): 判断是否是子集{1,2,3}.add('abc') # {1, 2, 3, 'abc'}update(): 传入参数为 iterable,将其拆解合并{1,2,3}.update('abc') # {1,2,3,'a','b','c'} {1,2,3}.update(456) # TypeErrorremove(): (永久)删除某个元素,若该元素不存在,报错{1,2,3}.remove(1) # {2,3} {1,2,3}.remove(4) # Error删除整个集合:
del s # 直接删除整个集合,s 为某集合名
集合运算

5. 解压序列
序列解压的概念
任何的序列(或者是可迭代对象),如列表、元组、字符串、文件对象、迭代器、生成器等,可以通过一个简单的赋值语句解压并赋值给多个变量,唯一的前提就是变量的数量必须跟序列的元素的数量是一样的。
| 示例 | 具体值 |
|---|---|
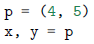 | 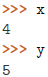 |
 | 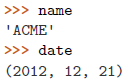 |
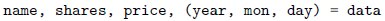 | 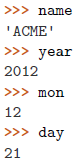 |
 | 有时候你可能只想解压一部分而丢弃其他的值,这时候可以使用任意变量名去占位,到时候丢掉这些变量就行了。 |
有时候,你想解压一些元素然后丢弃它们,可以使用一些普通的废弃名称,比如 *_ 或 *ign(ignore)。
星号表达式
python 的星号表达式可以使得用较少的变量名解压出全部的变量。
*操作符可从列表或元组中解包参数,而**操作符则可解包字典来得到关键字参数:

值得注意的是
*解压出来的 phone_numbers 变量永远都是列表类型,即使为空列表:示例 说明 
phone_numbers 变量永远都是列表类型,即使为空列表。 
*表达式也可用在开始部分星号表达式在解压迭代元素为可变长元组的序列时是很有用的:
records = [ ('foo', 1, 2), ('bar', 'hello'), ('foo', 3, 4), ] def do_foo(x, y): print('foo', x, y) def do_bar(s): print('bar', s) for tag, *args in records: if tag == 'foo': do_foo(*args) elif tag == 'bar': do_bar(*args)
6. 一些序列操作
slice()
内置的slice()函数创建了一个切片对象,可以被用在任何切片允许使用的地方。对于一个切片对象 a,可以调用它的 a.start, a.stop, a.step 属性获取更多信息。


另外切片的 indices(size)方法将它映射到一个确定大小的序列上,这个方法返回一个三元组(start, stop, step),所以的值都会被合适的缩放以满足边界限制。
>>> s = 'HelloWorld'
>>> a.indices(len(s))
(5, 10, 2)
>>> for i in range(*a.indices(len(s))):
... print(s[i])
...
w
r
d
>>>sorted()
内置的 sorted()函数有一个关键字参数 key,可以传入一个 callable 对象给它,这个 callable 对象对每个传入的对象返回一个值,这个值会被 sorted 用来排序这些对象。
class User:
def __init__(self, user_id):
self.user_id = user_id
def __repr__(self):
return 'User({})'.format(self.user_id)
def sort_notcompare():
users = [User(23), User(3), User(99)]
print(users)
print(sorted(users, key=lambda u: u.user_id))filter()
对一个序列进行元素过滤
简单情况可使用“列表推导”或“生成器表达式”(生成器表达式非常节省内存)
示例 说明 
使用列表推导 
使用生成器表达式 复杂情况,可将过滤代码过入一个函数中,然后使用内置的
filter函数,filter()创建了一个迭代器values = ['1', '2', '-3', '-', '4', 'N/A', '5'] def is_int(val): try: x = int(val) return True except ValueError: return False ivals = list(filter(is_int, values)) print(ivals) # Outputs ['1', '2', '-3', '4', '5']
另外一个值得关注的过滤工具是itertools.compress(),当需要用另外一个相关联的序列来过滤某序列的时候它非常有用。其以一个 iterable 对象和一个相对应的 Boolean 选择器序列作为输入参数,然后输出 iterable 对象中对应选择器为 True 的元素。
 |  |
|---|
去重
保持序列元素顺序的同时消除重复的值:
若序列上的值都是
hashable类型:def dedupe(items): seen = set() for item in items: if item not in seen: yield item seen.add(item) a = [1, 5, 2, 1, 9, 1, 5, 10] list(dedupe(a)) # [1, 5, 2, 9, 10]若序列上的值不可哈希:
# 这里的key参数指定了一个函数,将序列元素转换成hashable类型。 def dedupe(items, key=None): seen = set() for item in items: val = item if key is Not else key(item) if item not in seen: yield item seen.add(item) a = [{'x':1, 'y':2}, {'x':1, 'y':3}, {'x':1, 'y':2}, {'x':2, 'y':4}] list(dedupe(a, key=lambda d: (d['x', d['y']]))) # {'x':1, 'y':2}, {'x':1, 'y':3}, {'x':2, 'y':4}] list(dedupe(a, key=lambda d: d['x'])) # {'x':1, 'y':2}, {'x':2, 'y':4}]
更新日志
899db-于eedbf-于47fa5-于c9215-于75141-于730b3-于0e6a3-于29df4-于e18f8-于076c4-于8ff00-于